

What kept bothering me this time was not OpenLedger's PoA. Not Datanet curation either. Worse, actually. More boring. Which usually means worse.
Model drift.
Not the lazy "models have versions" line people throw around when they want partial credit for noticing AI stacks change. I mean the OpenLedger version of it. One model path stays live long enough that downstream agents start treating it like stable policy. Then the workflow changes what the output is supposed to mean. New Datanet scope. New adapter. New risk threshold. Maybe a second review. Maybe a trading or residency constraint that used to live in cloud config and get waved through, and now suddenly matters because somebody senior got nervous after phase one.
Fine.
They update the adapter.
Or deploy a new ModelFactory setup because the old one is already too live to touch without breaking things.
So now both truths are in the system.
Old OpenLoRA adapter still resolves. New adapter starts serving. PoA can trace both. Great.
Now what is the downstream agent supposed to do with that.
Treat them as equivalent.
Sequential.
Superseded.
Based on which boundary, exactly.
And yes, half the time they keep the same label. Of course they do. Renaming the agent would force them to admit the workflow changed more than they wanted.
OpenLedger, doing its job, makes both versions look clean enough to trust.
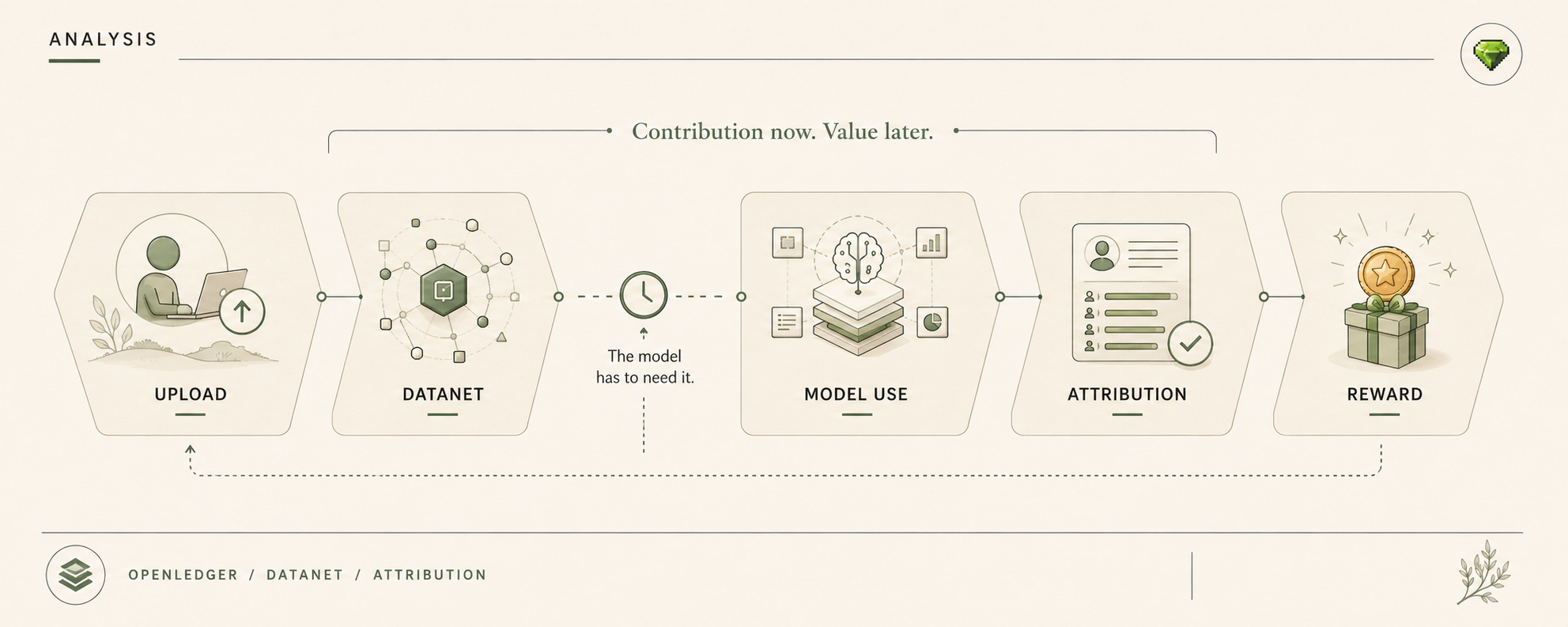
I keep picturing a pretty normal AI mess. Trading agent, OctoClaw automation, research agent, vault monitor, pick your flavor. Phase one launches fast because it always launches fast. Datanet v1 carries a narrow enough signal then. ModelFactory packages it. OpenLoRA adapter v1 serves it. PoA tracks the lineage. Good enough to get the workflow moving.
