Been going through openledger’s architecture notes and validator discussions this week, mostly trying to understand whether the protocol is solving a real coordination problem or just wrapping token incentives around ai infrastructure before demand fully exists.
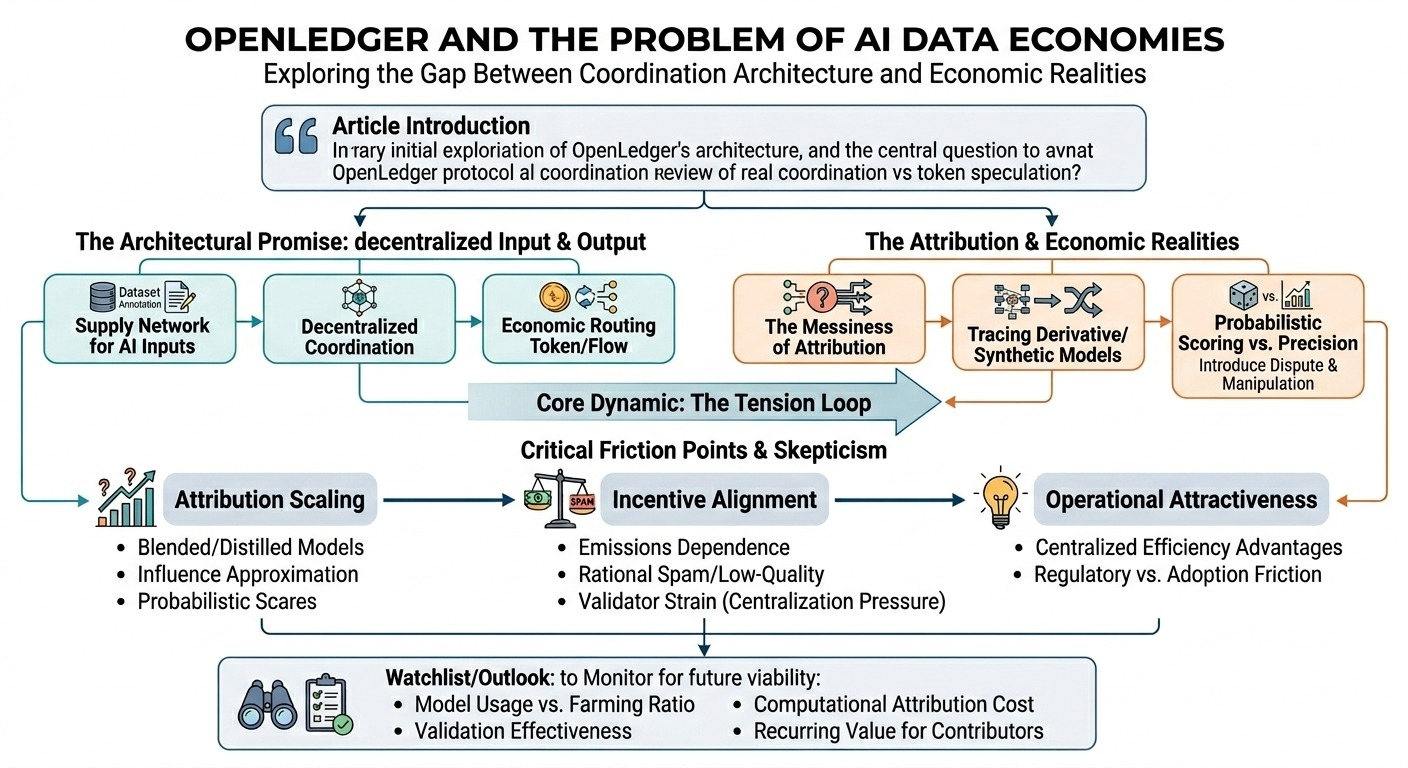
most people seem to describe openledger as another “ai + blockchain” project, but honestly that framing hides the more interesting part. the architecture is less about decentralized model training itself and more about data attribution, contributor coordination, and economic routing between datasets, models, and users.
what caught my attention first was the decentralized contribution layer. contributors can supposedly provide datasets, annotations, feedback loops, or domain-specific information that later feeds into model training or inference systems. the idea seems to be creating an open supply network for ai inputs instead of relying on a few closed data pipelines controlled by centralized platforms.
in theory, that sounds reasonable. ai systems increasingly depend on specialized data rather than just larger generic corpora. a healthcare model, for example, may need verified radiology annotations from practitioners rather than scraped internet text. openledger appears to be trying to build the rails where those contributors can participate directly and receive ongoing rewards tied to downstream usage.
but then the architecture runs into the hardest part immediately: attribution.
and this is the part i keep thinking about because attribution in machine learning systems gets messy very fast. once datasets are blended, transformed, fine-tuned, or partially distilled into later models, tracing influence becomes statistical rather than exact.
openledger’s design seems to rely on a verification and reward layer that tracks contribution impact across the network. contributors whose data materially improves outputs receive compensation through on-chain coordination mechanisms. conceptually it makes sense. economically, it’s probably necessary if decentralized data markets are going to work at all.
still, i’m not fully convinced attribution scales cleanly.
imagine thousands of contributors supplying legal datasets into a retrieval-augmented model used by firms analyzing compliance risks. maybe a small subset of contributors meaningfully improves niche regulatory accuracy. how does the protocol isolate that value over time? especially after retraining cycles, derivative models, or synthetic augmentation enters the pipeline?
the system likely depends on probabilistic scoring and validator consensus rather than perfect lineage tracking. maybe that’s enough. maybe economic fairness only needs approximation instead of precision. but it definitely introduces room for dispute, manipulation, or reward gaming.
the marketplace layer is also interesting because openledger seems to assume future ai ecosystems will prefer transparent and modular data sourcing. i can see why. regulation around training data provenance probably increases over time, and enterprises may eventually need auditable inputs instead of opaque scraping practices.
but there’s a major assumption embedded in that thesis: that open attribution systems become operationally attractive enough for developers to adopt despite the friction. centralized providers still have huge advantages in speed, compute integration, and distribution. decentralized coordination systems usually win more gradually through composability and incentive alignment, not convenience.
honestly the token layer is where my skepticism increases most.
the network needs incentives early. without rewards, contributors probably don’t upload valuable datasets before meaningful marketplace demand exists. but if emissions become the primary source of economic activity, participation risks turning extractive instead of useful.
spam data feels like an unavoidable pressure point. duplicated datasets, synthetic low-quality outputs, automated labeling pipelines — all of those become rational if rewards outpace validation costs. so validators become critically important, which adds another layer of coordination complexity and potentially centralization pressure around quality control.
and i still don’t fully know who captures the majority of long-term value if the system works. contributors? validators? model operators? token holders? openledger talks a lot about alignment, but alignment mechanisms tend to get stress-tested once real economic competition enters the network.
none of this means the architecture lacks substance. actually, compared to a lot of ai-related crypto infrastructure, openledger is at least targeting a legitimate coordination issue around provenance and incentive routing. that’s more interesting to me than projects treating decentralization itself as the product.
still feels early though. the entire design depends on future demand for attributable ai data economies becoming real before speculative incentives fade out.
watching:
- ratio of real model usage versus incentive farming
- effectiveness of dataset validation under scale
- whether attribution costs remain computationally reasonable
- how much recurring value flows back to contributors over time
not sure there’s a clean conclusion yet. feels like one of those systems where the economics matter more than the technology eventually.