For the last few years, AI has mostly been talked about in terms of size.
Bigger models. More compute. Larger datasets. More powerful chips. More money behind the companies building all of it.
That made sense for a while. The early results were hard to ignore. As models grew, they became more capable. They could write, code, summarize, translate, reason through problems, and respond in ways that felt far more flexible than older software. The industry learned a clear lesson: scale works.
But scale may not be the whole story anymore.
The next stage of AI could be shaped less by who builds the biggest model, and more by who has access to the most useful data. Not just more data, but better data. Data that is specific, accurate, fresh, and tied to real human or business activity.
That is where the race starts to look different.
A general AI model can learn from the public internet. It can absorb books, websites, code, articles, forums, and documentation. That gives it broad knowledge. But broad knowledge has limits. It can explain how a hospital works, but it may not understand the exact way a hospital handles patient discharge. It can describe financial analysis, but it may not know the internal signals a certain trading desk watches every day. It can talk about customer support, but it may not know why customers of one specific product actually cancel.
That kind of knowledge is not usually public.
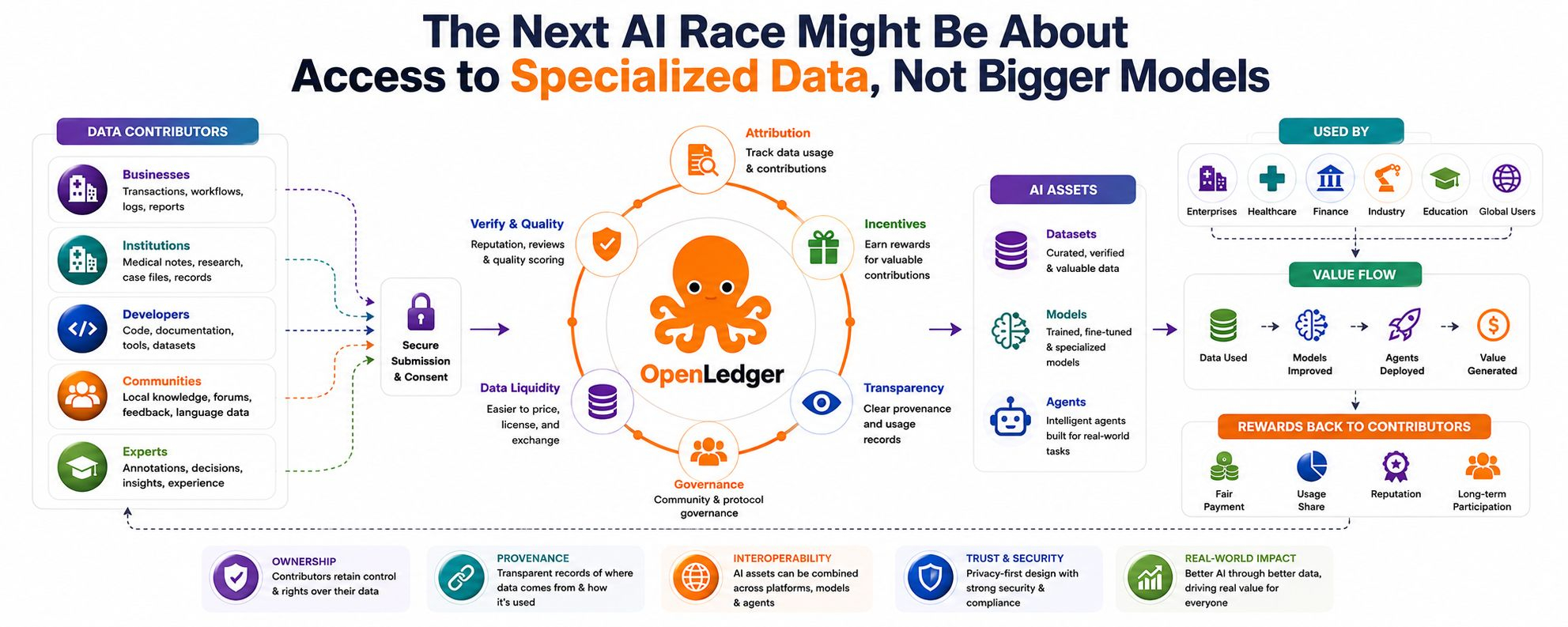
It lives inside companies, communities, institutions, and workflows. It sits in support tickets, legal documents, medical notes, engineering logs, transaction histories, call transcripts, research files, sensor data, and expert decisions made over many years.
