

What kept pulling me back on OpenLedger was not Proof of Attribution itself.
Worse than that. Actually...
It was the way contributors start behaving before the attribution record exists at all.
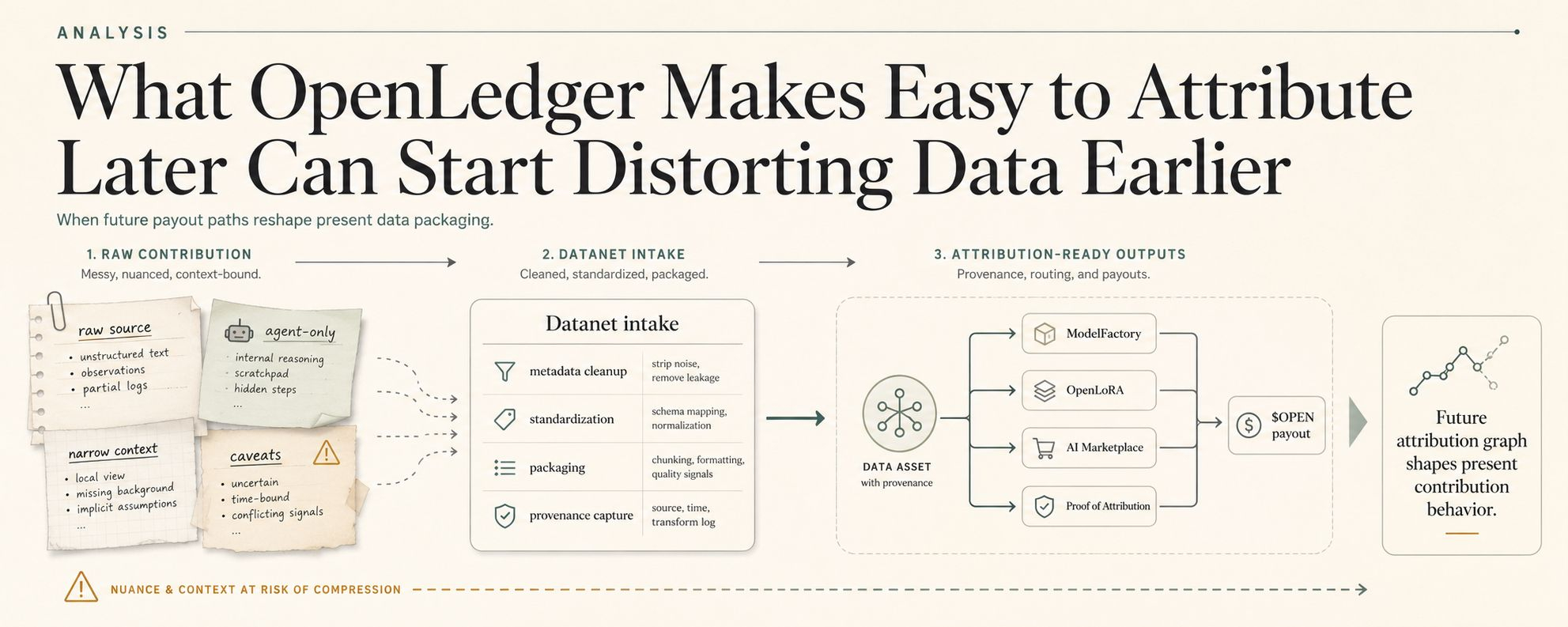
I do not think people say this part out loud enough. Once they know the data, adapter, model path, or agent output on OpenLedger is going to end up traceable later, queryable later, payable later through $OPEN flows, they start cleaning the contribution too early. Not the contribution, actually. The shape of it. Same bad instinct. You can watch it happen.
A messy source note becomes a Datanet tag.
A maybe-useful slice becomes “verified.”
A “good for this agent only” turns into something easier to route because nobody wants that caveat sitting there later under a provenance trail with payout logic attached.
And suddenly the future attribution graph is writing the present dataset.
That part bothers me.
