Been going through openledger’s docs, validator notes, and a few architecture threads lately, mostly trying to figure out what layer they’re actually building. most people seem to treat it like another ai + crypto token story, but honestly that feels too shallow. the more i look at it, the more it seems like openledger is attempting to build a coordination system around ai data itself — who contributes it, who verifies it, and who gets paid when models use it later.
that’s a much harder problem than just running inference on-chain or spinning up decentralized compute.
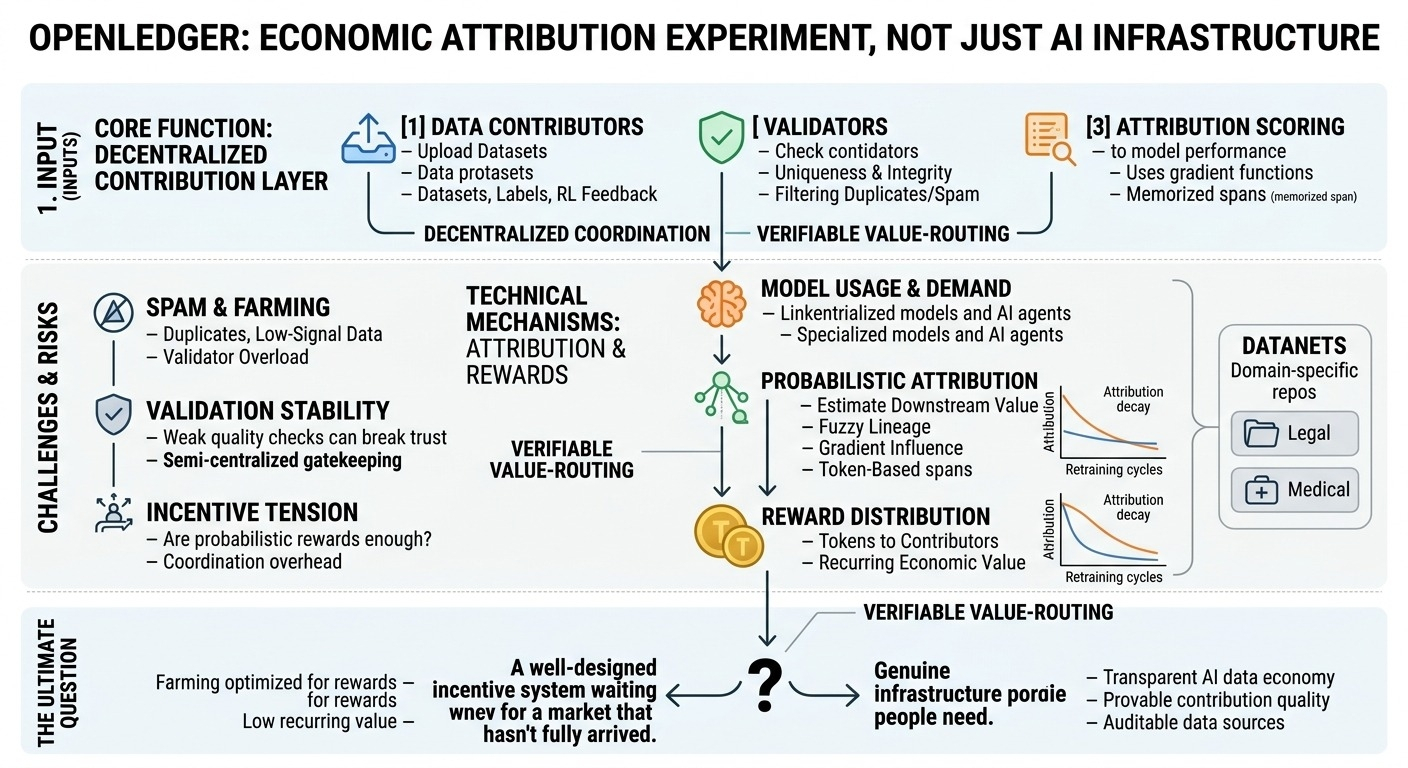
what caught my attention first was the decentralized contribution layer. contributors can submit datasets, labels, structured domain knowledge, maybe even reinforcement feedback tied to model outputs. the protocol then tries to connect those contributions to downstream model performance and economic rewards.
in theory, this creates a more open ai supply chain. instead of a closed platform absorbing user interactions and retraining privately, you get a network where contributors are visible participants in the value loop.
but then the obvious question appears immediately: how do you prove contribution quality in a way people actually trust?
and this is the part i keep thinking about because attribution in ai systems is not clean. once datasets are merged into training pipelines, fine-tuned repeatedly, or mixed with synthetic augmentation, lineage becomes fuzzy. maybe not impossible to estimate, but definitely harder than blockchain-style accounting where every transfer is explicit.
openledger seems to approach this through validators and attribution scoring systems tied to model usage. if a dataset meaningfully improves outputs, contributors receive rewards. conceptually that makes sense. practically, i’m unsure how stable that remains at scale.
say contributors upload legal case summaries that improve a specialized compliance model used by firms. maybe those summaries materially improve accuracy on obscure jurisdictional edge cases. okay. but over time, after multiple retraining cycles and derivative models, how does the network continue attributing value fairly? especially if the improvement is indirect or distributed across thousands of contributors?
the architecture probably relies on probabilistic attribution rather than perfect traceability. honestly that may be unavoidable. but probabilistic reward systems create incentive tension because contributors need to believe the scoring process is legitimate enough to keep participating.
the marketplace layer also says a lot about the assumptions behind the protocol. openledger seems to assume there will eventually be meaningful demand for transparent, attributable ai data economies. maybe they’re right. companies facing regulatory pressure around copyrighted or unverifiable training data may prefer auditable data sources eventually.
still, that future is not guaranteed.
centralized systems remain operationally simpler in a lot of ways. integrated compute, distribution, internal feedback loops — all easier to optimize when one entity controls the stack. decentralized systems usually compete through openness and incentive alignment, but those advantages only matter if enough participants actually care about provenance and shared ownership.
the token design is where i become more cautious.
the network clearly needs incentives early. otherwise contributors won’t provide high-value datasets before marketplace demand exists. but token emissions can also distort behavior fast. if rewards outweigh verification quality, the system starts attracting low-signal contributions optimized for farming instead of usefulness.
spam feels like a real structural risk here. duplicated datasets, synthetic garbage, lightly modified public data — all economically rational if validation is weak. then validators become more important, which increases coordination overhead and maybe even pushes the network toward semi-centralized gatekeeping.
and honestly i’m still unclear who captures most of the value if openledger succeeds. contributors? validators? model operators? infrastructure providers? open coordination systems tend to sound egalitarian early, but economic concentration usually appears somewhere in the stack.
still, compared to a lot of ai-related crypto infrastructure, this feels directionally more grounded. at least the protocol is targeting a legitimate coordination issue around attribution and incentive routing instead of assuming decentralization alone creates value.
watching:
- whether real model demand grows independently of token incentives
- attribution accuracy as datasets and models become more compositional
- validator effectiveness against spam or low-quality submissions
- how much recurring economic value actually reaches contributors
i guess the open question is whether openledger becomes infrastructure people genuinely need, or whether it remains a well-designed incentive system waiting for a market structure that hasn’t fully arrived yet.