


There’s a moment that doesn’t look like much on the surface but stays with you longer than any flashy demo. I experienced one of those while exploring @OpenLedger $OPEN A minor adjustment in a single dataset barely noticeable ended up influencing outputs across multiple models. No alarms, no dramatic spikes, just a subtle chain reaction quietly shaping results.
That moment changed how I looked at the system.
In most AI environments, what happens behind the scenes is largely invisible. Data flows through pipelines, models train, outputs appear but the origin of influence is often buried. Contributions dissolve into abstraction. $OPEN however, approaches this differently. It exposes the journey. Every dataset, every transformation, every inference carries a traceable footprint.
And that changes everything.
Transparency in AI is often discussed, but rarely implemented in a way that feels tangible. What stood out to me with OpenLedger wasn’t just that transparency exists it’s that it’s usable. You can actually follow the lifecycle of data step by step. You’re not guessing where an outcome came from; you can see it. That level of clarity introduces a new kind of confidence, one that doesn’t rely on trust alone but on verifiable structure.
The implication is deeper than it first appears.
When contributors know their work is visible and attributable, behavior shifts. Data isn’t just submitted it’s curated. Models aren’t just trained they’re refined with intent. Over time, this creates a compounding effect where quality improves organically, not because of enforcement, but because incentives are aligned.
This is where @OpenLedger separates itself from the broader AI narrative.
Most projects focus on capability faster models, larger datasets, more impressive outputs. OpenLedger focuses on accountability. Every contribution is linked, measurable, and potentially rewarded. That reframes participation entirely. It’s no longer abstract involvement; it’s ownership with traceable impact.
From an economic perspective, this is significant. The individuals who contribute to AI systems researchers, data curators, niche experts have historically been invisible in the value chain. Their input fuels the system, but the upside rarely reaches them. By embedding attribution into the architecture, OpenLedger introduces a model where contribution and reward are directly connected.
And that connection influences how the system evolves.
If contributors are incentivized fairly, they invest more effort. They spend time improving datasets, validating outputs, and iterating thoughtfully. This isn’t a theoretical advantage it’s a practical one that compounds over time. Systems built on aligned incentives tend to outperform those driven purely by scale.
But the impact isn’t limited to contributors.
For users, institutions, and even regulators, traceability introduces a new level of trust. Decisions made by AI systems are no longer opaque. They can be examined, understood, and, if necessary, challenged. In a world where AI is increasingly integrated into critical processes, that level of accountability isn’t optional it’s essential.
Interestingly, this shift toward transparency also intersects with another idea emerging within the OpenLedger ecosystem: vibecoding.
As someone who operates more on the trading side than the development side, this concept resonates. There’s a persistent gap between having an idea and turning it into something functional. Many trading strategies never leave the notes app not because they lack merit, but because implementation is complex.
Vibecoding aims to close that gap.
Instead of requiring deep technical expertise, it allows users to describe what they want to build and have the system handle the heavy lifting. The appeal isn’t in generating code snippets it’s in producing tools that actually work in real environments. Tools that connect to data sources, handle edge cases, and remain stable under pressure.
If executed well, this could redefine who gets to build.
But it also introduces a new dynamic. When building becomes easier, the barrier shifts. The advantage no longer lies in technical ability alone, but in the quality of ideas and the discipline to test them. Markets, especially, have a way of exposing weak assumptions quickly. Speed of creation doesn’t eliminate risk it can amplify it.
That’s why caution matters.
Any tool generated through vibecoding still needs validation. Logic must be tested, assumptions challenged, and performance verified under real conditions. The responsibility doesn’t disappear it just moves.
Stepping back, what OpenLedger is building feels less like a product and more like infrastructure. It’s not trying to dominate attention; it’s trying to solve a foundational problem: how to align value creation in AI with the people who contribute to it.
That’s not a short-term narrative. It’s a long-term positioning.
In a space where many projects rise quickly and fade just as fast, what tends to endure is infrastructure that quietly works. Systems that don’t rely on hype, but on utility. OpenLedger appears to be aiming for that category where ownership, attribution, and transparency are not features, but fundamentals.
And that brings me back to that initial moment the small dataset change that rippled through multiple models.