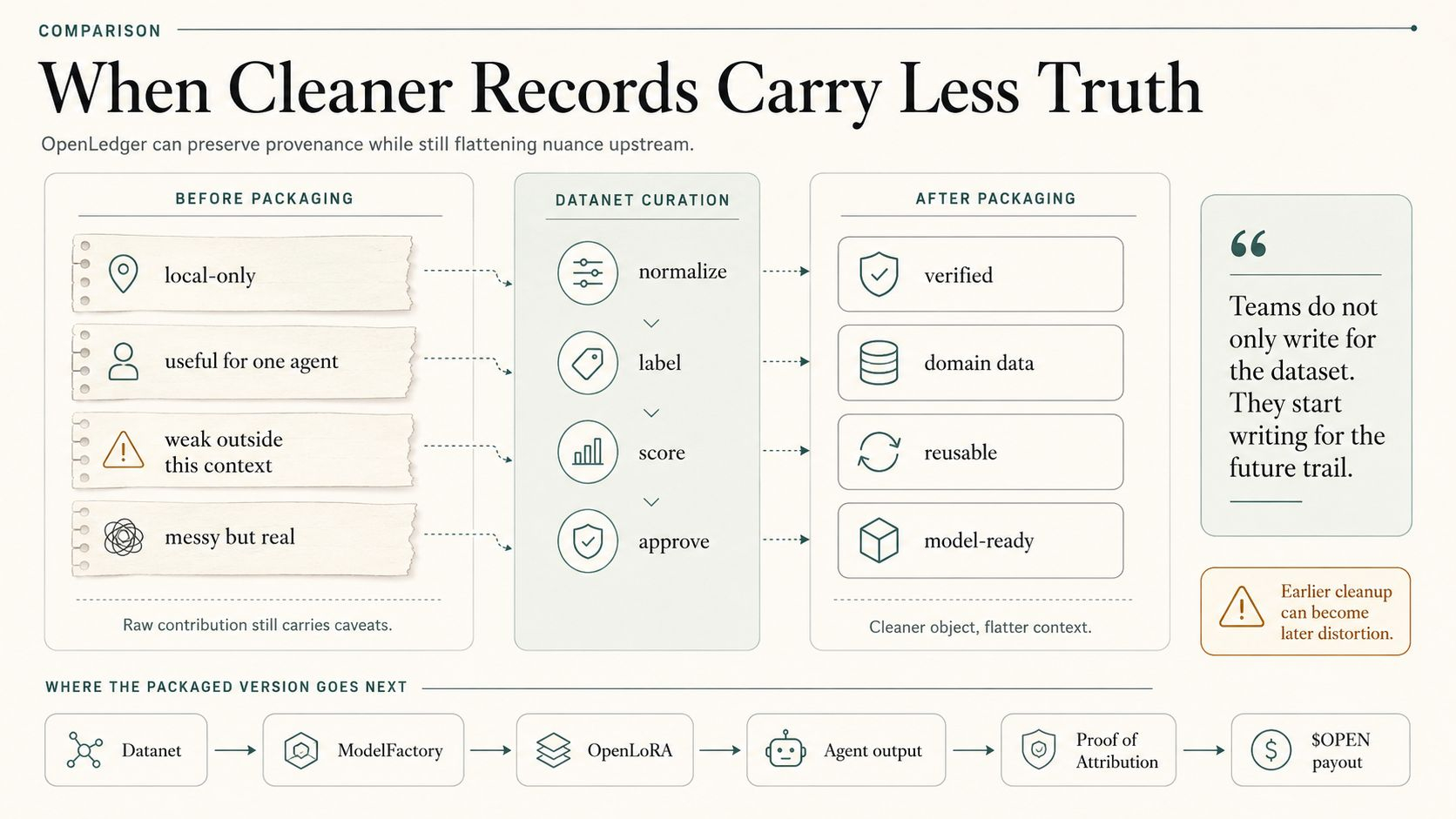
Because the soft version of OpenLedger is easy. Datanets. Proof of Attribution. AI agents. Data ownership. Payable AI. Whatever. Nice enough. The actual thing, inside a workflow, is harsher. Once a contributor knows the output will be traceable and monetizable later, they stop writing for the dataset and start writing for the attribution layer. Same humans. Same pressure. Different behavior. Cleaner contribution. Worse decision surface.
