
I have spent the last few weeks digging deep into the infrastructure layer of decentralized AI, and I keep coming back to one conclusion: the industry is fundamentally broken. Most projects are just scraping data and calling it "AI," but I believe that true innovation requires a transparent settlement layer. This is why I am paying such close attention to what @OpenLedger is building right now.
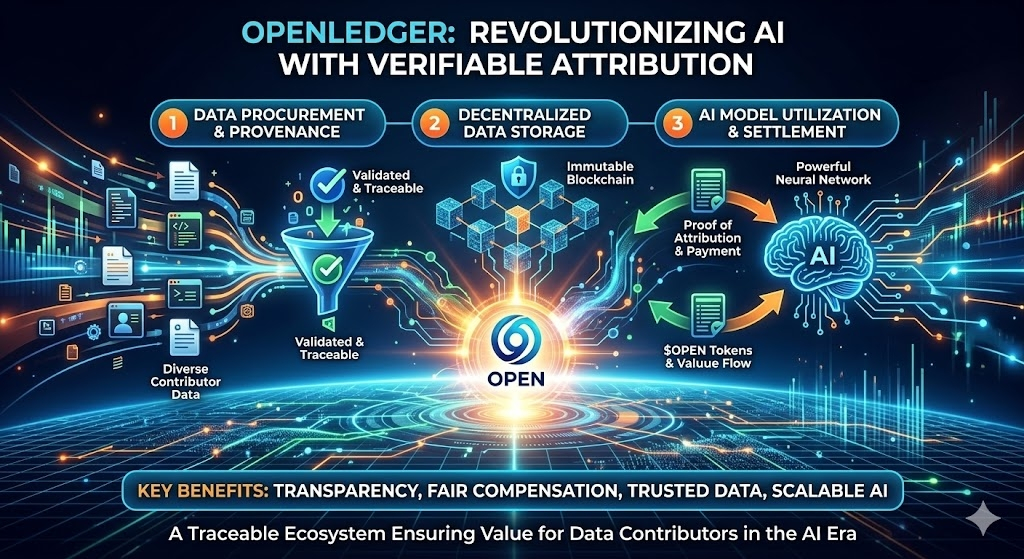
I see a massive shift occurring as the market moves away from "opaque data scraping" toward "verifiable attribution." In my view, the real moat for an AI model isn't just the algorithm—it is the ability to prove where the data came from and ensure value flows back to the contributors. $OPEN is positioning itself as that critical infrastructure, and that is a narrative I can get behind.

I have been monitoring the volume patterns closely, and I’m genuinely impressed by the stability of this project’s ecosystem during recent market fluctuations. When I look at the current development roadmap, I see a team that is focused on building long-term architecture rather than just chasing hype. It is rare to find a project that balances technical depth with a clear vision for user contribution in this space.
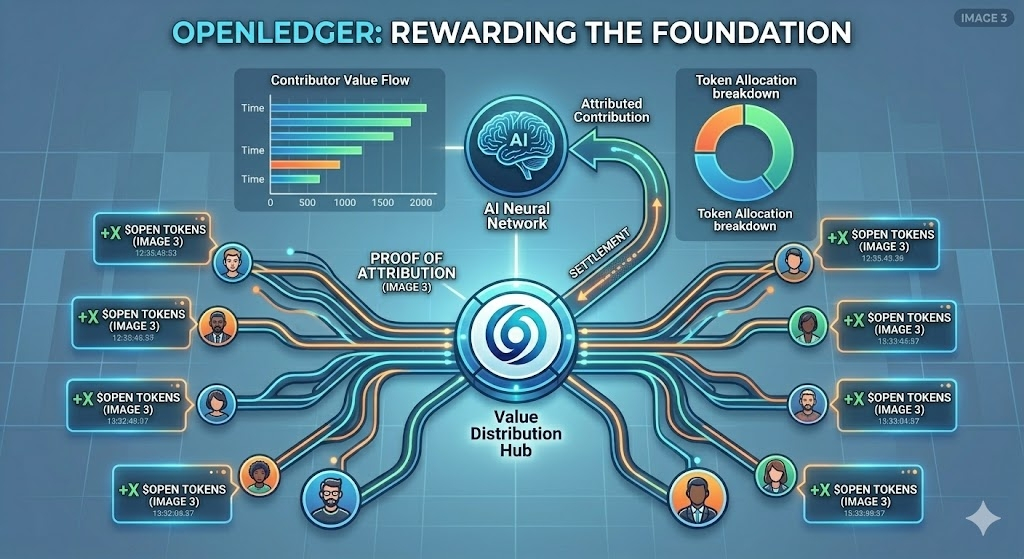
I am curious to see if this "attribution-first" design becomes the standard requirement for all enterprise-grade AI models in the near future. As we continue to see demand for high-quality, verifiable data, I believe the infrastructure provided by #OpenLedger will become an essential part of the Web3 landscape.
I would love to hear your thoughts. Do you think we will see established AI labs adopting this kind of attribution model this year, or will they try to build proprietary versions instead? Drop your take in the comments below—I am here to discuss this with you.
