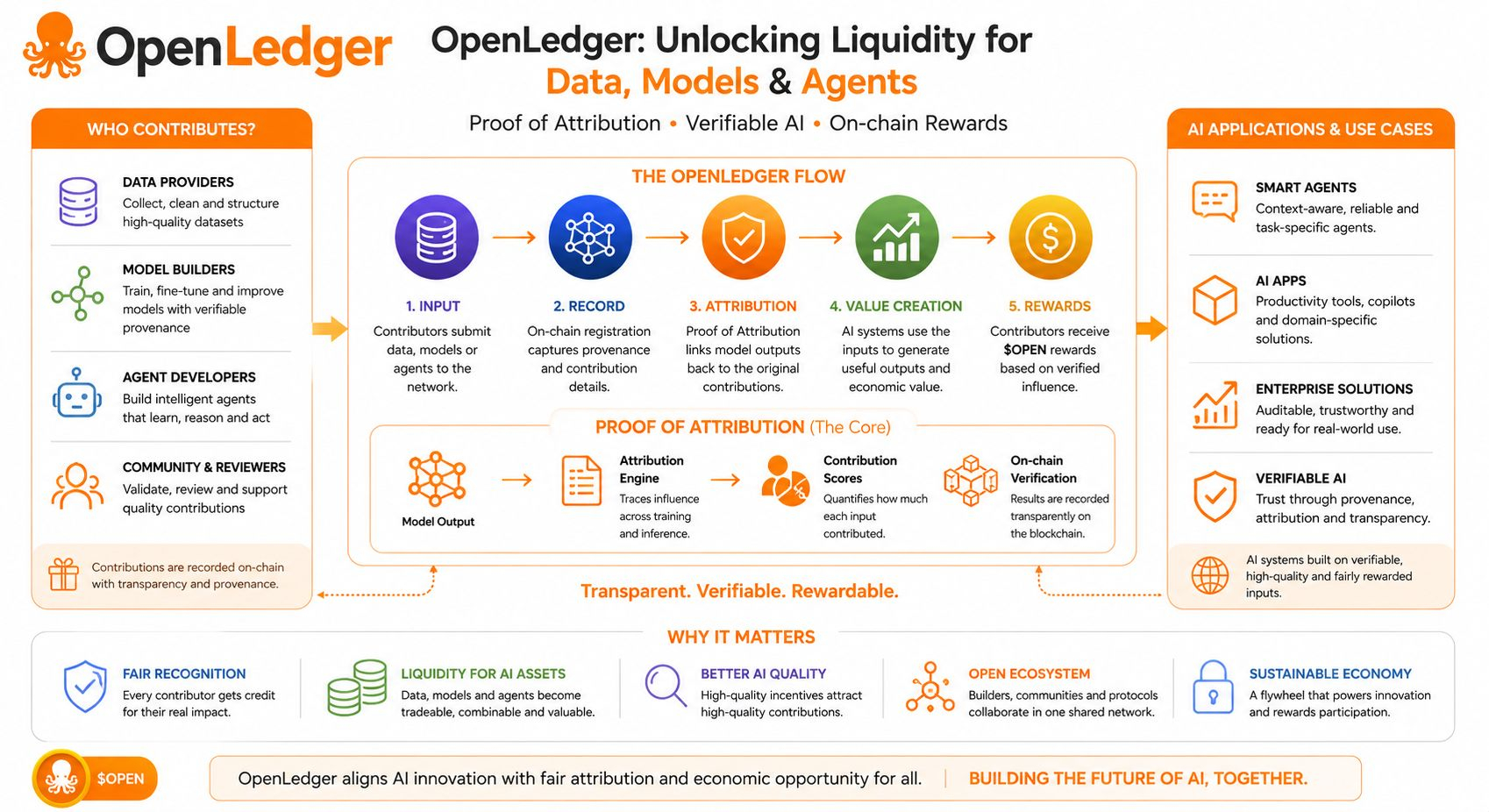
The first thing that stood out to me was not a flashy promise, but the way OpenLedger keeps circling back to a simple market question: who actually gets recognized when AI creates value? The project presents itself as an AI blockchain built to unlock liquidity across data, models, and agents, and that framing matters because it puts the hidden input layer of AI at the center of the story instead of treating it like background noise. It also shows up in the product surface: the project is openly leaning into AI participation, on-chain execution, and agent tooling rather than positioning itself as just another chain with an AI label attached.
That is where the real thesis starts. OpenLedger’s core mechanism is Proof of Attribution, a framework meant to connect model behavior back to the data that influenced it and then use that link for reward distribution. In the paper, the architecture is built around DataNets, where contributors assemble structured datasets, and models record training provenance so influence can be traced across inference. In plain language, the project is trying to turn AI contribution into something legible, not symbolic: if the data matters, the system should be able to show how it mattered.
I think that is a better angle than the usual “decentralized AI” pitch. Most of the market still talks about models as if the only scarce thing is compute or clever architecture, but OpenLedger’s own research argues that AI systems are still missing a widely adopted way to recognize or reward the people behind the data. That problem is bigger than fairness rhetoric. When contribution is invisible, the incentive to keep supplying high-quality, domain-specific data weakens. OpenLedger’s answer is to make data a first-class onchain asset inside the value chain, so the input is not just consumed; it can participate in the output’s economics.
What makes the project more interesting is that it is not pushing generic AI as a single blob. Its own writing makes a strong case for specialization, arguing that useful agents need domain-specific data, memory, and feedback loops rather than broad prompts and shallow examples. It also describes models that can be extended with RAG and MCP while staying auditable, which is a subtle but important point: the goal is not only to generate answers, but to keep the path from data to answer traceable. That matters in AI because the more context-aware a system becomes, the more people will care about where its knowledge came from and whether that knowledge can be checked.
There is a bottleneck hidden inside that ambition, and it is the part I would watch most closely. Attribution sounds elegant until you try to make it scalable and credible. The paper is careful here: it describes different approaches for smaller models and larger language models because the same attribution method will not work equally well across model sizes and output types. That is not a weakness in the pitch; it is the actual hard problem. If attribution is too loose, contributors will not trust the rewards. If it is too costly or too noisy, the system becomes more narrative than infrastructure.
The reward layer adds another interesting pressure point. OpenLedger’s studio says verified contributions can earn $OPEN, which means the project is not treating recognition as a vague social signal; it is tying contribution to an explicit incentive path. But tokens alone do not solve participation. The real test is whether contributors believe the measurement is fair enough to keep feeding the system, and whether builders believe the attribution is dependable enough to build on top of it. In these networks, the economics only work when the participants feel the accounting is believable.
That is why OpenLedger feels more substantive than a lot of AI-chain marketing. It is trying to price the invisible labor inside AI: data collection, dataset curation, model shaping, and agent behavior. The project also presents OpenCircle as a place for builders to launch verifiable AI systems, which fits the broader design idea: contribution, deployment, and verification should not be separated into different worlds. If OpenLedger executes well, the main change will not be “AI on blockchain” as a slogan. It will be a system where data and model contribution can be traced, reused, and economically acknowledged instead of disappearing into a closed pipeline. That is a much harder claim, but also a much more interesting one.