Then somebody notices the first version was too forgiving, too broad, too dependent on one team’s interpretation. So phase two tightens. New Datanet scope. New adapter. New cloud config. Maybe a bridge action or ERC-4626 route now needs another check before the agent can act. Same conceptual label sometimes, which is where things start getting stupid.
The old output meant generated under the initial model path.
The new output means generated under the revised path plus additional controls.
On paper that should be enough.
In a live workflow, not really.
Both can still look like the same kind of agent output if you are in a hurry and reading for operational effect instead of model history.
Which, to be fair, is exactly how most downstream systems read.
A trading agent wants execute or do not execute.
A marketplace flow wants usable or not.
A payout path wants attributable or not.
Reporting does not want narrative.
It wants rows.
That is the trap.
Once multiple model generations are live on OpenLedger, the pressure moves from model deployment to interpretation hygiene. Sounds boring. Still wrong. Not boring once value or execution is attached.
What exactly is a downstream tool supposed to do with two outputs that are both traceable, both attributable, both tied to legitimate Datanets, but not actually grounded in the same model rulebook anymore.
Treat them as equivalent.
Sequential.
Ignore the old one.
Keep both.
Great.
Based on what.
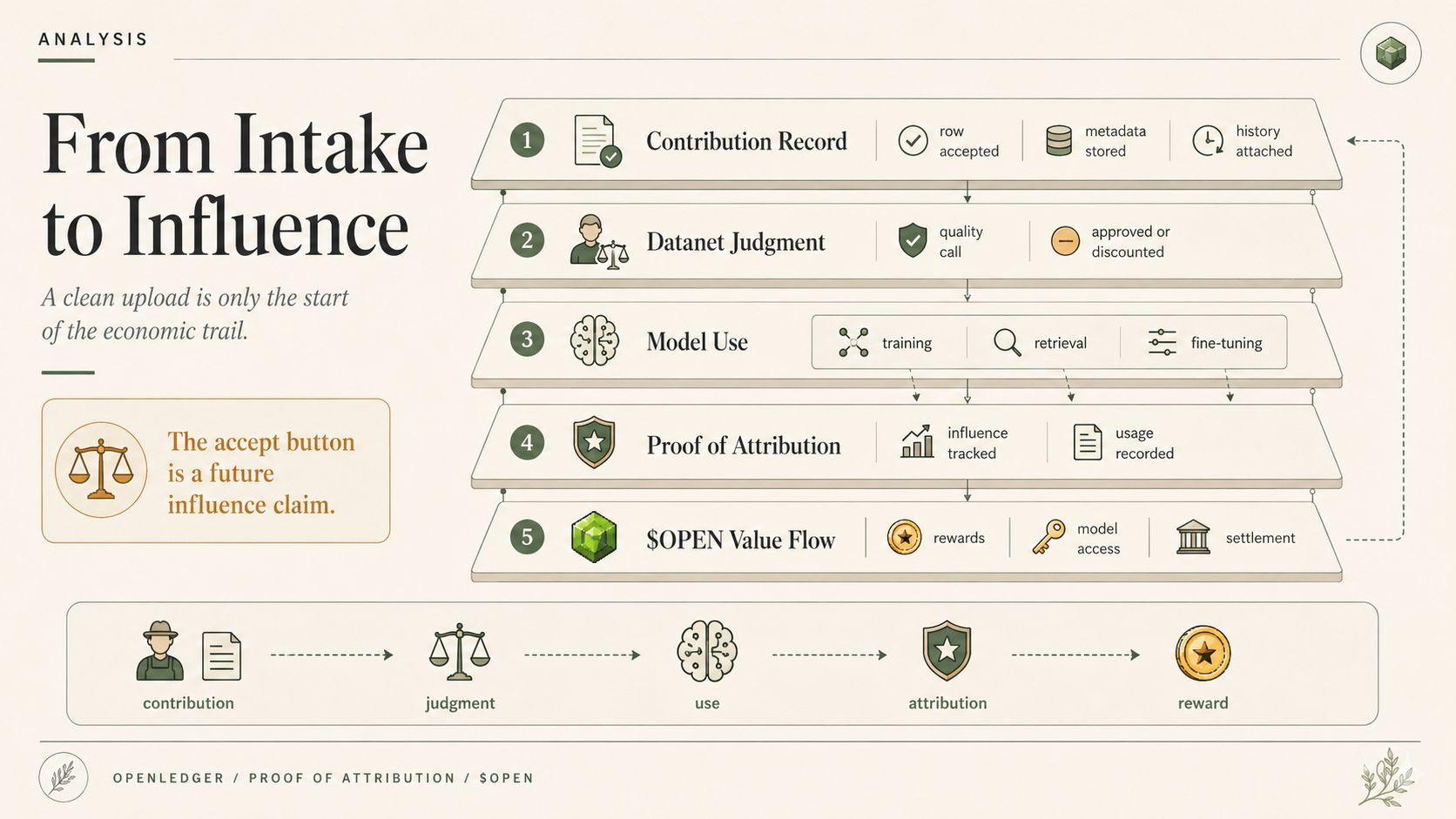
OpenLedger gives the workflow a clean model lineage surface. Useful. Also exactly why this gets messy later. Lineage survives policy edits much better than teams survive their own policy edits. The model path keeps its shape. The workflow that gave it meaning does not.
