In most AI systems, data enters the model and disappears from view.That is the part I keep coming back to when thinking about OpenLedger.AI products often look clean from the outside. A user asks a question. A model gives an answer. Maybe the answer is useful, maybe it is not. But behind that simple interaction is a much messier reality: data had to be collected, cleaned, labeled, refined, organized, and tested before the model became useful.$OPEN #OpenLedger @OpenLedger
The problem is that most of this work becomes invisible.A legal researcher may provide useful contract examples. A finance expert may organize risk data. A medical team may clean domain-specific information. A developer may improve a dataset so a model responds better in one narrow area. But once that input enters the AI pipeline, it often gets absorbed into the model without a clear record of who contributed what, how useful it became, or whether it created value later.
That is the practical friction OpenLedger is trying to address.To me, OpenLedger’s stronger idea is not simply “AI plus blockchain.” That phrase is too broad and easy to repeat. The more interesting argument is that training data should not be treated like a one-time hidden input. It should be treated more like a traceable economic asset.
In simple terms, OpenLedger is asking a serious question:If data helps an AI system create value, should that contribution be visible, measurable, and rewardable?
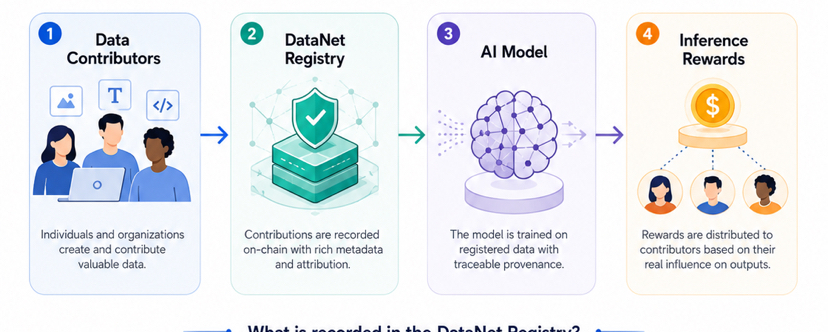
That is where DataNets become important.DataNets are designed to organize specialized datasets around specific domains or use cases. Instead of treating data as a random pile of information, the idea is to make contribution more structured. A dataset can have records around who contributed it, when it was added, what terms apply to it, and how it connects to model usage later.
That sounds basic at first, but in AI, that basic layer is often missing.A few proof points matter here.First, the DataNet registry gives datasets a clearer place inside the system. This matters because if data is going to become an asset, it needs some kind of visible identity. You cannot build a serious incentive layer around something that has no clear record.
Second, contributor identity gives the system a way to connect data back to the people or teams behind it. This does not automatically solve every reward problem, but it does create a better starting point than the usual black-box model pipeline.
Third, timestamps matter because they help show when a contribution entered the system. In fast-moving AI markets, timing can be important. If a dataset improves a model before a certain use case becomes valuable, that history should not simply disappear.
Fourth, license terms are important because data is not only technical. It is also legal and economic. If contributors want to share useful information, they need clearer rules around how that data can be used and what kind of value might come back to them.
Fifth, attribution records are the real heart of the idea. OpenLedger is not just trying to store data. It is trying to connect data influence to future model usage, especially when the model produces outputs during inference.
A simple example makes this easier to understand.Imagine a group of legal researchers builds a clean dataset around contract clauses. It includes examples of risk language, termination clauses, renewal terms, liability sections, and jurisdiction-specific wording. This dataset is not massive compared with general internet data, but it is highly useful for one specific task: contract review.
Now imagine a contract-review AI model uses that dataset during training or refinement. Later, businesses use the model to review real agreements. If the legal dataset helped the model understand clause risk more accurately, then OpenLedger’s idea is that this contribution should not vanish. The dataset should have a record. The contributor should have a trace. And if that data keeps influencing useful outputs, rewards should be able to flow back toward the people who helped create that value.
That is the economic shift.In normal AI systems, the model captures the attention. In OpenLedger’s framing, the data behind the model also becomes part of the value layer.This matters for crypto because crypto is at its best when it makes ownership, coordination, and incentives more transparent. AI has a huge coordination problem. Many people can improve a system, but only a few platforms usually capture the upside. If OpenLedger can make contribution visible and connect it to rewards, it gives crypto a more practical role in AI than just launching another token around a trending narrative.
It also matters for users and builders.For users, better data incentives could mean better specialized AI systems over time. People may contribute more carefully when they know their work can be traced and rewarded. For builders, it could create a stronger reason to develop niche datasets instead of chasing only model size. A smaller, cleaner, more useful dataset may be more valuable than a large but messy one.
But there is also a real tradeoff.OpenLedger has to separate genuine data influence from simple data volume. That is not easy.If the system mostly rewards people for uploading as much data as possible, it’ll probably just encourage spam, low-quality stuff, tons of duplicates, and shallow contributions that don’t really add much value.In that case, the incentive layer would become noisy instead of useful. The real challenge is measuring whether data actually improves model performance, not just whether it exists inside the system.
That is what I am watching next.I want to see whether OpenLedger can prove that attribution works in real AI usage, not only in theory. Can it show which datasets actually improved outputs? Can contributors understand why they were rewarded? Can builders trust the records? Can the system handle specialized domains where quality matters more than scale?
Because the biggest opportunity here is not just turning data into an asset.The bigger opportunity is turning useful data into a more fairly priced asset.
That distinction matters.If OpenLedger can make high-quality data more valuable than mass-uploaded data, then it could push AI incentives in a healthier direction. Instead of rewarding whoever dumps the most information into the system, the market could start rewarding people who provide data that actually makes models better.And that is the real question for me:
Can OpenLedger build an AI economy where quality data earns more than data volume?$OPEN #OpenLedger @OpenLedger 
Articol
Can OpenLedger Make Data a Real AI Asset?

--
Declinarea răspunderii: Include opinii ale terților. Acesta nu este un sfat financiar. Poate include conținut sponsorizat. Consultați Termenii și condițiile