There was a moment a few months ago when I was trying to move assets between networks while als0 testing an AI tool at the same time. Nothing about the process was unusually difficult, but everything started slowing down once activity increased. Transactions stayed pending longer than expected, confirmations became inconsistent, and even simple interactions felt heavier than normal.
I remember sitting there thinking about how quickly systems begin showing their weaknesses once too many things happen at once.
And honestly, that moment stayed in my mind longer than the delay itself.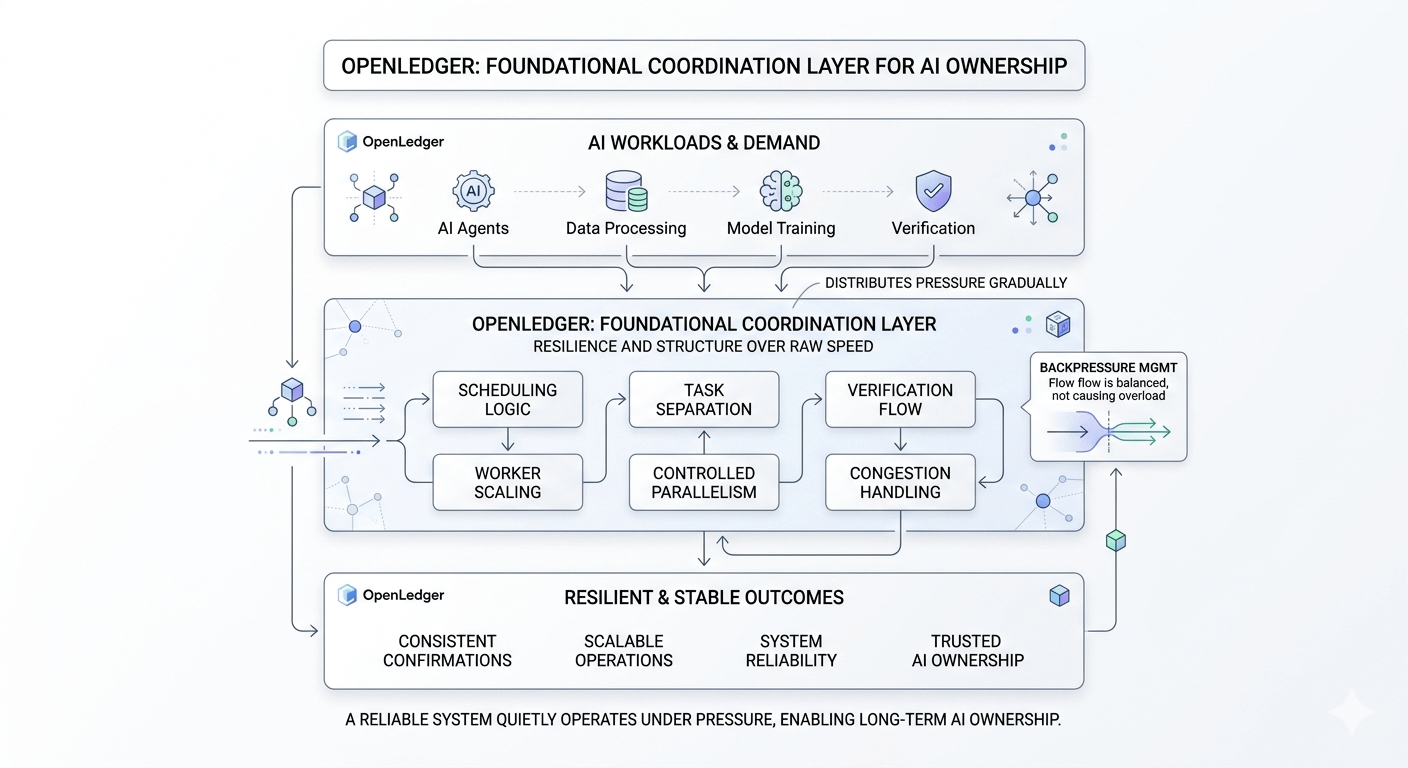
Because after spending years around crypto infrastructure, I have started realizing that the real Challenge is rarely about making something work under normal conditions. Most systems can do that. The difficult part is keeping everything coordinated when demand becomes unpredictable and multiple workloads start competing for attention simultaneously.
