

the last few weeks staring at the intersection of decentralization and artificial intelligence, trying to cut through the absolute mountain of noise. If you’ve been floating around the Web3 space lately, you know exactly what I mean. Every second project is slapping an “AI” sticker on a basic smart contract, riding the narrative wave, and hoping nobody looks under the hood. It’s exhausting. But then, you stumble upon something like OpenLedger (OPEN), and the cynical tech writer in me stops scrolling.
Look, I’m not here to give you a hyped-up marketing pitch or a shallow breakdown of a token that’s going to "moon." I want to talk about infrastructure, philosophy, and economic reality. When I look at OpenLedger, I don't see another fleeting "AI narrative." For me, what’s fascinating here is the sheer audacity of what they are trying to engineer: a foundational, decentralized economic layer designed specifically for the AI era.
We are living through a strange pivotal moment. Right now, artificial intelligence is experiencing a hyper-centralized gold rush. The massive, closed-source tech giants are vacuuming up the world’s data, training monolithic models behind closed doors, and capturing 100% of the economic value. If you provide the data, you get nothing. If you build an open-source model, you struggle for compute funding. OpenLedger feels like a direct, deeply philosophical counterweight to this monopoly. It’s an attempt to take data, computational models, and autonomous AI agents, and transform them into verifiable, liquid, and financialized assets within a decentralized ecosystem.
Let's break down how this works, intellectually and structurally, because if they pull this off, the way we perceive data and machine intelligence changes completely.
The Liquidity of Human Knowledge
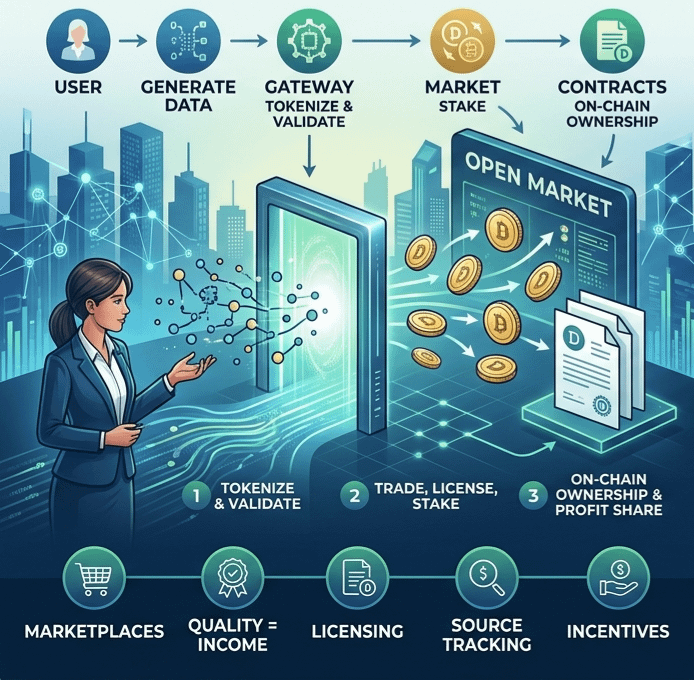
Historically, data has been a strangely rigid asset. For the average creator, user, or specialized professional, data is something you generate passively and surrender immediately. Big Tech stores it in siloed servers, exploits it, and leaves the actual creators out of the financial loop. For me, the most profound shift OpenLedger introduces is what they call the Data Liquidity Layer.
The core idea here is beautiful: transforming data from a stagnant file into a dynamic, priceable economic asset. Instead of just storing information, the protocol aims to build active marketplaces where data can be dynamically valued, staked, and licensed directly to AI models. When you link the quality of data directly to a financial yield, the entire incentive structure of the internet shifts.
Naturally, this isn't an easy road. The immediate roadblocks that come to my mind are the sheer volume of fraudulent data, the systemic difficulty of objectively pricing information, and the deep-seated monopolies already held by corporate titans. If a marketplace is flooded with low-quality, AI-generated garbage data, the system collapses. To fix this, OpenLedger isn't relying on central curators. Instead, they are implementing cryptographic reputation systems for data contributors, backed by decentralized validators who check for structural integrity and relevance. By introducing dynamic pricing based on actual algorithmic utility, they create a self-correcting market.
