

OpenLedger first looked like another AI-chain project trying to ride the obvious narrative.
That was probably why I ended up spending more time on it than expected. The first layer felt familiar: AI, blockchain, data, models, agents, monetization. All the usual words were there. But underneath that surface, the project was circling a more specific problem.
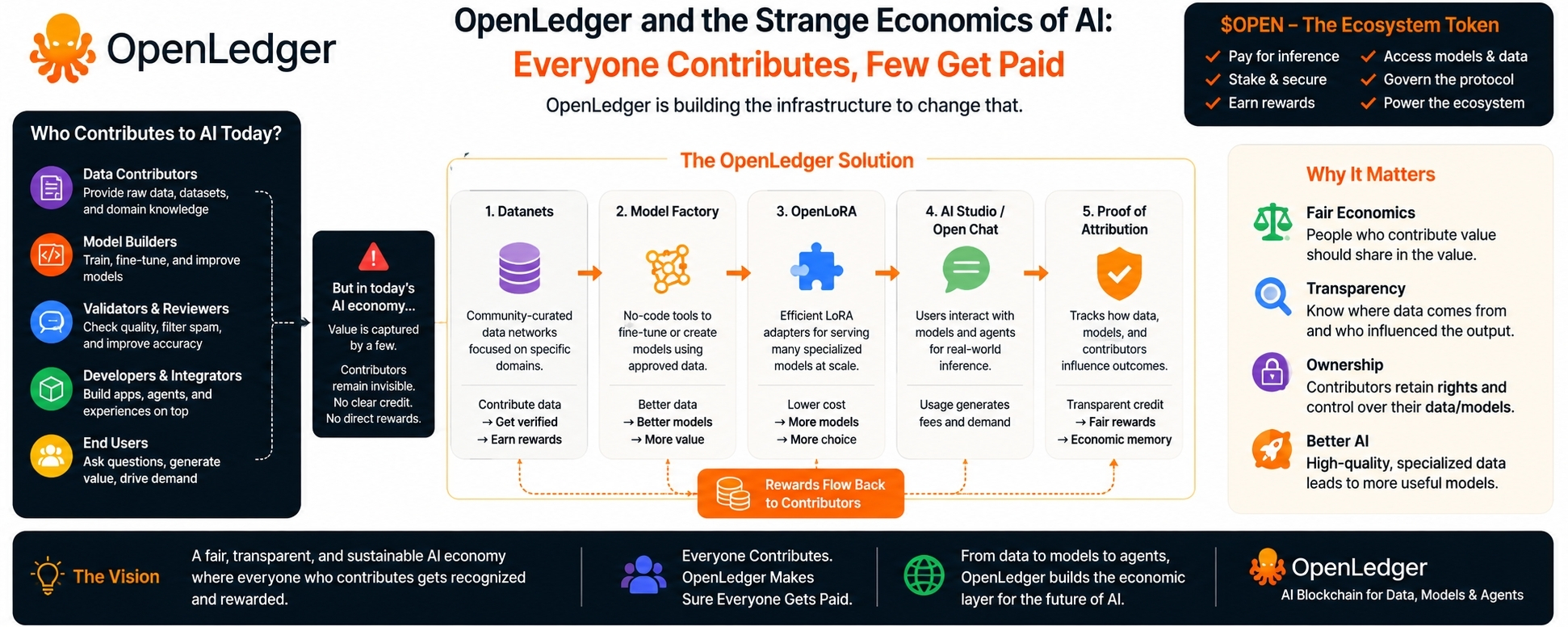
OpenLedger is not only asking how AI can be put on-chain.
OpenLedger is asking who gets credit when AI becomes useful.
That is a better question.
Most AI systems hide the contribution chain. A model gives an answer, the interface gets praised, and the company behind the model captures most of the value. But the data contributors, curators, domain experts, validators, model tuners, and smaller builders often vanish from the economics. They helped shape the output, but the system rarely remembers them.
OpenLedger tries to build that memory.
That is where the project becomes interesting. Not because every part is proven. It is not. Not because the branding avoids hype entirely. It does not. But because the core idea has weight: if data, models, and agents are going to become valuable assets, there needs to be a way to track how they are used and how value moves back to contributors.