This is the kind of data AI now needs most.
The public internet helped build the first generation of powerful AI models. But the next generation may need something deeper: data that comes from real environments, real use cases, and real experience. That data is harder to collect. It is often private. It may be sensitive. It may belong to many different people. And because of that, it may become one of the most valuable resources in the AI economy.
This is where OpenLedger becomes relevant.
OpenLedger is building around the idea that data, models, and AI agents should not remain locked away or treated as invisible inputs. Its goal is to create a system where people can contribute data, build or improve models, deploy agents, and receive value when their contributions are used.
At the center of this is a simple but important question:
If data helps create AI value, why are data contributors usually left out of the value chain?
That question matters more than it may seem.
Most AI systems depend on human-created knowledge. Writers, developers, researchers, analysts, businesses, communities, and domain experts all produce the material that models learn from. But once that material is used, the original contributors often disappear from the picture. They may not be credited. They may not be paid. They may not even know their work played a role.
With specialized data, this problem becomes even more serious.
A company will not share valuable internal data unless it has control over how that data is used. A medical institution cannot simply release patient information without privacy protections. A group of experts will not keep contributing high-quality knowledge if all the value goes somewhere else. Communities will not provide local or niche knowledge forever if they are treated as free raw material.
So the challenge is not only technical. It is also economic.
AI needs better ways to reward the people and organizations that provide useful data. It needs systems that can show where data came from, how it was used, and who should benefit when that data improves a model.
That is the idea behind OpenLedger’s focus on attribution.
Attribution sounds simple, but in AI it is difficult. A model’s answer is shaped by many things: training data, fine-tuning, architecture, prompts, feedback, and usage patterns. It is not always easy to say which exact data point created which exact output.
Still, the direction is important. If AI is going to rely more on specialized data, then attribution cannot be ignored. Without it, valuable data will stay locked away. With it, contributors may have a reason to participate.
This could lead to a very different kind of AI marketplace.
Instead of data being quietly extracted and absorbed into closed models, it could become something more traceable and usable. A dataset could be contributed, verified, improved, licensed, and rewarded. A model could be trained on specific data and carry a clearer record of what shaped it. An AI agent could use certain models or datasets and send value back to the people who helped make them useful.
That is the larger vision OpenLedger is pointing toward.
The word “liquidity” is often used in finance, but here it has a practical meaning. Many AI assets are currently hard to move or monetize. A useful dataset may exist, but there may be no simple way to price it or track its usage. A fine-tuned model may solve a real problem, but it may be difficult to distribute. An AI agent may perform valuable work, but the economic links behind it can be unclear.
OpenLedger is trying to make these assets easier to use, combine, and reward.
This does not mean every AI system needs blockchain. Many will not. Some companies will use private databases, contracts, and internal platforms. That is fine. The stronger point is not that blockchain automatically solves AI. The stronger point is that AI now needs better infrastructure for ownership, access, attribution, and incentives.
Blockchain is one possible way to build that infrastructure.
The real value will depend on execution. A system like OpenLedger has to attract high-quality data, protect contributors, prevent spam, support developers, and create real demand for the models and agents built on top of it. It also has to make attribution meaningful, not just a nice phrase in a whitepaper.
Because bad data is easy to produce.
