Am început să observ OpenLoRA dintr-o întrebare foarte plictisitoare.
Nu este vorba despre cât de inteligent va fi agentul AI?
Nu este vorba despre cum va debloca OpenLedger economia de date?
Ci mai degrabă: dacă în viitor vor exista mii de modele specializate, cine le va folosi cu adevărat suficient de mult pentru a le menține în viață?
Sună puțin descurajant. Dar crypto m-a învățat o lecție destul de dureroasă: crearea ofertei este întotdeauna mai ușoară decât crearea cererii. Crearea unui token este mai ușoară decât crearea unei utilități. Crearea unui activ este mai ușoară decât găsirea unui motiv pentru ca alții să revină și să îl folosească în fiecare zi. GameFi a avut prea multe item-uri fără jucători reali. DeFi a avut prea multe vault-uri care doar supraviețuiau din emisii. AI crypto poate repeta complet această greșeală, doar că de data aceasta, ceea ce se află în depozit nu sunt NFT-uri sau vault-uri, ci modele mici numite „specializate”.
La început, am fost pe punctul de a crede în narațiunea asta prea repede.
AI-ul specializat sună foarte rezonabil. Un model pentru auditul smart contract-urilor. Un model pentru cercetarea trading-ului. Un model pentru fluxurile de lucru legale. Un model pentru fiecare comunitate cu date proprii. OpenLedger are Datanets pentru a aduna date specializate, ModelFactory pentru fine-tuning, Proba de Atribuție pentru a recunoaște contribuțiile. Pe hârtie, totul se leagă destul de frumos.
Dar frumusețea pe hârtie adesea omite o întrebare esențială: modelul ăsta este apelat suficient de des?
OpenLoRA m-a făcut să mă opresc exact în acest punct.
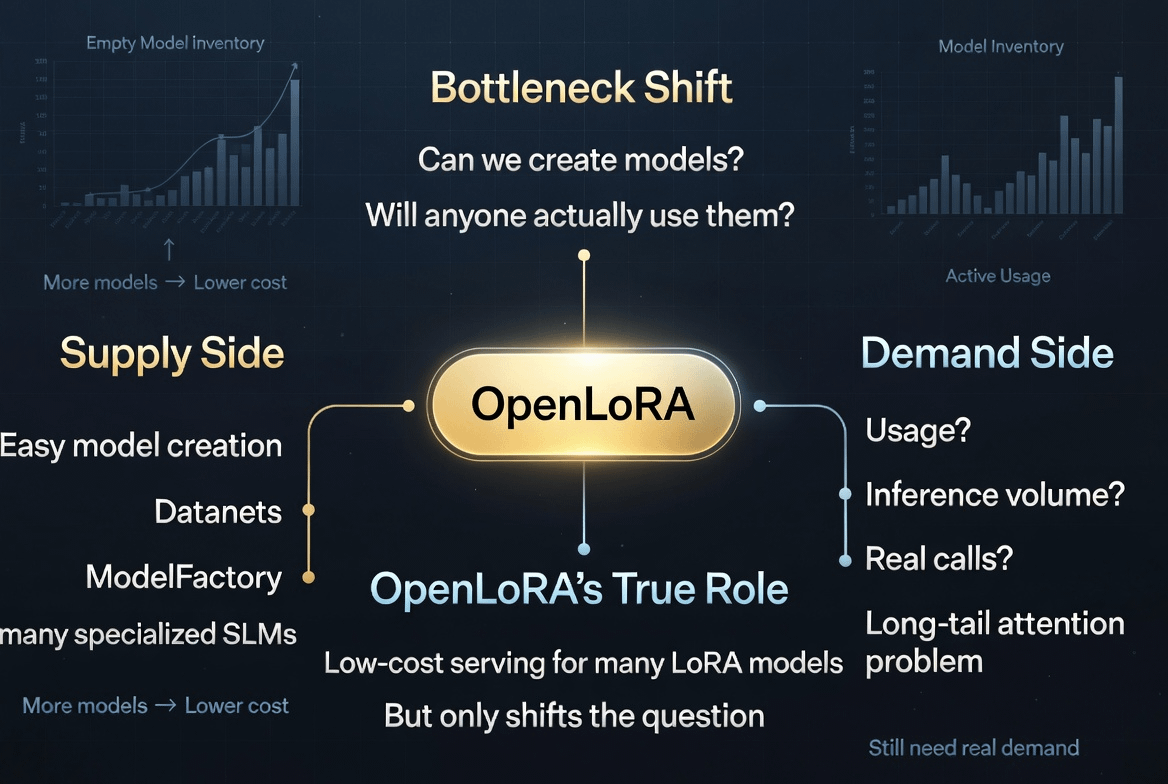
LoRA poate fi înțeles simplu ca un strat de ajustare ușoară aplicat pe modelul de bază, în loc să fie nevoie să antrenăm un model mare de la zero. OpenLoRA în whitepaper este descris ca un sistem multi-tenant pentru a servi modelele LoRA fine-tuned cu overhead scăzut. Acest punct de date poate părea sec, dar este important deoarece OpenLedger nu are nevoie doar să creeze modele. Trebuie să facă astfel încât multe modele mici să poată fi rulate cu un cost suficient de scăzut.
