
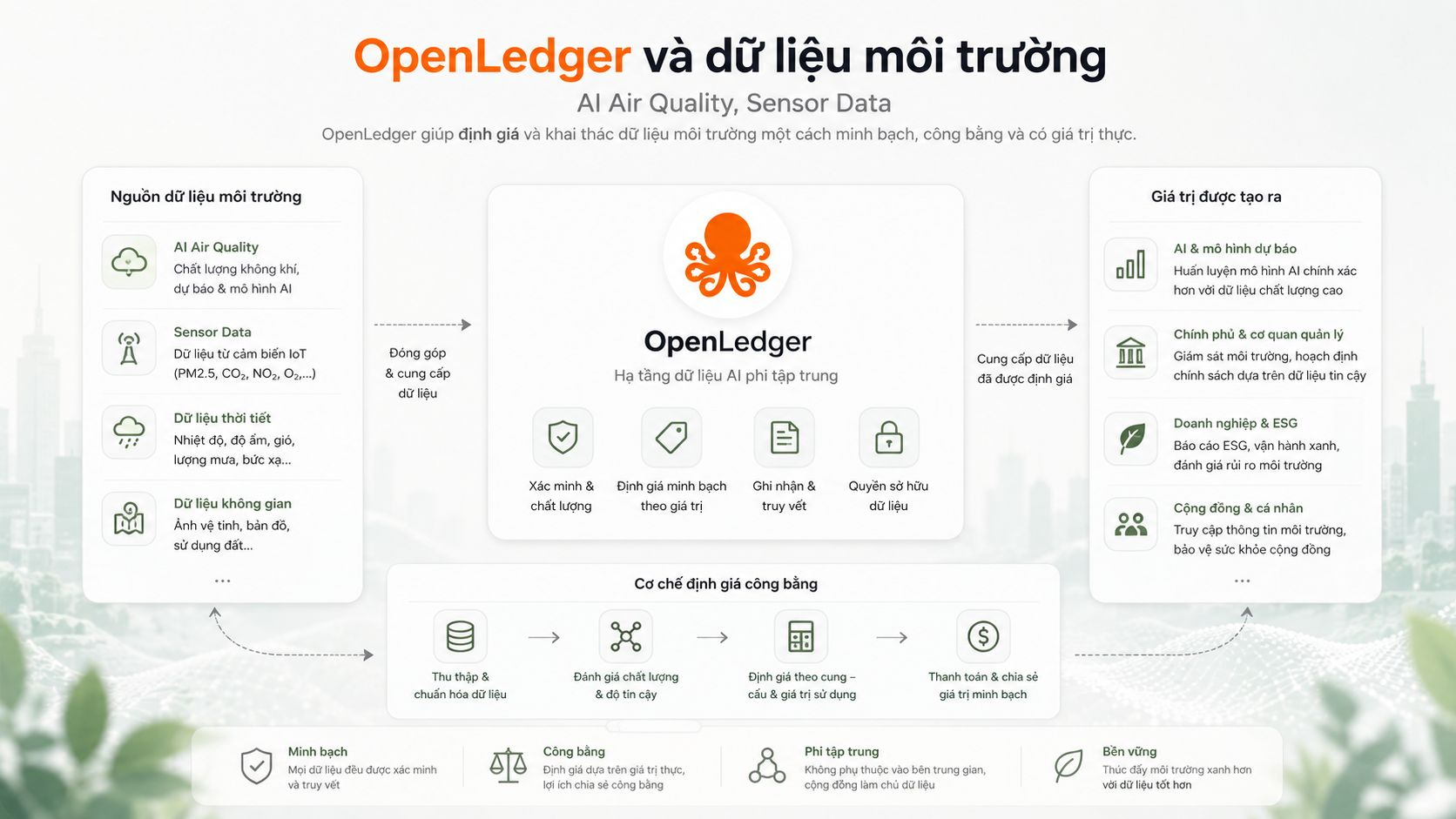
OpenLedger làm mình nghĩ nhiều hơn về một câu hỏi khá thực tế: nếu AI cần dữ liệu tốt để thông minh hơn, vậy những dữ liệu môi trường như chất lượng không khí, cảm biến đô thị hay chỉ số ô nhiễm có đang được định giá đúng chưa?
Với mình, dữ liệu không khí là một ví dụ rất hay. Nó không hào nhoáng như dữ liệu tài chính, cũng không dễ tạo narrative như dữ liệu social, nhưng lại gắn trực tiếp với đời sống thật.
Một cảm biến đo bụi mịn đặt gần công trường sẽ kể một câu chuyện khác hoàn toàn với cảm biến đặt trong khu dân cư. Một sensor gần trường học, bệnh viện, khu công nghiệp hay tuyến đường đông xe đều có giá trị riêng.
Cùng là PM2.5, CO2, nhiệt độ, độ ẩm hay các chỉ số ô nhiễm khác, nhưng phần quan trọng không chỉ nằm ở con số. Nó nằm ở bối cảnh tạo ra con số đó.
Điểm mình thấy đáng nói ở OpenLedger $OPEN là cách dự án tiếp cận dữ liệu như một nguồn đóng góp có thể truy vết và ghi nhận giá trị.