If people are rewarded simply for submitting data, some will submit low-quality, repeated, synthetic, or misleading information. That can hurt models instead of improving them. So any serious data network needs filtering, reputation, review, and strong evaluation. It needs to measure whether data actually improves performance.
Good data has weight. It carries context.
A customer support transcript is not useful only because it contains words. It is useful because it shows what customers struggle with, what makes them frustrated, what solves their problem, and what signals they may leave.
A machine failure log is not useful only because it contains numbers. It is useful because failure is rare, and rare events teach models things normal data cannot.
A medical annotation is not useful only because it labels a symptom. It is useful because it reflects judgment built through training and experience.
That kind of data cannot be replaced by scale alone.
This is one reason smaller, specialized models may become more important. The largest model may be impressive, but it may not always be the best tool for every job. In many industries, people need systems that are cheaper, faster, more private, and trained on the exact data that matters to their work.
A general model can talk about logistics. A specialized model trained on a company’s actual shipping routes, supplier delays, warehouse limits, and demand patterns can make better decisions.
A general model can explain legal contracts. A specialized model trained on a firm’s previous reviews, preferred clauses, and jurisdiction-specific risks can be far more useful.
A general model can discuss cybersecurity. A specialized model trained on a company’s own incidents, systems, dependencies, and alerts can understand threats in a more practical way.
The advantage is not just intelligence. It is familiarity.
That is why specialized data may become the real competitive edge.
The biggest AI companies will continue building powerful foundation models. That race is not over. But around those models, another race is forming. It is quieter, more fragmented, and probably more important for real-world adoption.
Legal AI will need legal data. Healthcare AI will need healthcare data. Robotics will need physical-world data. Finance will need market and behavioral data. Education AI will need learning data. Local-language AI will need real speakers, local context, and cultural knowledge.
No single general model can fully own all of that.
The future may be built through many smaller data networks, each focused on a specific field, region, profession, or use case. Some will be private. Some may be open. Some may be community-driven. Some may run through platforms like OpenLedger.
What matters is that the data becomes usable without stripping away ownership and context.
This is also why trust will become more important.
As AI moves into serious decisions, people will ask harder questions. Where did this answer come from? What data shaped this model? Was the data licensed? Was it current? Was it biased? Who contributed to it? Who gets paid when it is used?
These questions are not obstacles. They are signs that AI is becoming part of real infrastructure.
When technology is new, people tolerate mystery. When it starts making business, financial, medical, or legal decisions, mystery becomes a problem.
The next phase of AI will need more transparency. Not perfect transparency, because models are complex. But enough transparency for people to trust the system, understand its limits, and know whether the data behind it is legitimate.
OpenLedger’s approach speaks to that need.
It is not just about monetizing data in a simple sense. It is about creating a structure where data has a visible role in the AI economy. Where contributors are not invisible. Where models are not detached from the sources that shaped them. Where agents can become part of a larger network of value.
That is a serious idea, even if the space is still early.
There will be mistakes. Some projects will overpromise. Some data markets will attract poor-quality contributions. Some attribution systems may not work well enough. Some token models may reward activity instead of usefulness. These risks are real.
But the larger shift is also real.
AI is moving from general knowledge toward applied intelligence. And applied intelligence needs context. It needs data from the places where work actually happens.
That is why the next AI race may not look as dramatic from the outside. It may not always be about the biggest launch or the loudest benchmark. It may happen inside industries, inside communities, and inside narrow use cases where one model understands something another model does not.
A model trained on public data may know the language of a field.
A model trained on specialized data may know the work.
That difference is where value begins.
OpenLedger is betting that the people who provide that specialized data should be part of the upside. If that idea works, it could help move AI away from a one-sided extraction model and toward something more participatory.
The future of AI may still involve bigger models. But bigger alone will not be enough.
The systems that matter most will be the ones that know the right things, from the right sources, with the right permissions, at the right time.
That is not a louder kind of intelligence.
It is a more useful one.
