Most people experience AI at the very end of the process.
They type something into a box, wait a second or two, and get a response. Maybe it writes a paragraph. Maybe it answers a technical question. Maybe it summarizes a document or helps an agent complete a task. From the outside, it feels simple.
But nothing about that answer is simple.
Behind it is a long trail of work: data collected and cleaned, examples labeled, models trained, prompts tested, systems tuned, and tools connected. Some of that work is done by engineers. Some of it comes from researchers, creators, companies, open communities, and ordinary users who left useful knowledge scattered across the web. By the time the model responds, most of those contributions have vanished from view.
That disappearance is becoming a problem.
AI is no longer just an interesting tool people experiment with. It is becoming part of how businesses operate, how software is built, how research is done, and how digital agents make decisions. As AI becomes more valuable, the question underneath it becomes harder to avoid: who actually helped create that value?
This is the space OpenLedger is trying to enter.
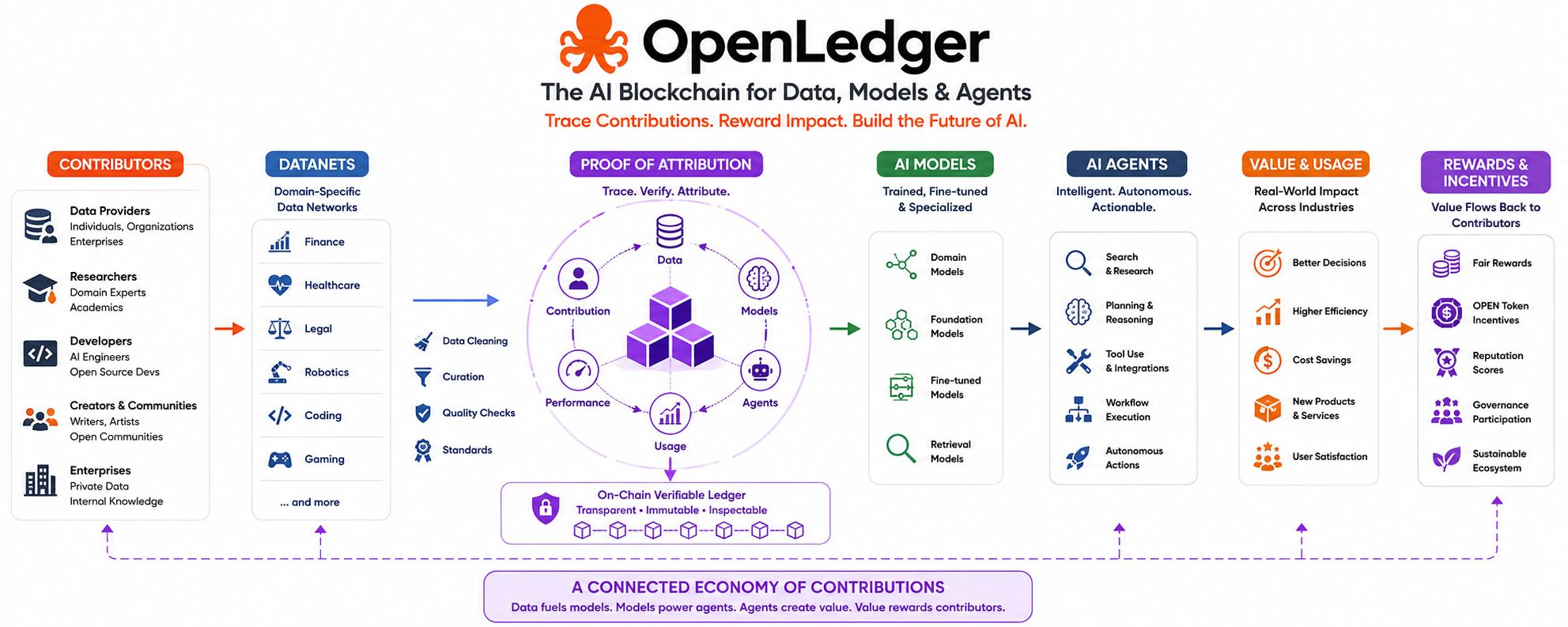
OpenLedger presents itself as an AI blockchain for data, models, and agents. That description can sound technical, even a little cold, but the idea underneath is easy to understand. OpenLedger is trying to make AI contributions visible. If data helps train a model, if a model improves an application, or if an agent creates value, there should be a way to trace that contribution and reward it.
That may sound obvious. In practice, it is not how most AI systems work today.
A lot of AI value is created inside closed pipelines. Data goes in. A model comes out. The final product may become extremely valuable, but the original sources of that value are often difficult to identify. A creator may not know whether their work shaped a model. A company may not know how much its dataset improved performance. A community may contribute useful knowledge without ever being credited. Even developers can struggle to understand which inputs made their models better.
OpenLedger is built around the belief that this should change.
One of its main ideas is the Datanet. A Datanet is basically a network for organizing data around a specific topic or use case. Instead of treating all data as one giant pile, OpenLedger imagines more focused pools of information: data for finance, healthcare, law, robotics, coding, gaming, agents, or any other field where AI needs deeper knowledge.
That distinction matters more than it first appears.
General AI models are useful because they know a little about many things. But the next wave of valuable AI will likely depend on models that know specific things well. A legal model needs trustworthy legal material. A medical model needs carefully reviewed medical data. A trading agent needs timely and reliable market information. A customer-support model needs product-specific knowledge. In each case, the quality of the data matters more than the amount.
This is where OpenLedger’s approach becomes interesting. It is not only asking people to contribute data. It is asking how those contributions can be measured.
