
Acum câteva nopți am deschis o poziție foarte mică $OPEN aproape din întâmplare. Nimic mare — în jur de 85 de dolari — în mare parte pentru că am tot văzut oameni aruncând termenul „blockchain nativ AI” și, sincer... voiam să descopăr dacă chiar înseamnă ceva sau era doar o altă etichetă fancy.
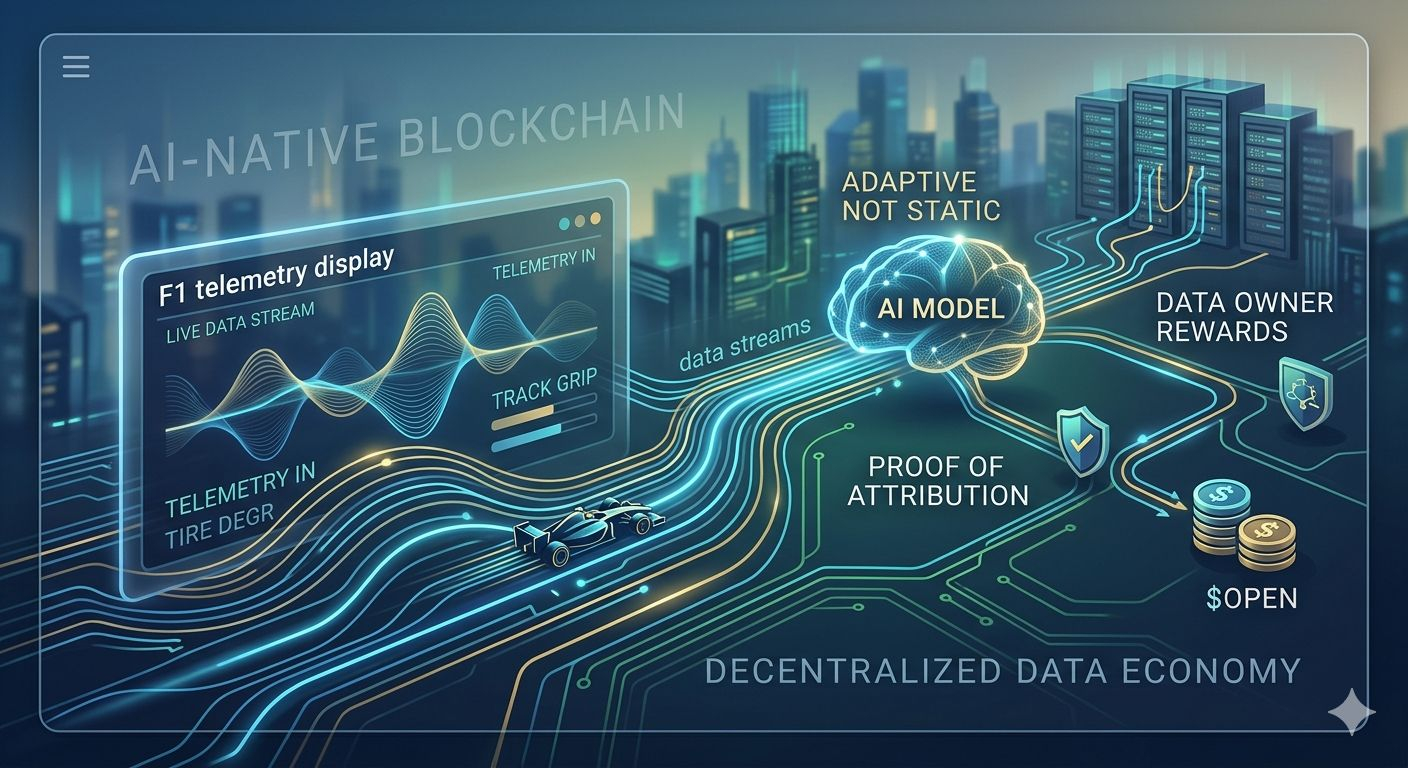
Ceea ce mi-a atras atenția despre @OpenLedger nu a fost narațiunea AI în sine. Am văzut deja prea multe proiecte care atașează „AI” la tot. Partea interesantă a fost modul în care descriu AI-ul ca ceva care reacționează continuu la datele live, în loc să acționeze ca un model fix așteptând comenzi.

