
At first glance, OpenLedger’s Datanets looked like another AI-data marketplace narrative.
Upload data. Tokenize access. Distribute rewards.
Crypto has recycled versions of that structure for years.
But the more I looked at it, the less the dataset itself seemed to matter.
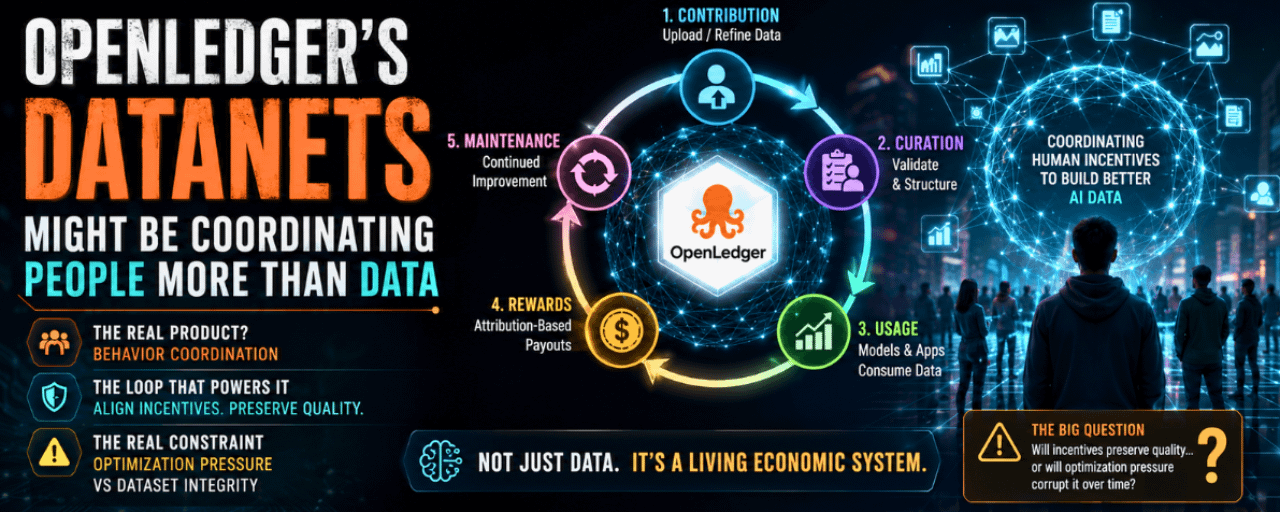
The real product might be behavior coordination.
Most AI systems still operate on a fairly static assumption about data. Someone gathers it, cleans it, trains a model, and the economic value gets captured mostly at the model layer afterward. The dataset is treated like raw material moving through a pipeline.
OpenLedger seems to be pushing a different idea entirely — that datasets can behave more like living economic systems.
That sounds abstract until you break the mechanism down.
Contributors upload or refine data. Curators validate and structure it. Smart contracts distribute rewards based on attribution logic and downstream usage. The system keeps looping as long as the dataset remains useful enough for models or applications to keep consuming it.
And that loop is probably the real product:
contribution → curation → usage → rewards → continued maintenance
What changes here is contributor behavior.
Normally, community datasets decay surprisingly fast because incentives disappear immediately after submission. People contribute once, maybe twice, then quality slowly collapses. Nobody has a reason to care whether labeling consistency survives six months later.
But if future usage continues generating rewards, contributors suddenly become economically tied to long-term dataset relevance instead of short-term participation.
That distinction feels small until you think about how AI systems actually fail in practice.
Most data quality problems emerge gradually and almost invisibly. A dataset can become massive while simultaneously becoming less useful. Edge cases stop getting updated. Labeling standards drift. Synthetic noise accumulates quietly over time.
We saw structurally similar problems in parts of DeFi during 2021–2023. Incentive systems designed to encourage participation often ended up rewarding extractive behavior instead of accuracy or sustainability. Different sector, same coordination problem.
And that’s where Datanets start becoming more interesting than “tokenized datasets.”
They begin looking like governance infrastructure for machine learning inputs.
The timing also matters.
A year ago, most AI-related crypto attention flowed toward model hype and consumer-facing integrations. Now the narrative rotation looks different. Liquidity has gradually shifted deeper into infrastructure layers — compute markets, inference routing, agent frameworks, provenance systems, ownership rails.
Infrastructure narratives tend to outperform during uncertainty because markets price coordination layers before end-user adoption arrives.
Datanets fit naturally into that transition because attribution is becoming economically important again.
Once models absorb data, contribution visibility disappears unless attribution is embedded directly into the system itself.
That broader shift is probably why ideas like OpenLedger feel more viable now than they would’ve during earlier AI cycles.
Still, the real constraint probably isn’t whether decentralized datasets can exist.
It’s whether optimization behavior stays below the threshold where reward extraction starts overwhelming dataset integrity.
Because crypto history suggests the same pattern almost every time:
the moment payouts become programmable, users optimize for payouts first.
If rewards depend on dataset usage metrics, those metrics will eventually get gamed. If curation is incentivized, low-quality approval loops become economically rational. If datasets evolve into community-owned assets, governance complexity expands fast once copyrighted or synthetic junk data enters the pipeline.
The system stops behaving like a simple data layer and starts behaving like a miniature economy.
That’s the part I keep circling back to.
OpenLedger’s Datanets make intuitive sense in a world where AI training data is no longer treated as infinitely disposable. Especially now that attribution and ownership conversations are getting louder across the industry.
But I still can’t tell whether token incentives genuinely preserve dataset quality over time…
or whether they slowly erode it the same way liquidity mining eventually distorted parts of DeFi once optimization pressure scaled.
Maybe community-owned AI datasets become a foundational infrastructure primitive for the next cycle.
Or maybe the economics only appear stable before scale introduces the exact behaviors the system was designed to prevent.
