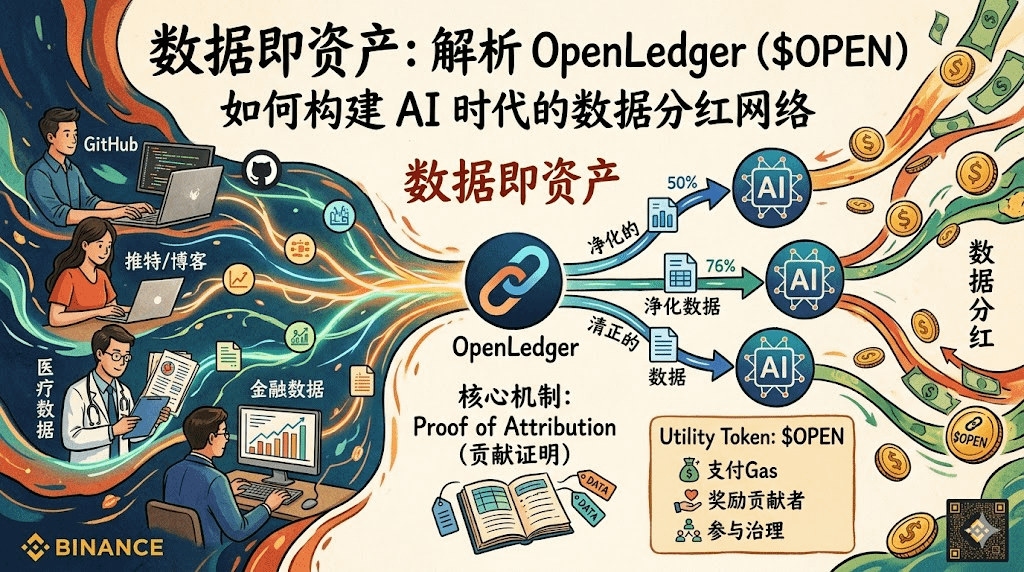
现在聊AI,大家的目光全被那几个巨头吸引住了,今天这家参数破多少亿,明天那家上下文冲到多少万。但你有没有想过一个问题:这些模型吃进去的数据,到底是谁的?我刷推特、写博客、在GitHub上扔代码,这些内容被拿去训练模型,然后公司靠这个赚钱,跟我有什么关系?啥也没有。不是说我非要那几块钱,但这种"数据白嫖"的感觉,确实让人不太舒服。
最近看到一个叫@OpenLedger 的项目,切入点挺有意思的。它不跟别人卷模型参数,而是专门解决一个问题:数据贡献了,怎么证明、怎么分钱。核心机制叫 Proof of Attribution,翻译过来就是 贡献证明。说白了就是上链记账,谁提供了什么数据,哪个模型用了这些数据,产生了什么输出,全部记下来。以后这个模型赚钱了,按贡献大小自动分配收益。
听起来有点理想主义对吧?但我仔细想了下,这事儿其实挺刚需的。现在互联网上能爬的公开数据基本快消耗完了。接下来真正有价值的数据在哪?在医院、律所、金融机构的内部数据库里。这些数据质量高、专业性强,但人家凭啥白给你?你需要一个机制,让他们愿意拿出来,OpenLedger想做的就是这件事:你贡献数据,你持续分红。
技术上它用OP Stack搭的链,兼容EVM,MetaMask直接连。旗下有个叫OctoClaw的代理平台,整合了数据获取、决策、链上执行这些环节。还有个VibeCoding,说是能降低AI代理开发门槛,这些我还没深度体验,但方向是对的。代币叫$OPEN ,总量10亿,初始流通大概21.55%。功能就是典型的utility token:付Gas费、奖励数据贡献者、参与治理。听说还有个1%的交易销毁机制,这就不多说了,大家自己判断。
说句实在话,这个项目能不能跑出来,关键不在技术(技术思路挺清晰的)。难点在于:谁能说服那些拥有高价值数据的人或机构,把自己的“家底”放到链上来?这涉及到商业模式、信任、激励机制的综合设计。不过有一点我很认同:AI时代,数据产权和收益分配这个问题,迟早要解决。OpenLedger至少是在往这个方向走,而不是简单地发个币、炒个概念。有时间可以去他们的官网看看,或者体验下OctoClaw。我觉得,与其在推特上看别人吹参数,不如关注一下这些真正触及利益分配底层的尝试。(本文是平台任务,不构成任何投资建议。)