În trecut, am privit acest detaliu ca pe o optimizare a infrastructurii. Acum cred că este mai mult un test.
Când costul de servire este încă prea mare, avem mereu o justificare: AI-ul specializat nu a apărut pentru că infrastructura este scumpă, pentru că implementarea este dificilă, pentru că modelele mici nu au suficientă capacitate de a-și acoperi costurile. Dar dacă OpenLoRA reduce acea frecare, întrebarea reală începe să apară: există o cerere reală pentru AI-ul long-tail sau doar o ofertă long-tail?
Aici este locul unde văd OpenLoRA mai interesant decât partea tehnică a sa.
Nu dovedește că OpenLedger va avea o economie AI sustenabilă. Doar mută bottleneck-ul într-un loc mai greu de evitat. De la "poate rula multe modele mici?" la "care modele mici au utilizare reală?" De la "costul de servire este prea mare?" la "volumul de inferență este suficient de mare pentru a oferi recompense semnificative?" De la "cine creează modelele?" la "cine revine să apeleze acel model a doua, a zecea, a o mie oară?"
Pentru că în OpenLedger, un model specializat are cu adevărat viață economică doar când este folosit. Inferența nu este doar răspunsul AI-ului. Este locul unde se plătește taxa, unde atribuția are date de măsurat, și unde recompensa are șansa să revină la contributor. Dacă utilizarea este slabă, Proba de Atribuție poate fi logic corectă, dar recompensa pentru contributorii de date poate fi prea mică pentru a schimba comportamentele. Justiția pe diagramă nu se transformă automat în stimulente în viața reală.
Aici este un aspect pe care cred că mulți vor trece cu vederea.
Oamenii adoră să vorbească despre "deblocarea lichidității pentru date și modele". Dar lichiditatea nu apare doar pentru că un activ este definit. Ea apare când sunt oameni care vor să utilizeze, să plătească taxe, să revină. Dacă nu, ecosistemul poate avea foarte multe adaptoare, multe modele, multe dashboard-uri frumoase, dar sunt ca o piață deschisă toată noaptea fără destui cumpărători.
Nu spun asta pentru a nega OpenLoRA. Dimpotrivă, acesta este motivul pentru care cred că merită observat. O infrastructură bună nu rezolvă doar problemele vechi. Ea dezvăluie problemele următoare. Dacă OpenLoRA ajută modelele mici să fie mai ieftine de rulat, atunci OpenLedger nu va mai fi testat prin numărul de modele create. Va fi testat prin calitatea cererii din spatele acelor modele.
Dezvoltatorii le integrează în fluxul de lucru cu adevărat?
Agentul le apelează pentru că sunt mai utile decât opțiunile standard?
Contributorii consideră recompensele suficient de reale pentru a continua să aducă date bune în Datanets?
Sau toate acestea creează doar un nou strat de inventar pentru piața de evaluare înainte ca utilitatea să apără?
Aici este locul unde văd OpenLoRA conectându-se la o întrebare mai mare despre AI-ul crypto. Poate că următoarea etapă a acestei industrii nu va lipsi de inteligență. Va lipsi un mecanism pentru a ști care inteligență merită să existe. Pe măsură ce crearea și servirea modelului mic devine mai ușoară, raritatea nu mai stă în numărul de modele. Ea stă în atenție, distribuție, încredere și utilizare reală.
Așadar, OpenLoRA nu este "răspunsul final" la @OpenLedger .
Este ca și cum am deschide un robinet într-un sistem de țevi. Înainte, oamenii puteau discuta mult timp dacă apa poate curge sau nu, pentru că robinetul era prea strâns. Când robinetul se deschide, întrebarea devine mult mai clară: există cu adevărat apă în țeavă și ajunge ea la locul unde este nevoie?
Dacă există, OpenLoRA ar putea fi unul dintre detaliile tăcute care ajută AI-ul specializat long-tail să devină o economie reală.
Dacă nu, inteligența long-tail va deveni doar un depozit interminabil de modele pe care nimeni nu le folosește.
Și cred că acesta este testul care merită observat în OpenLedger. Nu este vorba despre câte modele pot fi create care sună bine pe hârtie, ci despre câte modele pot fi apelate suficient de des pentru ca datele din spatele lor să nu fie doar înregistrate, ci să aibă cu adevărat un flux de valoare care să revină.