Nếu áp dụng vào AI Air Quality, câu chuyện không còn đơn giản là gom thật nhiều dữ liệu từ cảm biến rồi đưa vào mô hình. Vấn đề là dữ liệu đó đến từ đâu, có ổn định không, sensor có được đặt đúng vị trí không, dữ liệu có bị nhiễu không và nguồn nào thật sự giúp AI dự báo tốt hơn.
Trong thực tế, dữ liệu môi trường rất dễ bị đánh đồng.
Một cảm biến hoạt động đều trong nhiều tháng, được bảo trì tốt, cung cấp dữ liệu liên tục theo thời gian đáng lẽ phải có giá trị cao hơn một nguồn dữ liệu rời rạc hoặc thiếu kiểm chứng.
Nhưng nếu không có cơ chế ghi nhận rõ ràng, tất cả rất dễ bị trộn vào cùng một kho dữ liệu chung. Khi đó, người tạo ra dữ liệu tốt không có nhiều động lực để duy trì chất lượng, còn AI thì có nguy cơ học từ dữ liệu nhiễu.
Mình để ý nhiều dự án AI hiện nay nói rất nhiều về model, agent hay compute, nhưng lại ít nói sâu về dữ liệu đầu vào. Với air quality, đây là điểm cực kỳ quan trọng.
Một mô hình dự báo ô nhiễm không khí không thể chỉ dựa vào thuật toán đẹp. Nó cần dữ liệu đủ dày theo thời gian, đủ rộng theo khu vực và đủ sạch để phản ánh đúng thực tế.
Nếu sensor đặt sai chỗ hoặc dữ liệu bị lệch, AI có thể đưa ra cảnh báo sai. Trong mảng môi trường, cảnh báo sai không chỉ là lỗi kỹ thuật. Nó có thể ảnh hưởng đến cách người dân di chuyển, cách doanh nghiệp vận hành và cả cách thành phố ra quyết định.
Theo cách mình nhìn, OpenLedger $OPEN có thể tạo giá trị nếu giúp dữ liệu môi trường được nhìn nhận theo mức độ hữu ích thật sự.
Sensor nào đóng góp dữ liệu ổn định hơn, nguồn nào giúp mô hình dự báo chính xác hơn, cụm dữ liệu nào phản ánh tốt hơn một khu vực cụ thể, tất cả nên được ghi nhận rõ.
Đây là nơi cơ chế attribution trở nên quan trọng. Không phải dữ liệu nào cũng có giá trị như nhau, và không phải người đóng góp nào cũng nên được thưởng giống nhau.
AI Air Quality cũng là một use case hợp với dữ liệu chuyên ngành. Dữ liệu không khí có tính địa phương rất mạnh.
Một mô hình học từ dữ liệu ở thành phố này chưa chắc đã dự báo tốt cho thành phố khác. Ngay trong cùng một thành phố, khu trung tâm, khu ven đô, khu công nghiệp và khu dân cư cũng có hành vi ô nhiễm khác nhau.
Vì vậy, nếu có một mạng dữ liệu cho phép nhiều nhóm nhỏ, nhiều thiết bị và nhiều cộng đồng đóng góp dữ liệu theo khu vực, mô hình AI có thể tiến gần hơn đến dự báo vi mô thay vì chỉ đưa ra chỉ số chung chung.
Tất nhiên, mình không nghĩ cứ đưa sensor data vào blockchain là dữ liệu tự nhiên có giá trị.
Dữ liệu môi trường cần được chuẩn hóa, kiểm tra và đánh trọng số. Một sensor rẻ tiền nhưng đặt đúng vị trí và chạy ổn định vẫn có thể hữu ích.
Ngược lại, một thiết bị đắt tiền nhưng dữ liệu bị ngắt quãng hoặc thiếu bối cảnh cũng chưa chắc tốt. Điểm cần theo dõi ở OpenLedger là dự án có thể xử lý lớp chất lượng dữ liệu này tốt đến đâu, chứ không chỉ là số lượng dữ liệu được đưa vào hệ thống.
Điều mình thích ở narrative này là nó không quá xa đời sống.
Không khí chúng ta hít mỗi ngày có thể trở thành dữ liệu cho AI, nhưng dữ liệu đó chỉ thật sự có ý nghĩa khi biết nó đến từ đâu và được dùng như thế nào.
Nếu OpenLedger làm tốt phần truy vết, ghi nhận đóng góp và phân bổ giá trị, dữ liệu môi trường có thể không còn là những bảng số liệu khô khan nằm trong hệ thống giám sát.
Nó có thể trở thành một lớp dữ liệu chuyên ngành có giá trị kinh tế rõ ràng hơn.
Người vận hành sensor tốt có lý do để duy trì chất lượng. Nhà phát triển AI có nguồn dữ liệu đáng tin hơn. Còn người dùng cuối có thể được hưởng lợi từ các mô hình dự báo sát thực tế hơn.
Với mình, đây là góc đáng theo dõi của #OpenLedger : không phải chỉ “AI hóa” dữ liệu môi trường cho đẹp narrative, mà là thử giải quyết bài toán khó hơn.
Làm sao để dữ liệu thật, có bối cảnh thật và đóng góp thật được định giá công bằng hơn trong kỷ nguyên AI.
@OpenLedger #OpenLedger $OPEN