Okay okay.
I kept picturing a boring data onboarding queue because it is always the boring queues. Some builder or community curator is trying to push a Datanet contribution through. The upload is waiting. The metadata field is red. Someone wants the agent live before the window closes.
They know it is not staying local. It may feed a ModelFactory deployment. It may sit under an OpenLoRA adapter. Some trading agent might pull from it. Some AI Marketplace query might route revenue back through the attribution path. So nobody wants to leave a weird caveat hanging there. Nobody wants “useful for this narrow context but weak outside it” if “verified dataset” is shorter and less embarrassing. Nobody wants to explain model-specific nuance when the metadata can hold one neat label and keep the pipeline moving.
So they compress.
Not later.
Up front.
And this is very OpenLedger-native. Not generic AI-data whining. Specific to a system where contribution is meant to become durable, traceable, queryable, reusable, and economically active later. That future changes how people package it now.
Maybe “too attributable” is not fair.
No. Fair enough.
Attribution is the point. That is why they are using it. But the point still has side effects. Once the contribution has a future payout path, the present gets tidied for it. And tidy is where people start lying to themselves.
I can see the ugly version already. The raw source is still messy as hell. Scrape notes still carrying caveats. Curator still treating the data as narrow. Discord thread still saying “only for this agent” or “do not use for trading output yet.” Then the Datanet metadata gets populated with something travel-safe because the team knows the later object needs to travel. Needs to look respectable. Needs to survive attribution without making the data pipeline look like the data pipeline actually was.
Nice.
Now the OpenLedger record is not just preserving contribution. It is preserving the travel-safe version of contribution the team thought would age well in a payable system.
Then the model uses the flattened label anyway, and that is the version the next agent inherits.
Worse version, honestly.
Because it means the later misuse did not really start later. It started when they cleaned the data up for the attribution record.
A team wants the final object to survive downstream. Understandable. They do not want the Datanet cluttered with route-specific qualifiers, weak-source flags, model-only caveats, provisional labels, local-only notes, all the weird little truths that would force the next builder to slow down. So they trim. They standardize. They choose the metadata value that will look stable later instead of the one that is truest now.
