A few years ago, infrastructure was the least glamorous part of technology. Nobody talked about it unless something broke. Roads, payment rails, servers, cloud systems — all of it existed in the background. Necessary, expensive, mostly invisible. The interesting conversations happened at the application layer where people could actually see products changing behavior.
AI changed that language almost overnight.
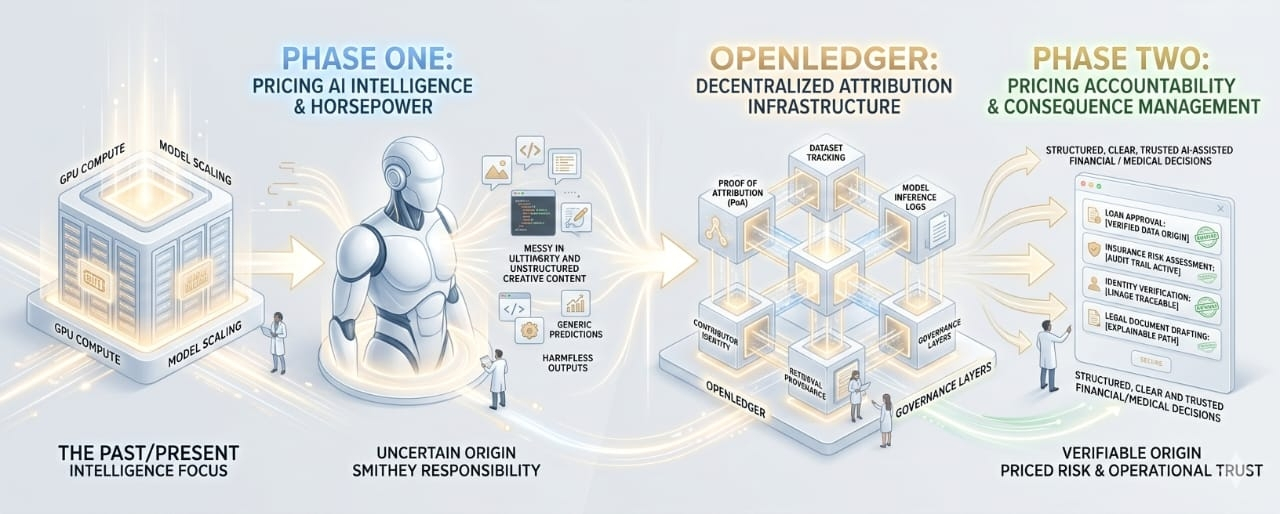
Suddenly infrastructure became exciting. GPUs turned into geopolitical assets. Compute clusters became financial narratives. Data centers started getting discussed with the same intensity people used to reserve for oil fields. The entire market began acting as if the future of AI depended almost entirely on who controlled the most horsepower.
For a while, I believed that too.
The logic felt obvious. Bigger models needed bigger compute. Better reasoning required more scale. Whoever could process more data faster would dominate the next technological cycle. Most AI conversations still operate inside that assumption.
But the more AI systems moved into commercially meaningful environments, the more uncomfortable that explanation started to feel.
Because once AI stops generating entertainment and starts influencing decisions, intelligence alone stops being the central problem.
A chatbot writing a bad poem is harmless. A model helping approve loans, flag compliance risks, assess insurance claims, screen identities, draft legal documents, or guide autonomous financial agents exists in an entirely different category. At that point, nobody serious asks how quickly the model generated tokens. They ask something much uglier.
Who becomes responsible if the system makes the wrong decision?
That question feels strangely absent from a lot of crypto AI discussions.
Most projects still frame the future as a race toward smarter agents, cheaper inference, or larger decentralized compute networks. OpenLedger gets described the same way — another AI infrastructure protocol attempting to build rails for the next generation of machine intelligence.
Technically, that description is correct. OpenLedger positions itself around decentralized datasets, attribution systems, model coordination, on-chain AI infrastructure, and contributor incentives. Their documentation repeatedly emphasizes “Proof of Attribution,” a framework designed to track how datasets, models, and contributors influence AI outputs.
But I think the market may be looking at the wrong part of the system.
Most people hear attribution and immediately think about rewards. Paying contributors fairly. Compensating datasets. Distributing value to participants. It fits neatly into the familiar crypto incentive narrative.
What feels more important to me is something else entirely.
Attribution systems do not only distribute rewards.
They also distribute responsibility.
That distinction changes the entire conversation around OpenLedger.
I remember watching the first wave of autonomous agent hype and feeling like everyone skipped several uncomfortable steps. Not because the technology was fake. The technology is clearly real. But the coordination risks felt massively underestimated.
People talked about agents handling payments, negotiating services, managing workflows, moving capital, executing trades, booking infrastructure, and interacting with external systems autonomously. Fine. But if an agent acts on flawed training data, manipulated retrieval inputs, biased inference layers, or corrupted datasets, where exactly does accountability land?
That answer becomes blurry very quickly.
Traditional software systems were easier in a strange way. A company shipped code. If catastrophic failures happened, responsibility was structurally visible even if the legal details became messy later.
AI systems feel fragmented by design.
One party contributes data. Another fine-tunes the model. Another hosts inference. Another builds orchestration logic. Retrieval systems inject outside context midway through execution. Adapters modify behavior dynamically. External APIs influence outputs again.
By the time a final answer reaches the user, responsibility looks smeared across multiple invisible layers.
And once responsibility becomes difficult to map, risk becomes difficult to price.