OpenLedger calls this Proof of Attribution.
That phrase can sound neat, maybe too neat. Attribution in AI is not clean. A response may come from pretraining, fine-tuning, retrieval, prompt structure, user context, model architecture, or some messy blend of all of them. Measuring influence is hard. Paying people based on that influence is even harder.
Still, the problem is real.
OpenLedger starts with Datanets, which are basically community-curated data networks built around specific domains. This is one of the smarter parts of the design because “data” by itself is too vague. Random uploaded information is not useful. Specialized, validated, high-quality data can be.
A smart contract security Datanet makes sense.
A DePIN analytics Datanet makes sense.
A medical or legal Datanet could be valuable, though much harder to manage.
The project seems to understand that it cannot compete with giant AI labs by training a massive general-purpose model from scratch. That would be unrealistic. The more believable path is smaller, specialized intelligence built on better domain data.
That is where OpenLedger has a real angle.
OpenLedger’s Model Factory fits into this idea by making it easier to turn approved data into models or adapters. The no-code direction is important. Most people with valuable domain knowledge are not going to run training scripts, manage infrastructure, and debug model pipelines. If OpenLedger wants researchers, analysts, auditors, communities, and niche experts to contribute, the interface has to be approachable.
But there is a danger here too.
Easy model creation can create the illusion of quality. A fine-tuned model is not automatically a good model. It can sound confident and still be wrong. It can perform well in a demo and collapse in real use. It can be trained on weak data and still appear useful to a casual user.
OpenLedger will need strong evaluation standards.
Not just dashboards.
Not just “model created successfully.”
Actual proof that the model improved.
That is the difference between a useful AI network and a prettier interface around mediocre outputs.
OpenLedger also has OpenLoRA, which I found more practical than flashy. The idea is to serve many LoRA adapters efficiently instead of spinning up a heavy deployment for every specialized model. That matters because the project’s whole thesis depends on many smaller models existing at once.
OpenLedger cannot talk about thousands of specialized models if serving them is too expensive.
This part feels grounded. It is not the kind of feature that grabs casual attention, but it supports the architecture. If Datanets create specialized data, and Model Factory helps produce specialized adapters, then OpenLoRA helps make those adapters usable at scale.
That is a coherent chain of thought.
The more I looked at OpenLedger, the more I felt the architecture made sense as a loop. Data enters through Datanets. Models are built through Model Factory. Adapters are deployed through OpenLoRA. Users interact through AI Studio or Open Chat. Usage creates fees. Proof of Attribution tries to route value back to the people whose contributions mattered.
That loop is the project.
If the loop works, OpenLedger has something.
If the loop breaks, the rest becomes decoration.
The most fragile piece is attribution. OpenLedger can build registries, staking flows, model tools, and interfaces. Those are hard, but understandable. Attribution is different. It touches math, incentives, trust, and human behavior all at once.
People will game anything tied to rewards.
That is guaranteed.
If contributors earn based on data influence, some will try to upload duplicated examples, slightly rewritten material, synthetic filler, or data designed to trigger attribution scoring. Validators are supposed to help, but validators also need incentives. If they approve too much, quality falls. If they reject too much, contribution slows.
OpenLedger’s biggest enemy may not be competitors.
It may be low-quality participation.
That is why community behavior matters so much here. A normal crypto project can survive a noisy community for a while. OpenLedger’s community directly affects the product because the product depends on contribution quality.
A big community is not enough.
OpenLedger needs the right kind of community.
People discussing datasets, model performance, validator standards, attribution disputes, API reliability, and real applications are valuable. People only chasing points and allocation are temporary. They may help early activity, but they do not prove long-term demand.
This is one of the things I would keep watching.
Not the loudest posts.
The quality of conversation.
OpenLedger’s token also needs to be viewed carefully. OPEN has several roles: gas, staking, rewards, governance, inference payments, model access, and ecosystem activity. That gives the token a place in the system, but it also creates pressure. The network needs real usage to support real value.
Token incentives can start a market.
They cannot fake one forever.
If users pay for inference because models are useful, the system gets stronger. If contributors earn because their data improves models, the system gets stronger. If developers build because OpenLedger saves them time or gives them attribution tools they cannot easily build elsewhere, the system gets stronger.
