
The more I researched @OpenLedger after its mainnet launch, the more I realized this project is targeting a problem much bigger than most people in crypto currently understand. At first glance, it looks like another AI-focused blockchain trying to ride the AI narrative cycle, but the deeper I went into its thesis, the more obvious it became that OpenLedger is not trying to become just another “AI coin.” It is trying to challenge the economic structure behind modern artificial intelligence itself.
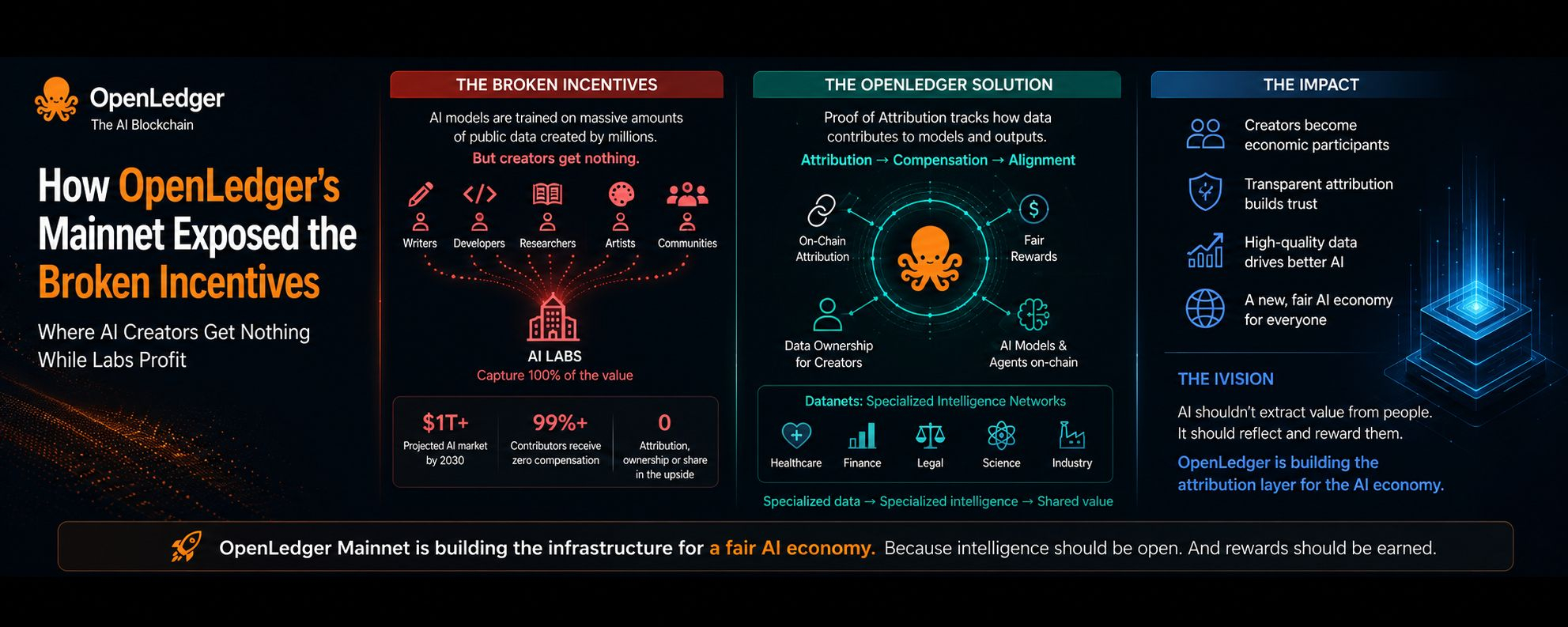
For years, the AI industry has operated through a system where value extraction massively outweighs value distribution. The largest AI companies are building trillion-dollar ecosystems using datasets created by millions of ordinary people across the internet — writers, developers, artists, researchers, communities, open-source contributors, and everyday users constantly generating data without compensation. Every major AI model today is trained using enormous amounts of publicly available information, yet once these systems become commercially successful, almost none of the original contributors participate in the upside. The labs scale, the valuations rise, and the infrastructure becomes more powerful, but the creators behind the data remain economically invisible. That imbalance is exactly what OpenLedger forced me to think about differently.
What makes #OpenLedger interesting is that it focuses on attribution instead of simply chasing AI hype. The project’s “Proof of Attribution” framework is designed to track the relationship between datasets, contributors, AI models, and generated outputs. In simple terms, OpenLedger wants to create infrastructure where the people contributing valuable data can eventually become economically connected to the intelligence their contributions help create. And honestly, the implications of that idea are massive. Because once attribution becomes transparent, compensation can also become programmable. The more I studied the AI landscape, the more it started reminding me of early Web2 economics where users create value, platforms aggregate value, and corporations capture most of the upside while contributors slowly disappear into the background. Modern AI appears to be accelerating that same structure at an even larger scale.
One of the most important parts of OpenLedger’s vision is its “Datanets” model. Instead of relying purely on giant generalized models trained on chaotic internet-scale information, OpenLedger pushes the idea of domain-specific intelligence ecosystems such as healthcare datasets, financial intelligence networks, legal research systems, scientific communities, and specialized industry knowledge hubs. The logic is simple: specialized data creates specialized intelligence, and specialized intelligence often becomes far more valuable than generic outputs. The important difference is that OpenLedger wants these ecosystems to become economically participatory instead of centrally extractive. Because in the long run, the future AI economy may not be controlled by whoever builds the biggest model — it may be controlled by whoever owns the highest quality proprietary data.
At the same time, I do not think this problem is easy to solve. Tracking attribution inside AI systems is incredibly difficult because neural networks do not function like transparent databases. Outputs emerge probabilistically from layered systems trained across massive datasets, making it extremely complex to trace how individual pieces of information influence generated results. That is why I think $OPEN execution matters far more than its narrative. Still, the project exposed something extremely important: the modern AI economy is built on massive amounts of collective human intelligence, yet almost none of the people contributing that intelligence participate meaningfully in the upside. And eventually, that imbalance is going to become impossible to ignore.