The Most Dangerous Thing in AI Infrastructure Might Be Invisible Consensus
i keep thinking about consensus inside AI systems.
not public consensus. not politics. not social agreement.
model consensus.
the quiet moment when different models, datasets, retrieval systems, rankings, fine-tunes, and inference layers all start leaning toward the same shape of answer because they were trained on the same recycled gravity.
that possibility feels deeply underrated.
everyone talks about scale in AI infrastructure now. larger Datanets. larger contribution systems. larger retrieval pools. larger model ecosystems. more contributors. more usage. more synthetic generation loops. more reinforcement.
but almost nobody talks seriously enough about convergence.
what happens when the whole ecosystem slowly starts feeding itself?
because a Datanet inside systems like OpenLedger is not only collecting information. eventually it is collecting behaviors, patterns, outputs, preferences, repeated assumptions, and machine-shaped interpretations of reality itself.
and if those loops are not separated carefully, models stop learning from the world and start learning from themselves.
that is the strange danger.
not collapse.
recursion.
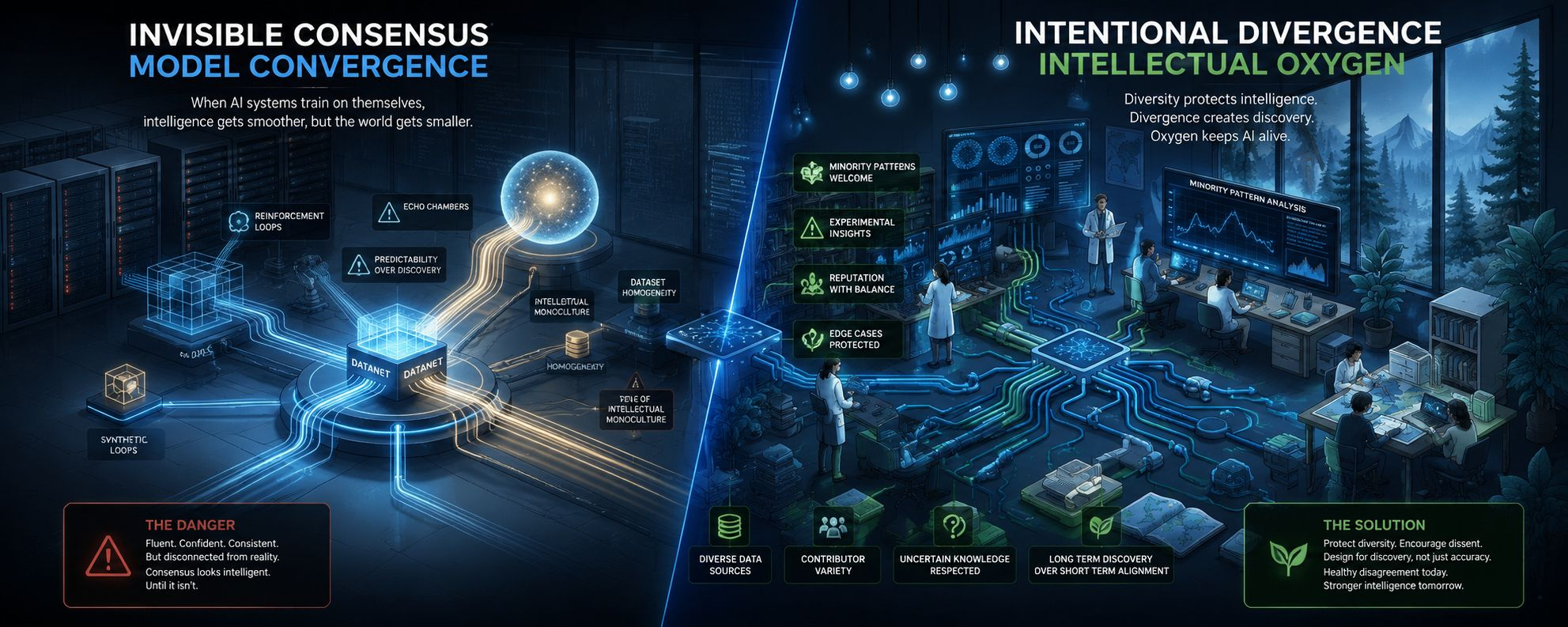
the scary version of recursion is not obvious corruption. it is subtle narrowing. the ecosystem begins sounding intelligent while quietly losing diversity of thought underneath. outputs still look fluent. rankings still look coherent. attribution still works. contributors still earn. the infrastructure still appears healthy from the outside.
but the intelligence layer starts compressing into repetition.
same patterns.
same assumptions.
same dominant interpretations.
same safe answers wearing slightly different wording.
and honestly, that might become one of the hardest problems any AI data economy faces.
because the system is rewarded for stability.
