A few years ago, almost every conversation around digital infrastructure revolved around scale. Faster networks meant progress. Bigger cloud systems meant dominance. More compute meant competitive advantage. AI inherited that same logic almost automatically. The assumption became simple: the more intelligence a system could generate, the more valuable it would become.
That narrative still drives most of the market today because it is clean, familiar, and easy to price. Bigger models attract attention. Massive GPU clusters create headlines. New benchmarks get treated like proof of inevitability. But practical systems rarely mature around the thing people initially believe matters most.
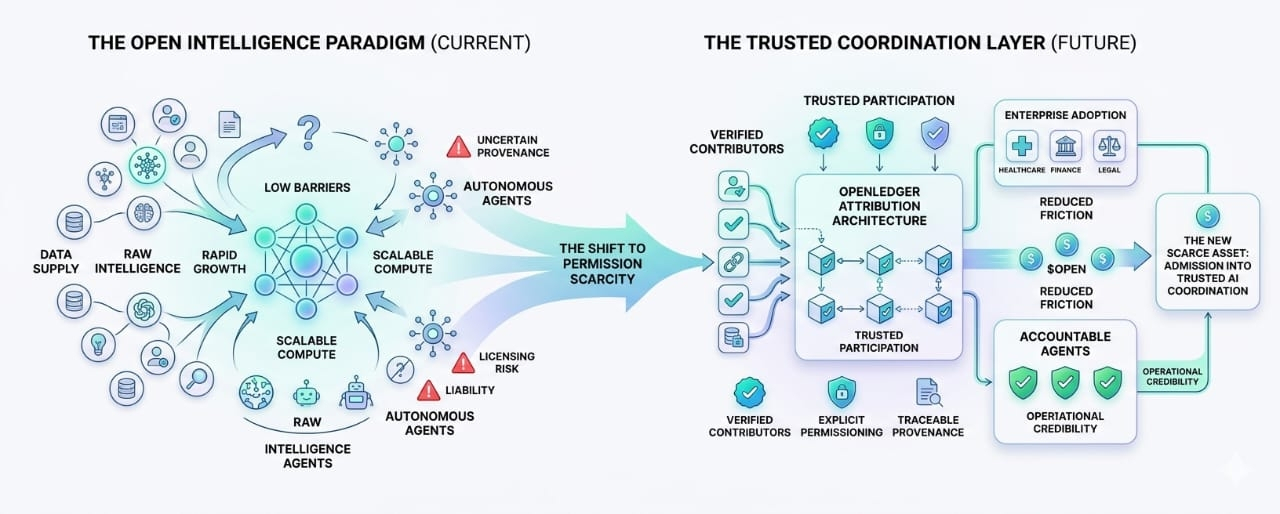
The internet did not ultimately become valuable because anyone could publish information. It became valuable because search engines could filter chaos. Social media did not stay fully open either. Ranking systems quietly became more important than publishing itself. Cloud infrastructure eventually stopped being just storage and compute. Identity management, trust layers, compliance systems, and access controls became some of the most valuable pieces of the stack.
AI may be heading toward the same kind of transition.
That is why OpenLedger feels more interesting than the usual “AI marketplace” description people attach to it.
Most explanations of OpenLedger follow a familiar crypto pattern. Contributors provide data. Developers build models. Attribution systems track usage. Tokens coordinate incentives. On the surface, it sounds like another decentralized marketplace trying to connect suppliers and builders through economic rewards.
But the more I think about real-world AI adoption, the less convinced I am that marketplace dynamics are actually the core issue.
The harder problem may not be matching supply with demand.
It may be deciding who deserves to participate in the first place.
That sounds subtle until you move outside consumer AI.
If someone uses an image generator and gets a weird result, nobody cares very much. A distorted anime face or an extra finger is mostly harmless. But once AI systems begin touching financial workflows, healthcare processes, legal review, insurance routing, compliance systems, customer verification, or internal enterprise operations, the environment changes immediately.
Suddenly nobody wants experimental answers anymore.
People start asking uncomfortable questions.
Where did this data come from?
Who trained this model?
Can the outputs be audited?
Can decisions be explained later?
Was the training data properly licensed?
Who becomes responsible if the system fails?
Those are not philosophical questions. They are operational survival questions.
And honestly, crypto communities sometimes underestimate how conservative large organizations really are. Engineers may love open experimentation. Legal teams usually do not. Procurement departments definitely do not. Enterprises care less about ideological openness than they care about reducing uncertainty.