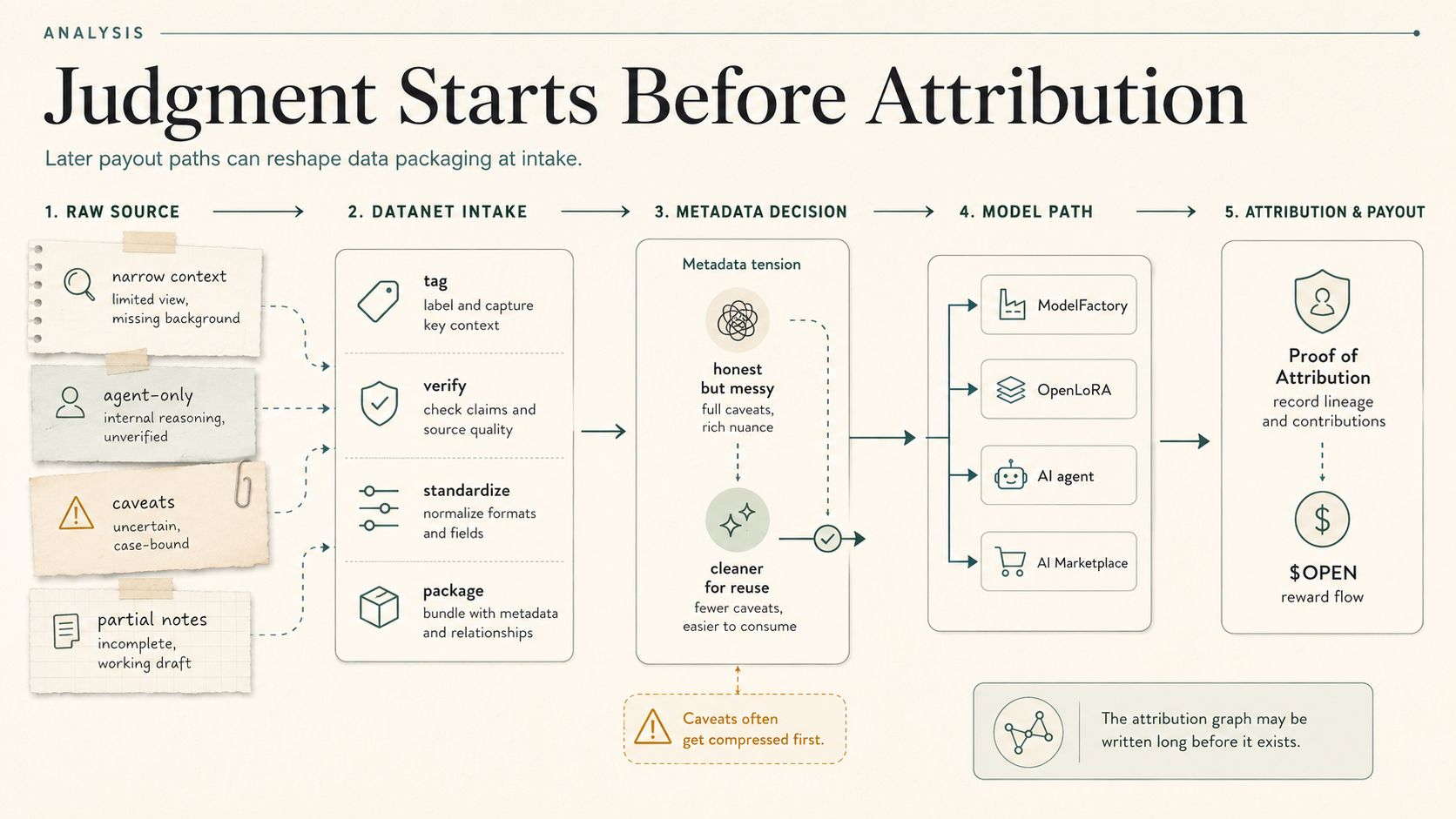
And then later systems inherit something that was born flatter than the data itself.
That is why I do not buy the lazy line that attribution only matters once a model output gets queried. No. It is already in the room earlier, changing what gets said and what gets rounded off. OpenLedger's PoA does not have to calculate a payout yet for the attribution layer to affect behavior. People know the record is headed there. That is enough.
Enough is not enough... actually.
I keep coming back to one ugly little example. A Datanet has a source that is good for one narrow agent workflow, not final for anything broader. Everyone around the dataset knows that. It lives in notes, comments, someone’s head, all the healthy institutional places where precision goes to die. Then the metadata field gets set to something neat because nobody wants the future attribution path looking half-resolved. Later a ModelFactory deployment pulls the neat field like it was the whole case. Later an OpenLoRA adapter trains around it. By then nobody is reopening the source caveat. The adapter already learned around the neat version. Later an AI Marketplace query pays against it. Great. By then the team can even tell themselves the later misuse was the real mistake.
Was it.
Or did the mistake start when they realized the contribution would be attributable later and started writing for that audience instead of the data in front of them.
That is the more annoying version. Because it means OpenLedger did not just preserve the AI workflow. It pressured the workflow into a cleaner self-presentation before preservation even happened.
Good for the record. Maybe.
Not always good for the model.
And that kind of distortion is almost impossible to audit afterward because the final attribution path looks perfectly normal. On OpenLedger, Datanet matched. Provenance trail exists. Model lineage looks respectable. $OPEN payout logic can follow the neat route. Nobody can see the uglier wording that got sacrificed three steps earlier because it would have made the later contribution harder to operationalize.
That earlier loss does not leave a tidy scar.
It just quietly improves the final object and worsens the truth content.
Which is a rotten trade if the next model is going to act on it.
Then somebody downstream reads the attribution path like it is a faithful capture of the original contribution. Maybe it is. Maybe it is the cleaned version the team thought would survive being queried later without making everyone slow down and ask what the hell the data actually meant.
Still traceable.
Still attributable.
Still very payable.
Just maybe bent before PoA ever got a clean thing to track.