What I noticed over time is that many blockchain discussions still focus mostly on speed, throughput, or surface-level performance metrics. But from a system perspective, those numbers alone never tell the full story. A network can feel fast during quiet periods and still become fragile once pressure starts building internally.
I usually think about it like a large airport during holiday season.
When passenger traffic is low, operations appear smooth almost everywhere. But once thousands of people arrive at the same time, the real quality of the system becomes obvious. Security checks, baggage handling, scheduling, routing, and staff coordination all need to function together carefully. If one section becomes overloaded, delays begin spreading across the entire airport very quickly.
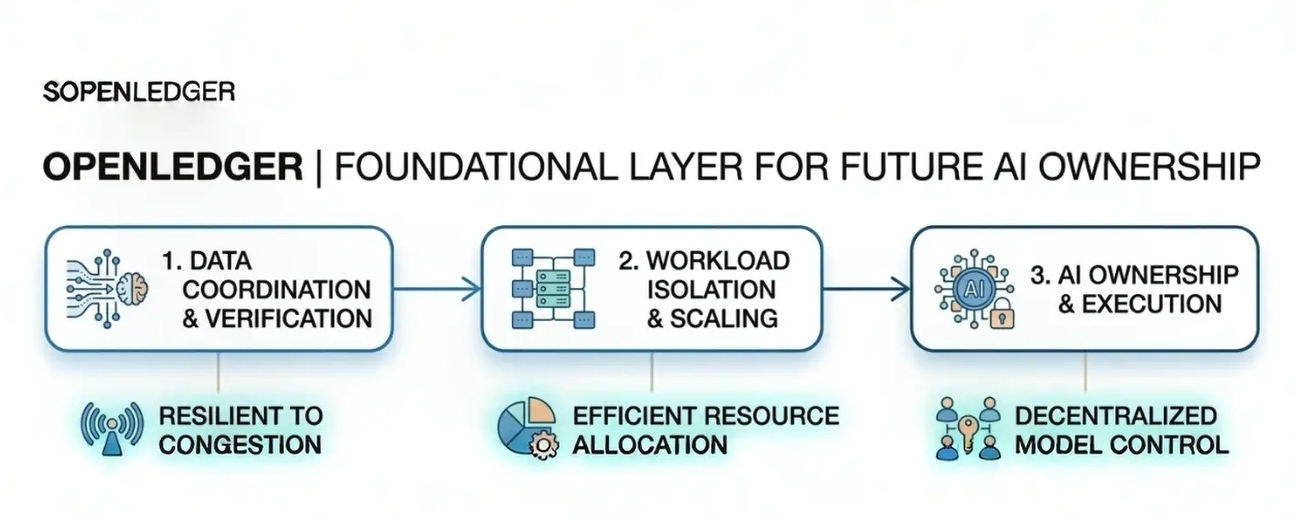
The more I observe AI infrastructure developing alongside blockchain systems, the more important this coordination layer feels tO me.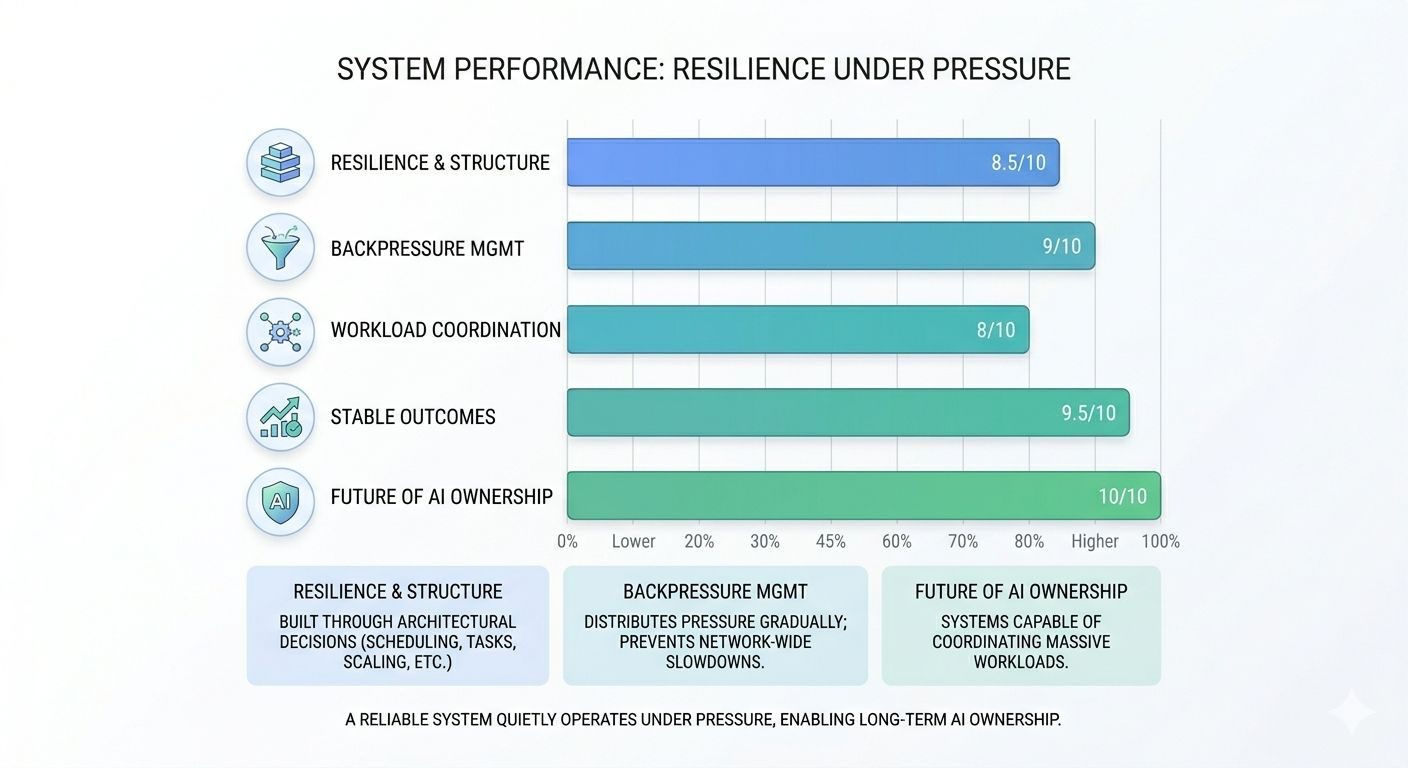
AI workloads are constant by nature. Verification, data processing, scheduling, execution, and resource allocation happen continuously in parallel. And if the underlying infrastructure is not designed carefully, congestion does not stay isolated for long. It spreads.
That is partly why @OpenLedger caught my attention.
What interests me more is not the narrative around AI itself, but how OpenLedger seems to think about the structure supporting those workloads. The design appears focused on coordination and workload organization rather than simply pushing for raw activity or higher throughput numbers.
And personally, I think that matters a lot more than people realize.
Because resilient systems are usually built quietly through architecture decisions most users never notice directly. Scheduling logic. Task separation. Verification flow. Worker scaling. Controlled parallelism. Congestion handling. These things may sound technical on the surface, but in practice they determine whether a network stays usable once demand becomes chaotic.
One thing I pay attention to closely is backpressure.
In weaker systems, once incoming activity exceeds processing capacity, every part of the environment starts slowing down together. But stronger systems distribute pressure gradually before instability spreads across the entire network.
That difference may not seem dramatic during calm periods, but during heavy activity it changes everything.
Good infrastructure rarely looks exciting when it functions properly. Most people barely think about it at all. It simply continues operating in the background while everything around it becomes more complex and unpredictable.
And honestly, the more I study projects focused on long term infrastructure, the more I feel the future of AI ownership will depend less on hype and more on systems capable of coordinating massive workloads without losing stability along the way.
A reliable system is not the one making the most noise. It is the one quietly continuing to work when pressure finally arrives.