前阵子我们公司搞全链路去中心化备份,有个经常合作的海外服务商跟我瞎扯,说现在分布式算力和去中心化AI数据赛道缺一个能把流动性彻底盘活的底层。
我当时一边在终端里敲着 sudo apt-get update,一边就在琢磨,我们机房里那些闲置的冷存储硬盘和跑不慢的带宽,天天在那儿白白耗电,要是能把这些数据吞吐和模型调优的节点流动性变现,那不是直接躺赚?结果今天一翻社区,@OpenLedger 宣传的核心特点,居然完美撞在了我的专业枪口上。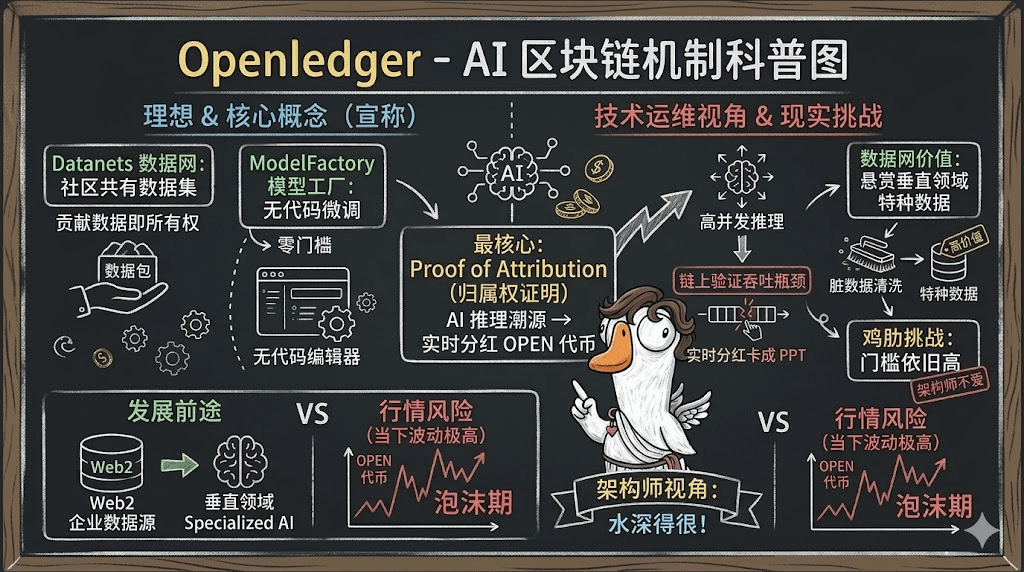
Openledger给自己贴的标签叫AI区块链,主打一个解锁流动性并实现数据变现
他宣传的核心逻辑有这么几个:第一是所谓的Datanets(数据网),也就是让社区共同拥有数据集,谁上传数据谁就拥有所有权;第二是ModelFactory(模型工厂),号称能无代码微调模型;最核心的一个叫Proof of Attribution(归属权证明),也就是AI只要用了你的数据或者模型去回答问题,你就能实时拿到$OPEN 代币的分红。
听起来是不是特别闭环,连我都差点被他的概念给唬住了?
但我用我做运维架构的死脑筋去深度调研和体验了一下,发现这事情有好也有坏,里面的水深着呢。#OpenLedger
先说他宣传得最天花乱坠的Proof of Attribution
Openledger说每次AI推理都能追踪到源头,给贡献者发钱。卧槽,真的是理想很丰满,现实很骨感。从技术细节来看,每次AI请求都要在链上做一次全归属权验证,这得要多恐怖的吞吐量?目前的公链哪怕是Layer 2,在高并发的AI推理面前也得卡成PPT。我太清楚高并发的痛苦了,如果Openledger没办法在底层解决这个性能瓶颈,这个所谓的实时分红最后只会变成一堆卡死在队列里的无效交易。这种机制,最后大概率会变成垃圾数据复读机的狂欢,谁刷量多谁拿奖励。
不过,抛开这种空中楼阁的激励机制,Openledger的数据网概念其实有他独特的独到之处,这也是通过我的职业才琢磨出来的细节。在搞企业级大数据时,我们最怕的就是“脏数据”和“通用废话”,因为清洗成本高得吓人。现在的AI大模型懂得挺多,但遇到各行各业的底层架构问题就抓瞎。Openledger搞的Datanets,实际上是在用代币经济学去悬赏各行各业的特种数据。#BTC
他OPENLEDGER如果真能把垂直领域的专家数据整合起来,去训练那些专注垂直领域的小型语言模型,那价值绝对比现在那些只会写公文的通用AI高得多。这一点,确实是很多只懂写代码的普通程序员不太会注意到的行业痛点。
至于那个ModelFactory,说是什么零门槛无代码微调
我进去体验了一下,感觉有点鸡肋。这玩意对真正的AI开发者和我们这种搞架构的人来说太简陋,对完全不懂代码的圈外人来说又太硬核。搞得就像我给客户开放了一个没有命令行界面的空壳服务器,然后跟客户说你现在也是顶尖系统架构师了,这不扯淡吗?工具再简单,调参的逻辑和对数据的清洗依然需要专业门槛。#ETHETFS 
这两天我盯着Openledger的表现,心里也是一万只草泥马奔腾
眼看着$OPEN 代币的行情上上下下,我媳妇过来问我晚饭吃啥,我正心不在焉地在看他的热议和K线。
最后咱们清醒地讨论一下Openledger的行情和未来发展。现在市场上打着AI旗号的区块链项目多如牛毛,Openledger现在的热度,很大程度上是靠着Balaji还有EigenLabs这些技术大佬背书强撑起来的。他到底能不能成,取决于他能不能真的跨界吸引到Web2的真实数据源,而不是天天在Web3圈子里内卷。
如果Openledger最后变成了一群老韭菜用AI生成的垃圾文章互相刷分、骗取OPEN代币的工具,那他很快就会走向死亡。行情来看,现在的$OPEN 代币波动极大,投机属性拉满,妥妥的泡沫期。我自己反正就当是个观察样本,拿着极小的仓位在里面折腾,绝不轻易重仓。毕竟,在机房里待久了就知道,系统吹得越牛逼,宕机的时候往往哭得越惨,大家还是保持清醒,看他后续的数据网到底能不能产出真正有用的 specialized AI 吧。