The project uses the idea of Proof of Attribution. In simple terms, Proof of Attribution is a way to connect AI outputs back to the data and other inputs that helped produce them. If a dataset improves a model, that improvement should not disappear into the background. It should be recorded. If a contributor provides something valuable, that value should be recognized.
This is easy to say and very hard to do.
AI models do not work like ordinary databases. They do not pull one exact sentence from one exact file every time they answer. Training changes the model’s internal patterns. Fine-tuning adjusts its behavior. Retrieval systems add outside context. Agents combine models with tools, memory, and actions. A single useful result may come from many layers working together.
So attribution in AI cannot be as simple as pointing to one source and saying, “This caused that.”
It has to be more careful. It has to look at influence, quality, usage, model performance, and context. A small dataset might matter a lot if it teaches a model something rare. A large dataset might matter very little if it is noisy or repetitive. A contributor might not provide the most data, but they might provide the most useful data.
That is the kind of economy OpenLedger is trying to build.
The goal is not just to reward volume. That would create the wrong incentives. People would upload as much as possible, whether or not it helped. A real contribution economy has to reward usefulness. It has to encourage people to add data, models, and agents that actually improve the system.
This is where OpenLedger’s vision feels connected to a much larger shift in AI.
For years, the AI industry treated data as something that could be gathered quietly in the background. It was the raw material, but not always the thing people talked about. The spotlight went to the model, the interface, the demo, or the company behind it. Now that AI systems are becoming more powerful, the raw material is getting more attention.
People want to know what models were trained on. Creators want to know whether their work was used. Companies want to protect their private knowledge. Developers want cleaner data. Regulators want accountability. Users want systems they can trust.
OpenLedger does not solve all of that on its own. No single project can. But it is working on one important piece: creating a record of contribution.
That is where blockchain becomes useful in this context. Not because every AI project needs a token. Not because putting something “on-chain” automatically makes it better. The useful part is the shared record. If contribution history, reward logic, and governance decisions are recorded in a way that participants can inspect, the system does not depend entirely on private promises.
A closed platform can say it rewards contributors fairly. A verifiable network can try to show it.
There is a difference.
Still, the hard part is not the ledger itself. The hard part is deciding what deserves to be written into it. Bad data can be uploaded. Duplicate data can be dressed up as original. Low-quality contributors can try to game the reward system. A serious AI data economy needs filters, audits, penalties, and standards.
This is especially true for specialized domains. A healthcare Datanet cannot be treated casually. A legal dataset needs source discipline. A financial model needs freshness and accuracy. An agent that takes actions on behalf of users needs even more care. The more important the use case, the more important the quality of the contribution trail becomes.
Privacy is another major issue.
Some of the most valuable data in the world is also the most sensitive. Medical records, business documents, financial histories, customer interactions, internal logs — these cannot simply be placed in public view. A good attribution system has to prove contribution without exposing what should remain private. It has to separate verification from disclosure.
That balance will decide whether systems like OpenLedger can move beyond crypto-native communities into real AI infrastructure.
The agent layer makes this even more important. AI agents are different from chatbots because they do things. They can search, plan, call tools, execute workflows, and interact with software. Once AI systems begin taking action, people will care much more about where their decisions come from.
Which model did the agent use?
Which data shaped that model?
Which tool did it call?
Who built the agent?
Who gets rewarded when it performs well?
Who is accountable when it fails?
These are not abstract questions. They are the kind of questions that appear when technology moves from content generation into real operations.
OpenLedger’s broader idea is that data, models, and agents should not be isolated pieces. They should be part of a connected economy. Data supports models. Models power agents. Agents create usage. Usage creates value. Value can then flow back to the contributors who helped make the system useful.
That loop is the important part.
Without it, AI keeps repeating the same pattern: many people contribute, but only a few capture most of the upside. With it, there is at least a path toward a more distributed model of ownership. Not perfect. Not automatic. But more transparent than what exists today.
Of course, OpenLedger still has to prove itself.
The idea is strong, but execution will matter more than language. It needs real contributors, useful datasets, reliable attribution, active developers, and models that perform better because of the system. It also needs an economy that rewards actual use, not just speculation around the OPEN token.
That is the risk with any project sitting between AI and blockchain. The story can become bigger than the product. The token can become louder than the technology. The market can reward attention before the network proves real demand.
OpenLedger will be strongest if it avoids that trap.
The most convincing version of OpenLedger is not loud. It is practical. It helps someone build a better domain model. It helps a data contributor earn from work that would otherwise be invisible. It helps an agent developer show where their system gets its intelligence. It helps users trust AI outputs because the foundation is easier to inspect.
That is where the project could matter.
The future of AI will not only be about who has the biggest model. It will also be about who has the best data, the clearest rights, the strongest contribution networks, and the most trustworthy systems for tracing value. As models become easier to build and fine-tune, the advantage may shift toward those who can organize high-quality inputs and prove where they came from.
OpenLedger is aiming at that future.
It is trying to make AI less opaque without pretending the problem is simple. It recognizes that intelligence is not created by a model alone. It comes from a whole chain of human and machine contributions. Data matters. Curation matters. Training matters. Agents matter. Usage matters.
The question is whether those pieces can be connected in a way that is fair, useful, and verifiable.
That is the real promise of OpenLedger. Not just an AI blockchain. Not just another token economy. A possible framework for recognizing the work behind intelligence.
Because AI does not come from nowhere.
It is built from contributions.
And if those contributions are going to shape the next digital economy, they should not remain invisible.
