Most people do not think about artificial intelligence while posting online. Someone writes a product review, uploads artwork, answers questions in a forum, or shares an opinion on social media without imagining that years later, fragments of those words and ideas could become part of an AI system. Yet that is exactly what has happened across the internet. Modern AI models have been built using enormous amounts of publicly available information, much of it created by ordinary people who never expected their contributions to become part of a commercial technology race.
For a long time, this process remained mostly invisible. AI companies collected data, trained models, improved products, and expanded their influence while very little attention was given to where the training material originally came from. The internet slowly became a resource mine for machine learning systems. What people once viewed as casual online activity eventually turned into valuable infrastructure for the AI economy.
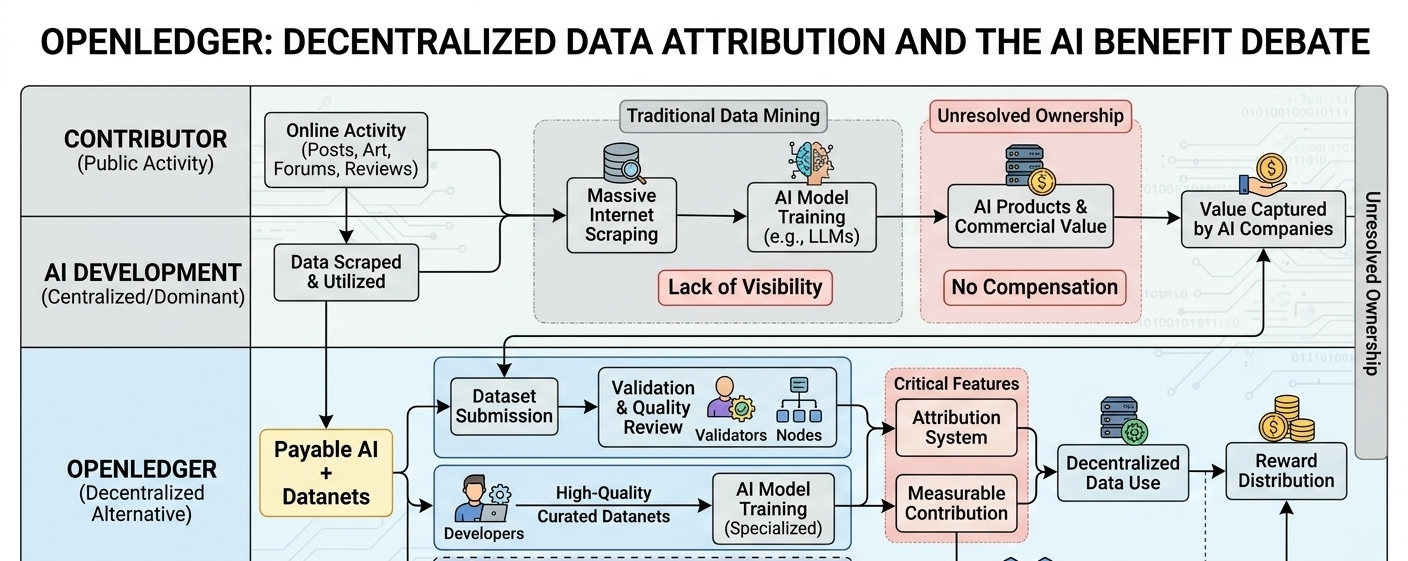
The issue is not simply about privacy. It is also about ownership, recognition, and value. AI systems today can generate articles, summarize information, create images, answer questions, and automate tasks because they learned patterns from human-created material. But the individuals behind that material rarely receive any visibility into how their work is being used. In most cases, they are not compensated either. Their contribution disappears into systems that are difficult to track or understand.
Part of the reason this problem remained unresolved is because attribution inside AI models is technically complicated. Machine learning systems do not store information in a straightforward way like a searchable archive. Instead, they absorb patterns from massive datasets during training. Once that process is complete, identifying how much influence a specific article, image, or conversation had on the final model becomes extremely difficult.
Some earlier projects tried to solve this issue through decentralized data marketplaces or blockchain-based AI networks. Many of them argued that blockchain technology could bring more transparency to AI development. But in reality, a large number of those projects struggled to move beyond theory. Some focused heavily on token incentives while offering limited practical solutions for verifying data quality or tracking actual contribution inside AI systems.
is one of the newer projects attempting to approach this problem from a different angle. Rather than positioning itself as a general crypto platform, it focuses specifically on AI infrastructure and data attribution. The project’s broader argument is relatively simple: if human-generated data powers artificial intelligence, then contributors should have a more visible and measurable role in the system.