This naturally bleeds into the philosophy of true Data Ownership. I believe that for Web3 to mature, ownership cannot just mean holding a speculative token in a browser extension; it must mean owning the digital footprint of your mind. OpenLedger attempts to anchor data ownership directly on-chain. This means clear, unalterable usage rights, documented metadata, and smart contracts that ensure you receive a slice of the profits whenever an AI model is trained using your inputs. And critically, it introduces the right to opt-out—the ability to revoke a license.
To bridge ownership and liquidity, you need a mechanism to measure reality, which brings us to their Proof of Contribution framework. How do you actually know who improved a model? In the real world, tracking the exact impact of a specific dataset on a neural network's final output is a notoriously complex mathematical problem. If you get it wrong, the system gets hit by Sybil attacks and endless spam contributions from bad actors looking to game the rewards. OpenLedger's approach involves building native AI scoring systems coupled with reputation layers and stake-based validation. If your data legitimately sharpens a model's accuracy, the proof is recorded, your reputation score climbs, and your reward is mathematically secured.
The Birth of the Sovereign Agent
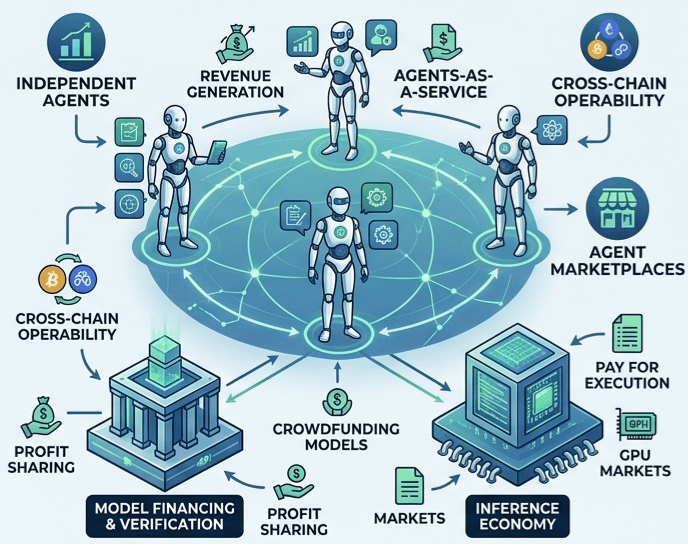
Now, if we look past the raw data layer, we hit the section of this ecosystem that honestly blows my mind: the autonomous AI Agent Economy.
Look around us right now. The AI agents we use are essentially highly sophisticated puppets tethered to corporate APIs. They don't own bank accounts, they don't make independent economic decisions, and they cannot transact across borders without human intervention. OpenLedger looks at this and asks: What happens if we treat AI agents as sovereign economic entities?
I find this concept utterly captivating. In this ecosystem, an agent isn't just software; it's an independent revenue-generating business. We are talking about an "Agents-as-a-Service" framework operating natively across multiple blockchain networks. An agent can charge fees for its specialized services, pay other agents to execute micro-tasks, and access decentralized marketplaces to upgrade its own capabilities.
But let’s be real for a moment—the darker side of this is terrifying if left unchecked. Rogue agents, conflicting economic interests, and massive resource consumption could easily break a network. If an autonomous agent starts behaving maliciously or hogging bandwidth, who holds it accountable? OpenLedger’s architecture introduces granular cryptographic permission systems, strict rate limits, and an independent Agent Reputation matrix. If an agent turns toxic or inefficient, its reputation tanks, its economic access is throttled, and the network naturally isolates it.
To make these agents reliable, however, they must be Verifiable Agents. One of the greatest anxieties we have with modern AI is the "black box" problem. You pass an input, you get an output, but the internal reasoning is completely obscured. If an economic agent mismanages funds or makes a catastrophic decision on-chain, humans need an audit trail. OpenLedger tackles this by engineering explainability layers and generating on-chain execution proofs. Every decision, every logic pivot, and every API call leaves a verifiable, immutable log. It turns the black box into a transparent pane of glass.