That is where OpenLedger starts looking different to me.
Not because it promises intelligence. Intelligence itself is becoming less scarce than people expected. Open-source models keep improving faster than most forecasts predicted. Smaller specialized systems are getting surprisingly capable. Inference costs continue falling. Compute still matters, but it increasingly looks like something markets will eventually commoditize.
Trust does not commoditize the same way.
Trust scales slowly. Verification scales slowly. Permission scales slowly.
And that may become the real bottleneck.
OpenLedger’s entire attribution framework becomes much more important under that lens. Most people interpret attribution as a rewards mechanism. Contributors get compensated if their data influences model outputs. Fair enough. But attribution may matter more as infrastructure than as compensation.
Because attribution changes how credibility gets assigned inside AI systems.
The moment a network can reliably track where intelligence originated, it becomes capable of distinguishing between different levels of trustworthiness. Suddenly all datasets are not economically equal anymore. All contributors are not interchangeable anymore. All agents do not carry the same operational credibility.
That creates an entirely different kind of market structure.
Take two datasets.
One comes from uncertain public scraping with unclear ownership history. The other comes from verified contributors with explicit licensing rights, traceable provenance, and documented usage permissions.
Technically, both datasets may help train a model.
Economically, they are completely different assets.
One creates future liability risk. The other reduces operational friction before problems emerge.
That distinction matters far more than most people realize.
The same thing applies to AI agents. Everyone talks about autonomous agents like deployment is just around the corner. Maybe it is. But once agents begin handling financial operations, enterprise workflows, customer verification, contract execution, or sensitive internal systems, capability alone will not be enough.
No serious institution wants unknown agents touching critical infrastructure simply because they appear intelligent.
Competence without accountability creates risk.
And once risk enters the equation, permission becomes scarce.
Not everyone will qualify to deploy systems into sensitive environments. Not every model will pass enterprise standards. Not every contributor will carry equal trust weight. Not every agent will receive operational access.
That changes the economic layer entirely.
The scarce asset stops being intelligence itself.
The scarce asset becomes trusted participation.
This is the part I think markets are still struggling to price correctly.
People continue analyzing OpenLedger as if it lives entirely inside the old marketplace framework. Can it attract enough contributors? Can token incentives sustain activity? Can it compete with centralized AI providers?
Those questions matter, but they may not be the deepest questions anymore.
The more important issue is whether AI infrastructure is moving toward permission-based economics.
Because large systems almost always evolve this way eventually. Open environments sound efficient in theory, but scale introduces noise, abuse, uncertainty, manipulation, and legal risk. Over time, filtering becomes more valuable than openness itself.
Payments evolved this way. Identity systems evolved this way. Financial infrastructure evolved this way. Even social platforms quietly built trust hierarchies despite constantly talking about openness.
AI may follow the same path.
And if it does, OpenLedger’s attribution architecture starts looking less like a simple rewards engine and more like a coordination layer for economic credibility.
That does not mean the project automatically succeeds.
There are real risks here.
Permission systems can become gatekeeping systems surprisingly fast. Once trust status carries economic value, governance becomes political. Who decides what qualifies as trustworthy? Who controls reputation? Can influence become centralized? Can token incentives distort credibility systems?
Those are legitimate concerns.
There is another major risk too. Useful infrastructure does not automatically create valuable tokens. Crypto has repeatedly failed to separate protocol utility from token value capture. Plenty of technically impressive systems never translated into sustainable economic demand for their native assets.
Enterprise adoption timelines are also much slower than crypto markets usually expect. Even if attribution and permission infrastructure become critically important, companies may still prefer traditional vendors simply because centralized accountability feels safer and easier to understand.
But even with those uncertainties, OpenLedger still feels directionally important.
Because the market may still be asking the wrong question.
Most discussions continue focusing on whether OpenLedger can become a successful AI marketplace.
That framing already feels outdated to me.
The more important question is whether AI systems are entering a stage where trusted access becomes more economically valuable than raw intelligence supply.
Because if that transition happens, attribution stops being a side feature.
It becomes infrastructure.
And once infrastructure starts managing trusted participation, those systems tend to become extremely sticky. Organizations rarely abandon trust layers once operational dependency forms around them.
That is why OpenLedger feels more significant than the usual token narrative suggests.
Maybe $OPEN is not simply pricing AI activity.
Maybe it is pricing admission into trusted AI coordination itself.
And if permission becomes the scarce layer of the AI economy, that could end up being far more valuable than the market currently understands.