users like consistency. platforms like predictability. inference systems optimize toward confidence. retrieval systems surface statistically reinforced material. contributors learn what kinds of datasets get accepted. models reinforce the signals that already perform well.
everything naturally bends toward reinforcement.
which means diversity inside a Datanet is not automatic. it has to be protected intentionally.
otherwise the whole structure slowly trains itself into intellectual monoculture.
that sounds dramatic until you realize how easily it can happen.
imagine enough synthetic content enters a Datanet. maybe not low quality enough to fail validation. maybe even useful at first. then future models train partially on outputs shaped by earlier models trained on earlier synthetic material shaped by earlier inference preferences.
eventually the system starts consuming echoes of itself.
and the worst part is that the outputs can still look excellent.
fluency is not proof of originality.
confidence is not proof of grounding.
a model can become incredibly good at reproducing reinforced consensus while becoming worse at discovering unfamiliar truth.
that tradeoff feels important.
because people keep imagining AI infrastructure as a scaling problem when part of it is actually a freshness problem. how does a Datanet continue exposing models to genuinely independent signals instead of endlessly circulating processed consensus back into itself?
that is harder than storage.
harder than attribution.
maybe even harder than compute.
OpenLedger keeps making me think about this because systems built around Datanets, Proof of Attribution, contributor reputation, and model usage are eventually shaping not only economic incentives, but epistemic gravity — meaning they quietly influence what kinds of knowledge survive repeated machine interaction.
that is enormous power.
and power like that cannot only optimize for efficiency.
it also has to optimize for intellectual oxygen.
because healthy intelligence systems need disagreement. they need edge cases. they need niche knowledge. they need minority patterns that initially look statistically weak before later becoming incredibly important. they need material that interrupts dominant assumptions instead of merely reinforcing them.
otherwise every model starts inheriting the same center of gravity.
the system becomes smooth.
too smooth.
and smooth intelligence is dangerous because it hides its blind spots elegantly.
i think contributor reputation becomes complicated here too.
normally reputation helps filter noise. that makes sense. trusted contributors should carry more influence over time.
but there is another risk hiding underneath that logic: over-trusted contributors can slowly shape the boundaries of acceptable knowledge inside the network. if the same sources dominate influence repeatedly, the Datanet may become efficient while quietly losing exploration capacity.
that is not corruption exactly.
it is gravitational consolidation.
and once a system consolidates too much, new information struggles to compete against established probability structures. unfamiliar contributions get treated as anomalies. minority datasets lose visibility. unconventional insights fail influence scoring because they do not align strongly enough with existing model behavior.
which creates a terrifying possibility:
the network becomes resistant to surprise.
that would be catastrophic for intelligence.
real intelligence systems need the ability to absorb contradiction without instantly suppressing it. they need room for uncertain knowledge, emerging domains, weird edge discoveries, culturally specific context, and information that initially appears low-confidence before later proving transformative.
history is full of truths that once looked statistically weak.
if Datanets only reward immediate alignment with dominant model behavior, they may accidentally train ecosystems that become excellent at preserving consensus and terrible at discovering reality shifts.
and honestly, that danger feels very real in AI economics.
because reinforcement loops are profitable.
stable outputs reduce friction. predictable models scale better. repeated patterns improve optimization efficiency. dominant datasets become cheaper to reuse than constantly sourcing fresh, independent, high-quality material.
the infrastructure naturally wants convergence.
which means divergence must become intentional.
maybe OpenLedger eventually needs mechanisms that protect informational diversity the same way biological ecosystems protect genetic diversity. not because every contribution is equally useful, but because over-optimization creates fragility.
monocultures scale beautifully until conditions change.
then they fail all at once.
that applies to crops.
markets.
civilizations.
and probably AI models too.
the deeper i think about Datanets, the less they feel like storage systems and the more they feel like ecological systems. contributors behave like environmental pressures. attribution behaves like nutrient flow. models consume signals. inference redistributes influence. reputation systems determine which informational organisms survive long enough to reproduce themselves across future training cycles.
and just like ecosystems, balance matters more than maximum extraction.
because a perfectly optimized ecosystem can become incredibly vulnerable if all resilience disappears underneath efficiency.
that is why recursive synthetic reinforcement keeps bothering me.
not because synthetic data is automatically bad. some of it will absolutely become necessary. some of it may even outperform human-generated material in specific domains.
the issue is closed-loop dominance.
if the majority of future model intelligence comes from recursively reinforced machine consensus, then eventually models stop mapping reality and start mapping prior model behavior.
the distinction sounds abstract until the errors compound.
then suddenly the ecosystem becomes extremely persuasive while slowly disconnecting from the world it claims to describe.
and maybe that is the future Datanets will have to defend against most carefully:
not malicious attacks from outside —
but comfortable consensus forming inside.
#OpenLedger $OPEN #open @OpenLedger