M-am tot gândit la comparația lor cu Formula 1. La început părea un pic exagerată, dar cu cât m-am uitat mai mult, cu atât mai mult logica a început să aibă sens. Într-o cursă F1, echipele nu doar că merg repede — se ajustează constant în funcție de telemetrie, vreme, degradarea anvelopelor, aderența pe pistă, cronometrarea combustibilului. Deciziile se schimbă la fiecare secundă pentru că mediu se schimbă la fiecare secundă.
Asta e, practic, cum pare să vadă OpenLedger infrastructura AI.
Nu statică.
Adaptiv.
Și, sincer, cred că majoritatea oamenilor nu înțeleg de ce asta contează.
Schimbarea reală aici s-ar putea să nu fie „răspunsuri mai bune ale AI-ului.” S-ar putea să fie ideea că sistemele AI devin în cele din urmă sisteme economice live conectate direct la fluxuri de date. Conceptul lor de Datanets pare mai puțin ca un stocaj și mai mult ca un strat senzorial continuu care hrănește modelele în timp real.
Dar aici am devenit un pic conflictat.
Pentru că mai multe date în timp real nu înseamnă automat o inteligență mai bună. Uneori, doar creează mai mult zgomot. Piețele ne arată deja asta. Traderii care reacționează la fiecare mișcare mică ajung de obicei distruși în cele din urmă. Deci, dacă modelele AI se adaptează constant, unde e echilibrul între adaptare și reacție exagerată?
Această întrebare încă îmi rămâne în minte.
Cealaltă chestie care mi s-a părut cu adevărat interesantă a fost ideea lor de „Dovada Atribuirii”. Cele mai multe discuții despre AI se concentrează doar pe rezultate. OpenLedger pare mai concentrat pe urmărirea de unde vine cu adevărat inteligența — care date au contribuit, cine a adus valoare și cum ar trebui să curgă recompensele înapoi prin sistem folosind $OPEN.
Asta e o conversație mult mai profundă decât își dă seama lumea.
Pentru că dacă AI-ul ajunge să funcționeze pe economii de date descentralizate masive, atunci proprietatea datelor devine la fel de importantă ca și proprietatea infrastructurii în sine.
Și, sincer... nu cred că piața a prețuit complet această narațiune încă.
Nu din cauza hype-ului. În mare parte pentru că oamenii încă privesc AI-ul ca pe un software în loc de un mediu în evoluție.
Totuși, sunt încă precaut. Chiar am tăiat o parte din poziția mea de test ieri după o mișcare mică pentru că am văzut prea multe povești despre „infrastructura viitorului” eșuând odată ce realitatea lovește în scalare, stimulente și comportamentul utilizatorilor. Transparența sună grozav până când sistemele devin atât de complexe încât nimeni nu mai poate înțelege cu adevărat ce vede.
Totuși, nu pot să discreditez complet ceea ce încearcă să construiască OpenLedger.
Nu pare încă o soluție finalizată.
Dar nu se simte ca niște cuvinte cheie ale AI-ului aruncate la întâmplare pentru atenție.
Pentru mine, pare mai mult un semnal timpuriu că blockchain-ul și AI-ul se contopesc încet într-un ceva mai dinamic — unde datele, atribuirea, stimulentele și inteligența interacționează în timp real în loc să existe separat.
Poate că asta devine infrastructură reală mai târziu.
Sau poate că acesta este pur și simplu prima versiune brută a unei evoluții mult mai mari pe care nu am înțeles-o complet încă.