Am avut cândva un folder de bookmark-uri numit “Tool-uri AI de încercat din nou”.
Sună foarte organizat. De fapt, seamănă mai mult cu un cimitir. Am păstrat multe tool-uri, agenți, chatboti, plugin-uri pentru că la lansare păreau toate promițătoare. Demo-uri frumoase. Thread-uri de analiză lungi. Unele chiar m-au făcut să cred: “Da, chestia asta sigur o să o folosesc frecvent.”
Apoi n-am mai deschis din nou.
Nu e vorba că sunt stricate sau nu funcționează bine. E mult mai simplu: nu sunt suficient de necesare pentru a intra în rutina mea.
Când citesc despre OpenLedger, acel sentiment revine într-un mod mai serios.
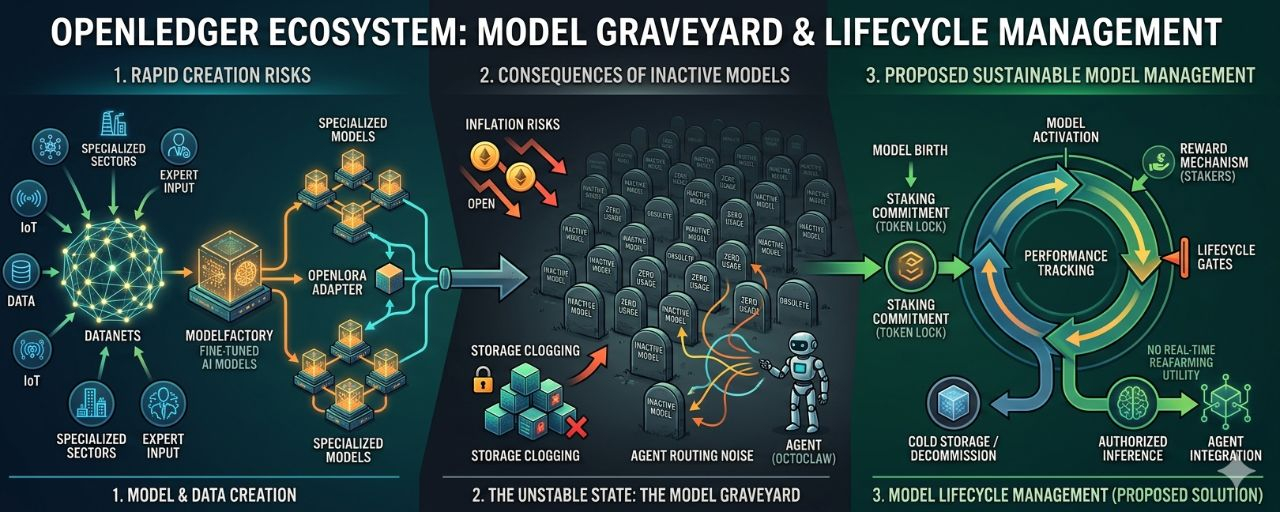
OpenLedger construiește un ecosistem pentru modele AI specializate: are Datanets pentru a aduna date specifice, ModelFactory pentru a le finetuna, OpenLoRA pentru a sprijini mai multe modele mai eficient, Proof of Attribution pentru a recunoaște contribuțiile, și inference payment pentru a genera venituri din modele. Acesta este un pipeline foarte rațional.
Dar tocmai pentru că acel pipeline este rațional, riscurile din spate sunt și mai înfricoșătoare.
Dacă crearea de modele devine mai ușoară, dacă datele sunt adunate mai repede, dacă fiecare comunitate poate iniția un model specializat, atunci întrebarea nu mai este „există suficiente modele?”
Întrebarea este: câte modele dintre acestea merită cu adevărat să existe?
Eu numesc această problemă Cimitirul Model.
Un cimitir de modele nu este doar un loc plin de modele nefolosite. Dacă ar fi așa, atunci ar fi destul de inofensiv. Cel mai rău este că dashboard-ul este puțin urât, câteva proiecte sunt uitate, câțiva oameni își pierd timpul.
Dar într-un AI blockchain precum OpenLedger, modelele moarte nu stau liniștite.
Asta lasă în urmă costuri.
Costul inițial este inflația stimulentelor. Dacă sistemul continuă să ofere recompense pentru prea multe modele care nu au demonstrat o cerere reală, token-ul va fi tras în întreținerea unui supply fals. Contribuitorii văd recompensele, așa că continuă să genereze mai multe date, mai multe modele, mai multe activități. Dar acea activitate nu generează neapărat inference real. Când recompensele depășesc cererea prea mult, token-ul nu mai este un semnal de valoare. Devine combustibil pentru a menține iluzia că ecosistemul este în expansiune.