But if activity mostly comes from reward farming, the network will look busier than it really is.
That is a familiar crypto problem.
OpenLedger has a sharper version of it.
The project also has an interesting UX challenge. It has to serve crypto users, AI developers, data contributors, validators, and possibly enterprises. These groups do not want the same thing.
Crypto users want transparency.
AI developers want reliable APIs and good model performance.
Data contributors want simple uploads and fair rewards.
Enterprises want privacy, compliance, support, and predictable costs.
OpenLedger has to make the product simple enough for normal users but transparent enough for serious builders. That balance is difficult. Hide too much, and the attribution layer becomes a black box. Expose too much, and the product becomes too complex for anyone outside the core crypto-AI crowd.
This is where product design will matter more than slogans.
OpenLedger should not win by saying “AI blockchain” louder.
It should win by making the workflow feel obvious.
Create or join a Datanet. Contribute useful data. Validate quality. Build a model. Deploy it. Let users interact with it. Show attribution clearly. Pay contributors fairly.
That sounds simple.
It is not.
The enterprise side is even more complicated. OpenLedger’s pitch around provenance and attribution should appeal to serious organizations in theory. Companies care about where outputs come from. They care about auditability. They care about data rights.
But they will ask hard questions.
Where is the data stored?
Who controls access?
Can sensitive data be removed?
How are copyrighted datasets handled?
Can attribution reveal private workflows?
Who is liable when a model gives bad output?
OpenLedger will need answers that go beyond crypto-native confidence. In regulated sectors, “on-chain transparency” is not always a selling point. Sometimes it is a concern.
That does not kill the thesis.
It just narrows where adoption may happen first.
OpenLedger’s best early markets are probably areas already close to crypto or open data. Smart contract security. Developer tooling. DePIN. On-chain analytics. AI agents that interact with Web3 infrastructure. These are places where users understand wallets, proofs, data markets, and incentives.
Healthcare and legal AI may come later, but they require more discipline.
Much more.
I would rather see OpenLedger prove itself in narrow markets than spread across every possible AI category. The project is strongest when it sounds specific. A Datanet for smart contract vulnerabilities is specific. A model for verified DePIN network data is specific. An agent powered by attributed datasets is specific.
“Decentralized AI for everyone” is not specific.
That is where projects get lost.
OpenLedger feels different from many competitors because it does not only focus on compute, agents, or model hosting. It tries to connect the entire contribution chain. Data, model, deployment, inference, attribution, reward.
That is ambitious.
Maybe too ambitious.
But at least the ambition has structure.
The weakness is that every link in the chain has to be credible. If the data is bad, the model suffers. If the model is weak, inference demand disappears. If demand disappears, rewards shrink. If rewards shrink, contributors leave. If attribution feels unfair, trust breaks.
The loop can compound upward.
It can also collapse inward.
That is why I would judge OpenLedger by evidence, not announcements. Show active Datanets. Show rejected data. Show model benchmarks. Show real inference usage. Show contributor payouts from actual demand. Show developers returning after initial campaigns end.
That would matter.
OpenLedger does not need more abstract claims. It needs visible proof that its system improves model quality and rewards the right people.
I still think the project is worth watching because the core question is important. AI is already producing value from layers of hidden contribution. That imbalance will become more obvious over time. People will ask who owns the data, who shaped the model, who deserves credit, and who gets paid.
OpenLedger is trying to answer those questions with infrastructure.
That is not easy.
It may not fully work.
But it is a real problem, and the project is at least attacking it from a coherent angle.
My personal view is cautious but interested. I do not see OpenLedger as a finished answer. I see it as an experiment in building economic memory for AI. The good parts are clear: specialized data networks, attribution-first design, practical adapter deployment, and a product loop that connects contributors with model usage.
The risks are also clear: weak attribution, spammy data, incentive farming, unclear enterprise readiness, token dependence, and the difficulty of proving model quality in public.
Both sides matter.
OpenLedger becomes compelling when stripped of the hype. Not as a guaranteed winner. Not as a magic AI economy. Not as a chain that somehow fixes data ownership overnight.