The idea sounds reasonable, especially at a time when concerns around AI ownership are becoming more common. Writers are questioning whether their work is being used to train language models. Artists continue debating whether image generation systems rely too heavily on existing creative work. Researchers and online communities are also becoming more aware that publicly shared knowledge now holds significant economic value inside the AI industry.
OpenLedger attempts to address this through what it describes as “Payable AI.” In simple terms, the concept revolves around creating systems where datasets and contributions can be tracked more transparently, potentially allowing contributors to receive rewards connected to the value their data creates. Instead of treating AI models as completely closed systems, the project tries to introduce more visibility into how training data is sourced and used.
One of the platform’s key ideas is something called “Datanets.” These are decentralized data networks organized around specific types of information. Contributors can submit datasets, validators review their quality, and developers can later use those datasets to train AI models. The structure is designed to encourage more specialized and organized data collection rather than relying entirely on broad internet scraping.
That approach reflects a growing shift happening inside the AI industry itself. Larger datasets are not always better datasets. Many developers are now focusing on high-quality, domain-specific information because general internet content often includes misinformation, duplicated material, and inconsistent quality. Smaller, curated datasets can sometimes produce stronger results for specialized tasks.
At the center of OpenLedger’s vision is the idea of attribution. The platform proposes systems intended to measure how certain datasets contribute to AI outputs so rewards can potentially flow back toward contributors. Conceptually, this addresses one of the biggest ethical questions surrounding modern AI development. If people’s knowledge and creativity help train profitable systems, should they remain completely disconnected from the value being created?
Still, the technical reality remains uncertain. Attribution inside AI systems is one of the hardest challenges in machine learning. AI models process information in highly interconnected ways, making it difficult to isolate the exact influence of individual datasets. Even with blockchain infrastructure recording contributions, calculating fair compensation may remain subjective and difficult to verify at scale.
There are also concerns around incentives and quality control. Open contribution systems often face problems with spam, duplicated content, or low-value submissions because participants are rewarded for activity. Decentralized platforms have historically struggled with maintaining consistent quality standards. OpenLedger includes validators and review mechanisms, but whether those systems can scale effectively over time remains an open question.
Another issue is accessibility. Blockchain ecosystems can still feel highly technical to ordinary users. Participating often requires understanding wallets, nodes, validation systems, and crypto infrastructure that many people are unfamiliar with. Although OpenLedger presents itself as part of a more open AI future, the practical reality may still favor technically experienced users rather than average internet contributors.
The project also exists in a competitive environment dominated by large centralized AI companies with enormous resources. Those firms already control vast datasets, advanced infrastructure, and powerful distribution networks. Even if decentralized alternatives offer greater transparency, centralized platforms may continue dominating simply because they are faster, cheaper, and easier for businesses to adopt.
At the same time, projects like OpenLedger highlight something important about the current direction of technology. People are becoming increasingly uncomfortable with the idea that human knowledge can be absorbed into AI systems without clear accountability. The internet was originally built around openness and sharing, but AI has changed the economics of information. Data is no longer just communication. It has become a valuable industrial resource.
Whether OpenLedger succeeds or not may ultimately matter less than the questions it raises. The project reflects growing pressure for more transparency around how AI systems are built and who benefits from them. Even critics who doubt the practicality of decentralized AI infrastructure often acknowledge that concerns around attribution and ownership are becoming harder to ignore.
The difficult part is that no solution appears perfect. Centralized AI systems create concerns around control and accountability, while decentralized systems introduce challenges involving coordination, complexity, and quality management. OpenLedger sits somewhere inside that tension. It does not fully solve the problem, but it attempts to approach it from a direction many traditional AI companies have largely avoided.
As artificial intelligence becomes more integrated into everyday life, debates around ownership and contribution will probably become even more important. The internet trained modern AI systems, but the relationship between the people creating knowledge and the companies monetizing it still feels deeply unclear. If future AI models continue learning from billions of human interactions, can any system truly distribute value fairly, or will most contributors always remain invisible behind the technology they helped build?