Costul al doilea este congestia Storage-ului Fierbinte. Un model nefolosit poate ocupa în continuare metadata, istoricul versiunilor, adaptorul, urma de atribuire, starea de hosting și straturile de date care servesc inference-ul. Nu totul ar trebui să fie păstrat în stare fierbinte doar pentru că a fost lansat. Dacă toate modelele sunt tratate ca active vii, sistemul va trebui în curând să plătească costurile pentru activele deja moarte.
Costul al treilea este ceea ce consider eu cel mai periculos: zgomotul în Routing-ul Agenților.
Viitorul OpenLedger nu este doar că utilizatorii aleg modelele manual. Proiectul a introdus OctoClaw ca un strat de agent care poate construi, automatiza și executa fluxuri de lucru în timp real. Aceasta face întrebarea despre modelele moarte și mai serioasă. Un agent nu poate funcționa bazându-se pe intuiție. Trebuie să cheme modelul, să aleagă adaptorul, să acceseze datele, să cheme un instrument și să decidă care sursă este de încredere în fiecare context.
Când ecosistemul este inundat de un cimitir de modele, agenți precum OctoClaw pot fi atrași de semnale false: un adaptor care a fost odată folosit pentru a genera date frumoase, un model care a avut multă atribuție dar utilitatea a murit, o sursă de date veche care încă se află pe calea fierbinte pentru că nimeni nu a îndrăznit să o downgradeze.
Atunci, problema nu mai este „acest model nu este folosit de nimeni”.
Problema este că un model mort poate încă să se interpună în procesul decizional al unui agent care funcționează cu adevărat.
Așadar, dacă doar spui „creați model atunci când există suficientă cerere”, este încă un pic prea timid. OpenLedger are nevoie de un mecanism mai puternic pentru a gestiona ciclul de viață economic al modelelor.
Un model nu ar trebui să aibă doar o dată de naștere. Trebuie să aibă o durată de viață, obligația de a se menține, semnale de viață și un mecanism de auto-îngropare dacă nu mai produce valoare.
Modul de a începe poate fi prin staking.
Dacă o comunitate crede că un model specializat are cu adevărat cerere, ei nu doar votează sau contribuie cu date. Trebuie să stake $OPEN în această teză. Staking-ul aici nu este doar despre bani. Este un angajament că acest model merită să ocupe storage, să atragă atenția, să valideze eforturile și să primească bugetul de recompense al ecosistemului.
Apoi, modelul trebuie să demonstreze că este încă viu prin datele de utilizare reale: inference plătit, utilizare repetată, retenție după stimulente, finalizarea sarcinilor, validarea domeniului și capacitatea de a fi selectat din nou de sisteme precum OctoClaw pentru eficiența reală, nu din cauza zgomotului.
Dacă modelul reușește, staker-ul și contributorul sunt recompensați. Dacă nu reușește, o parte din stake este slashing. Modelul pierde prioritatea în routing, este mutat în cold storage sau își pierde dreptul de a primi recompense extinse pentru a elibera resurse pentru agenții și fluxurile de lucru care mai produc valoare reală.
Să spunem lucrurilor pe nume: ecosistemul OpenLedger are nevoie de un mod prin care modelele moarte să plătească singure pentru înmormântarea lor.
Desigur, acest mecanism nu este perfect. Staking-ul poate face ca ideile mici să fie dezavantajate, deoarece nu au suficiente fonduri pentru a demonstra cererea devreme. Slashing-ul poate face ca comunitatea să fie reticentă la experimentare. Unele modele specializate cu utilizare scăzută dar valoare mare pot fi evaluate greșit dacă metricile sunt prea brute.
Dar lipsa managementului ciclului de viață este și mai periculoasă.
Pentru că, în acel moment, OpenLedger ar putea crea ceva cu care multe ecosisteme Web3 s-au confruntat: un oraș luminos la suprafață, dar plin de clădiri abandonate în interior. Multe modele. Multe activități. Multe atribuții. Dar agenții nu știu pe care să le creadă, token-ul este tras în întreținerea a ceva ce nu mai este viu, iar storage-ul devine un depozit de amintiri ale unor experimente pe care nimeni nu îndrăznește să le șteargă.
Un AI blockchain nu poate doar să întrebe cum să creeze mai multe modele.
Trebuie să îndrăznească să întrebe care modele ar trebui să fie susținute, care ar trebui să fie downgrade-ate și care ar trebui să moară.
Dacă @OpenLedger vrea să devină infrastructura pentru AI specializat cu adevărat, aceasta este întrebarea pe care nu o poți ocoli: proiectul construiește o economie de model viabilă sau finanțează un cimitir de modele care consumă token-uri?