Model version IDs are supposed to solve this.
They do not.
Not in practice.
Yes, technically, different adapter means different meaning. Fine. Great.
That only helps if the downstream agent actually behaves like adapter versioning matters. A lot of them do not. Or not enough. Most failures here are not because the identifier was hidden. They happen because somebody decided the identifier mattered less than keeping the flow simple.
Simple is where this starts going bad.
Maybe "drift" sounds too soft.
No, it is drift.
Just dressed up as versioning.
And once that starts, you get weird half-failures. Not exploits. Not obvious hallucination. More humiliating than that.
Agent runs generated off an old adapter nobody would still defend if asked live. Internal dashboards showing one coherent output population when it is really two or three model eras stacked on top of each other. PoA trails that are technically excellent and still not enough to answer the annoying question, which is not did this output trace, but under which version of the model workflow was this action produced, and is the downstream system pretending those versions are equivalent because it was easier.
That last part is usually the answer, by the way.
Easier.
OpenLedger infrastructure is not confused. The people around it are. Or they decide the distinction is somebody else’s problem until review starts yelling. The records are there. Datanet references are there. ModelFactory deployments are there. OpenLoRA adapter versions are there. PoA is showing you what actually happened. The confusion enters when teams want continuity more than they want clean separation.
So they keep the agent label similar.
Or they let internal tooling treat old and new adapters as basically the same model.
Or they promise themselves they will phase out the old deployment soon and then trading logic keeps reading both because nobody wanted to break production over what looked like a documentation problem.
Documentation problem.
Right.
Then treasury or risk gets dragged in later and suddenly it is not documentation anymore. It is an output population produced under mixed model logic.
Which is a very polite way of saying the stack kept carrying old judgment forward because nobody wanted to slow anything down.
And it gets uglier in very normal ways. Someone exports an agent-run set for reporting using output presence plus one loose agent tag because that was good enough in phase one. The migration note said old-adapter outputs were valid only for runs before a cutoff date, but the cutoff never made it into the execution filter. So the batch goes out with a mixed population. Old outputs, new outputs, same label, same dashboard bucket, same report upstairs.
Later someone notices an action cleared under a model path the team already tightened six weeks ago.
The output still traces.
The adapter reference is real.
The problem is the relying layer flattened time because adding era-sensitivity would have made rollout slower.