Markets hate uncertainty that cannot be operationalized.
Institutions hate it even more.
Retail users tolerate ambiguity surprisingly well if the product feels magical enough. Enterprises do not behave that way. Banks definitely do not. Regulated industries absolutely do not.
Nobody in a compliance meeting says the system “felt trustworthy.”
They ask for audit trails. Source lineage. Escalation paths. Decision reconstruction. Documentation. Explainability — even when explainability itself is imperfect theater.
That is where OpenLedger becomes more interesting than the normal “AI token” framing suggests.
Because if the project is genuinely attempting to build verifiable attribution infrastructure, then maybe the more important question is not whether it helps AI scale.
Maybe it helps AI become governable.
That sounds far less exciting than compute narratives.
Governability does not generate the same hype as intelligence scaling. Nobody builds cult-like enthusiasm around audit architecture. But historically, boring infrastructure tends to matter longer than flashy infrastructure.
Financial markets evolved that way.
At first, speed mattered. Then settlement mattered. Then auditability mattered. Then compliance infrastructure mattered. Eventually invisible trust systems became just as important as the visible execution systems people originally obsessed over.
AI may follow a similar pattern.
Not perfectly. Technology never repeats cleanly. But the rhyme feels familiar.
There is also a practical misunderstanding people often make about institutions. They are not necessarily afraid of innovation. What they fear is uncertainty they cannot operationalize.
That is different.
A procurement team evaluating AI integration does not really care about crypto-native storytelling. They care whether someone can explain how decisions happened after legal teams start asking questions later.
And legal teams always ask questions later.
Imagine a relatively simple example. An insurance company uses AI-assisted systems for risk assessment support. Not full automation. Just decision assistance. The model produces biased recommendations because part of the underlying dataset pipeline was flawed or manipulated.
Now a customer disputes the outcome. Regulators become involved. Internal governance teams begin tracing dependencies.
What happens next?
If nobody can meaningfully reconstruct where the decision originated, governance becomes guesswork. And guesswork inside regulated systems becomes extremely expensive.
This is why I think the phrase “pricing model liability” matters more than people realize.
Not necessarily legal liability yet. At least not in the direct sense most people imagine.
Economic liability comes first.
Trust discounts. Risk premiums. Integration hesitation. Compliance overhead. Counterparty uncertainty.
Those things get priced into markets long before courts establish clean legal frameworks.
If two AI ecosystems offer similar functional performance, but one provides stronger provenance around how outputs were generated, institutions may rationally choose the more auditable environment even if raw model performance is slightly weaker.
That happens constantly outside AI.
Trusted supply chains outperform uncertain ones. Auditable financial systems outperform opaque ones. Verification layers quietly become critical infrastructure.
OpenLedger’s documentation around Proof of Attribution and retrieval attribution hints at exactly this direction. The system attempts to log how data sources influence outputs, how inference paths are constructed, and how contributors participate in the final generation process.
Most people interpret that as monetization infrastructure.
What it actually resembles is forensic infrastructure for machine reasoning.
That distinction matters enormously.
Because future disputes around AI probably will not revolve around whether models are intelligent enough. They will revolve around: where outputs came from, which systems influenced decisions, whether data pipelines were compromised, whether governance controls existed, and whether institutions can reconstruct what happened afterward.
That is a completely different layer of value creation.
At the same time, skepticism is necessary because attribution inside AI systems is genuinely difficult.
Modern models do not maintain clean ingredient lists. Training influence is diffuse. Signals blend together in messy nonlinear ways. Contribution weighting can easily become probabilistic fiction if implemented poorly.
And fake accountability may ultimately be worse than visible opacity.
If systems merely simulate traceability without meaningful causal grounding, institutions may eventually distrust the entire category.
Then crypto adds another complication.
The moment attribution becomes financially valuable, adversarial optimization begins immediately.
Spam datasets. Manufactured contribution claims. Sybil reputation loops. Artificial trust farming. Incentive manipulation.
Anyone who has spent enough time around crypto systems understands this instinctively. Systems rarely fail under cooperative conditions. They fail under adversarial incentives.
So OpenLedger’s challenge is much larger than building attribution tools.
It has to build attribution systems that survive hostile behavior while still feeling operationally useful to institutions.
That is an extremely difficult product problem.
There is another uncomfortable question underneath all of this too.
Do enterprises even want decentralized accountability?
Conceptually, distributed attribution sounds elegant. But operationally, many institutions may still prefer centralized vendors simply because accountability pathways remain easier to understand there.
One provider. One contract. One escalation route.
Distributed responsibility can easily become bureaucratic chaos if implemented badly.
Which means OpenLedger’s real challenge may not be technical at all.
It may be organizational psychology.
The system has to make decentralized accountability feel simpler rather than more complicated.
And that is far harder than most token markets appreciate.
Still, I cannot shake the feeling that AI conversations remain trapped in phase one.
Everyone still talks primarily about intelligence scaling. Faster inference. More capable agents. Larger models. Cheaper compute.
But maybe the next bottleneck is not intelligence itself.
Maybe it is consequence management.
Because intelligence without accountable lineage works perfectly fine for entertainment. Less so for financial systems. Much less for regulated industries.
And if that shift becomes real, then OpenLedger may not actually be competing in the category most people assume.
Not compute. Not model access. Not inference throughput.
Something quieter.
The market for reducing uncertainty around machine-generated decisions.
That is a much less glamorous thesis.
Which is exactly why it might matter.