Democratizing the Machinery of Mind
If data is the fuel and agents are the output, the AI model itself is the engine. And building these engines is currently an elite game. The sheer financial cost of training a state-of-the-art foundation model is the single biggest barrier to entry, ensuring that only a handful of venture-backed corporations call the shots. This brings me to what OpenLedger calls Model Financing.
I deeply appreciate the ethos here. They are trying to democratize the capital layer of AI by introducing tokenized model crowdfunding and decentralized funding pools. Imagine a community coming together to fund an open-source medical AI model. By tokenizing the model, anyone can contribute to its development costs. In return, when developers or institutions pay to run inferences on that model, the revenue generated is automatically distributed back to the community that funded its birth. It aligns the financial incentives of open-source development with long-term, sustainable economic loops.
Of course, if you have a decentralized market for models, you run into a massive validation crisis. How can a buyer trust that a tokenized model actually performs as advertised? In the legacy tech world, we rely on centralized benchmarks, but these are notoriously easy to game; developers regularly over-optimize their models just to rank high on specific test sets.
OpenLedger solves this through a decentralized Validation Economy. They deploy independent validators who conduct randomized, continuous benchmarking, safety evaluations, and bias testing. Because these evaluations are decentralized and randomized, developers cannot pre-program their models to cheat the tests. It creates a transparent, public arena where models are judged solely on their live, unvarnished performance. If a validator catches a model underperforming or carrying malicious weights, economic penalties like slashing are applied, keeping the entire ecosystem fundamentally honest.
The Architecture: Compute, Cross-Chain, and Inferences
None of this philosophy means anything if the underlying infrastructure buckles under the weight of real-world demand. When you look at the technical blueprint of OpenLedger, you realize they aren't trying to lock themselves into a single, isolated blockchain ecosystem. They are building for a Cross-chain AI future.
For me, this is a pragmatic necessity. AI workloads are massive, and liquidity is notoriously fragmented across Web3. By ensuring native compatibility with the Ethereum Virtual Machine (EVM) and other major networks, OpenLedger allows AI assets, data, and models to deploy flexibly wherever the demand is highest. They bridge the asset layers while maintaining a unified verification standard, preventing the security vulnerabilities that typically plague fragmented, multi-chain designs.
Underneath this lies the raw physical reality of AI: computing power. You cannot run an AI economy without silicon, and right now, the global scramble for GPUs is a geopolitical bottleneck. OpenLedger integrates a Decentralized Compute layer, turning raw GPU power into a shared, global commodity. Anyone with compute resources can contribute them to the network, lowering operational costs and breaking the monopoly of centralized cloud providers.
But as someone who tracks distributed systems, I know that decentralized compute is incredibly messy. You have to deal with wildly varying hardware qualities, sudden network dropouts, and actors who try to fake their computational contributions. OpenLedger addresses this with rigorous Proof-of-Compute protocols and built-in redundancy mechanisms. If a node fails or attempts to provide fraudulent compute logs, the network dynamically re-routes the workload to a higher-scoring provider, ensuring seamless uptime.
This feeds directly into what they term the Inference Economy. Every time you ask an AI a question, that’s an inference, and it costs energy. In a decentralized setup, transaction fees can fluctuate wildly, and network congestion can ruin the user experience. OpenLedger counters this by decoupling the layers and utilizing Layer-2 scaling solutions combined with dynamic, demand-based pricing. It creates a stable, real-time market where users can pay for instant machine intelligence without being penalized by sudden network spikes.
Trust, Identity, and the Human Element
If you step back and look at the broader picture, you realize that an economy of data, models, and agents is fundamentally a trust network. Without a bulletproof way to measure identity and reputation, the entire construct dissolves into a chaotic sea of bots, sybils, and misinformation.
This is where the Reputation System and the Decentralized Identity (DID) layers become critical. In a world where anyone can spin up ten thousand virtual wallets, how do you protect the network from being overtaken by a single malicious actor? OpenLedger builds its trust layer on cryptographic staking and historical performance scoring. If you want to vote, contribute, or validate, you must put skin in the game.
To protect individual human privacy while maintaining this security, they leverage zero-knowledge proofs (ZKPs) within their identity stack. This allows contributors to prove their credentials, their human uniqueness, and their expertise without ever revealing their sensitive personal data.