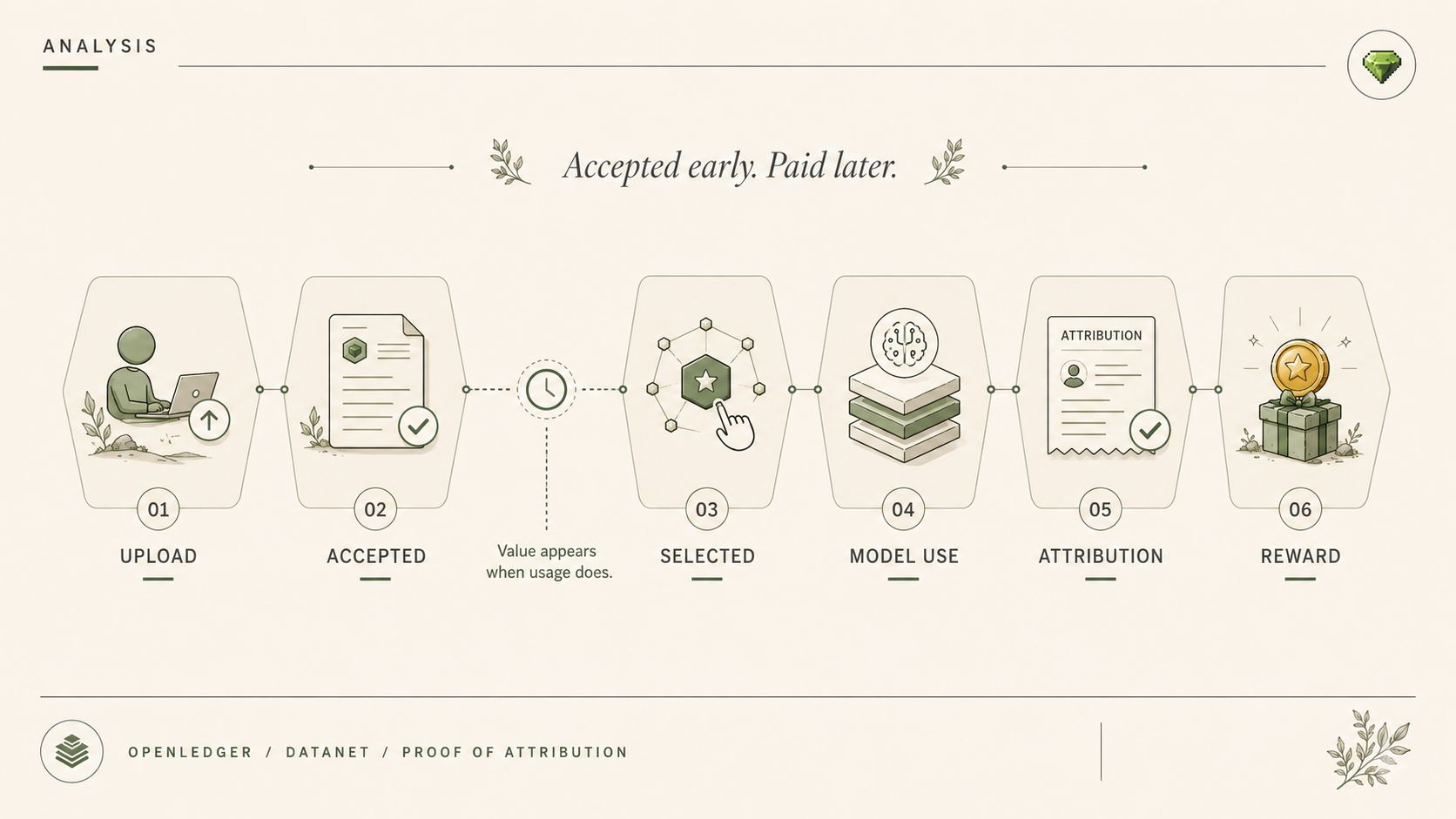
And OpenLedger, because it is doing its actual job, keeps making those model judgments portable enough for the next system to act on them. The better it works as AI infrastructure, the less friction there is to accidentally carry old model policy forward.
More than people want to admit.
I keep thinking about migration windows too. Those are bad. Really bad. Team says old adapter remains valid for previously generated runs, new adapter applies only going forward. Sounds reasonable. Often is reasonable.
Until some relying system forgets that “previously generated” is a temporal condition tied to model context and not some permanent property of the agent output.
Then an output generated under the old model path keeps doing future work in places where the team thought the new path had already taken over.
Same output.
Different era.
Still live.
Still live for what, exactly.
Execution.
Reporting.
$OPEN payout.
A trading route.
Somebody needed to decide that earlier.
And because everything traces, people waste time arguing about authenticity when the actual wound is continuity. The old output is authentic. That was never the interesting part. The interesting part is whether downstream systems have any discipline about historical meaning once the workflow has moved on.
Some do.
Plenty do not.
They just keep reading.
Model drift gets worse because it can look like maturity. Look, the agent evolved. Look, OpenLedger's LoRA adapter got refined. Look, the protocol captured both states. True. All true. Still not enough if the relying layer acts like versioned model lineage is interchangeable model lineage.
A trade gets included because an old output still passed the filters. A vault leg stays open because the workflow checked for agent label, not generation. A report goes upstairs showing one clean output population without admitting half of it came from a looser adapter the team already stopped standing behind months ago.
Then someone says the records were valid.
Fine.
Great.
That was the easy part.
The hard part was whether validity from one model era was ever supposed to authorize action in another.
And if the answer is “well, it depends,” then that dependence needed to be somewhere the workflow could actually enforce before the next agent started reading from OpenLedger like model history and current policy were the same thing.
Fine.
The old adapter was valid.
The workflow had already moved on.
Useful distinction to discover after the next agent already treated both as the same brain.