It wasn’t dramatic. It wasn’t designed to impress. But it revealed something important: when influence is visible, understanding follows. And when understanding exists, trust has a place to grow.
That might not be the loudest innovation in AI right now.
But it could turn out to be one of the most important.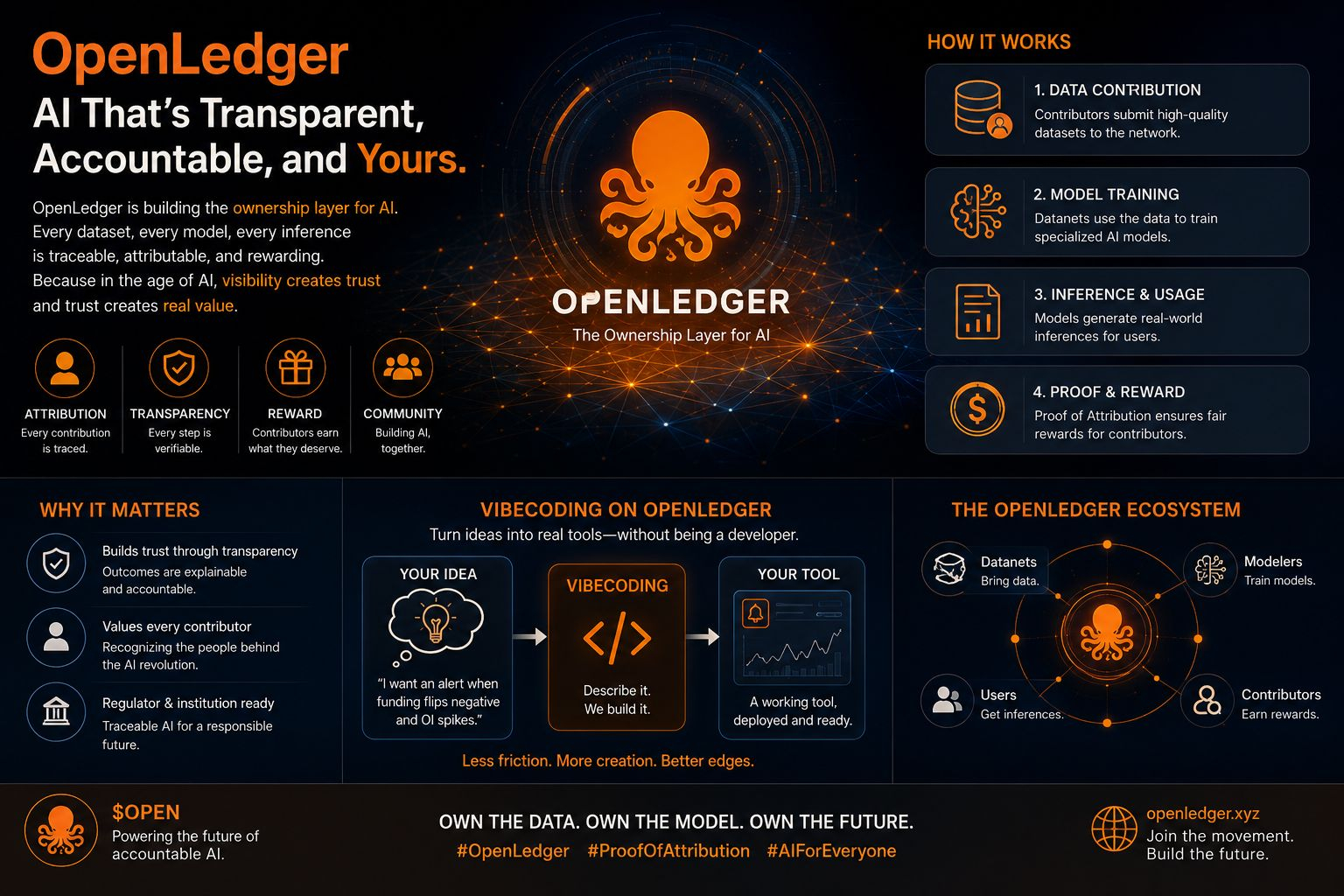
#OpenAIToConfidentiallyFileForIPO #OpenLedger #VitalikButerinDetailsEthereumPrivacyUpgrades