Consider how vital this is when applied to Specialized Data Markets. If we want AI to revolutionize fields like decentralized medicine, finance, or heavy industry, we need a way to ingest highly sensitive, proprietary datasets. A hospital cannot just upload patient records to a public blockchain. By combining their identity layers with privacy-preserving technologies like Differential Privacy, OpenLedger allows specialized entities to monetize and share the abstract knowledge contained within their data without ever exposing the underlying raw, private details.
This is the foundation of what I consider a true Knowledge Economy. It re-frames human expertise as an elite, investable asset class. If a world-class doctor or an expert engineer curates a dataset or trains an AI agent, their unique knowledge is translated into structured data, signed with their decentralized identity, and permanently monetized. The source attribution is flawless, meaning the original thinker gets paid in perpetuity for the value their intellect provides to the machine.
Governance, Tokenomics, and the Long Road Ahead
At the heart of keeping this massive machine running smoothly is the OPEN token and its surrounding Tokenomics framework. I always look at utility tokens with a healthy dose of skepticism because so many of them exist purely for speculative trading. For OpenLedger to survive long-term, the token has to act as the literal lifeblood of the architecture. It must incentivize data providers, reward validators, facilitate staking, fuel inference payments, and govern the protocol.
The primary danger here is always economic sustainability—if the network relies purely on token emissions to survive, it will eventually succumb to inflation. To mitigate this, OpenLedger’s economic design focuses on cultivating genuine, structural demand, paired with systematic token-burn mechanisms tied to actual platform usage. It is designed so that as the real-world utility of the network scales, the token economy tightens.
This economic framework directly empowers the DAO Governance layer. Decisions regarding protocol upgrades, treasury allocations, and incentive adjustments aren't handed down by an executive board. Instead, they are decided by the community. To prevent the classic Web3 pitfall where a few wealthy "whales" control every outcome, OpenLedger implements advanced voting mechanisms like Quadratic Voting and reputation-weighted governance. Your influence isn't just a reflection of how deep your pockets are; it’s a reflection of how much constructive value you have consistently brought to the ecosystem over time.
When I look at how this all ties back into the open-source movement, it feels like the missing piece of the puzzle. Open-source AI projects have historically suffered from a tragic lack of sustainable funding, often getting co-opted or crushed by corporate giants. OpenLedger provides an open licensing economic framework, offering revenue-sharing structures and decentralized community grants that give open-source developers the financial runway they need to remain truly independent. It enables a seamless integration between Web3 and AI, where smart contracts become genuinely intelligent, and decentralized applications (dApps) can run natively autonomous agents in a secure, sandboxed environment.
A Final, Candid Reflection
Let’s step back and look at the horizon. The long-term vision of OpenLedger is nothing short of grand: an all-encompassing, self-sustaining AI economy designed to break the stranglehold of Big Tech and establish an unshakeable, decentralized layer of trust for artificial intelligence.
But if we are being completely honest with ourselves, the mountains they have to climb are absolutely massive. OpenLedger is operating on a bleeding-edge frontier, and its ultimate success isn't guaranteed by a brilliant whitepaper alone. They are entering an arena of ferocious competition from traditional tech behemoths who will not surrender their data moats easily. They must navigate a shifting labyrinth of global government regulations regarding data privacy and AI safety. And perhaps most importantly, they face the monumental task of achieving widespread, mainstream adoption while overcoming the inherent technical complexities of decentralized scaling.
For me, what makes OpenLedger profoundly different from the sea of copycat projects is its fundamental philosophy. It understands that the future of artificial intelligence shouldn't be confined to a single corporation's balance sheet, nor should it be reduced to a speculative crypto narrative. They are trying to build an ecosystem where data, models, and agents coexist as liquid, verifiable, and democratically governed assets.
Whether this vision achieves global scale depends entirely on the execution—how effectively the network can scale its infrastructure, how well it aligns its economic incentives, and whether it can generate authentic, long-term demand that extends far beyond the walls of crypto speculation. It is a bold, fascinating experiment, and it is precisely the kind of deep structural thinking our digital future desperately needs.
$OPEN #OpenLedger #openledger @OpenLedger
