
I was reading through OpenLedger’s architecture notes late at night a few days ago while the internet kept disconnecting every few minutes. One tab open for the docs, another full of random thoughts I kept rewriting because the same question would not leave my head.
What exactly is OpenLedger trying to become?
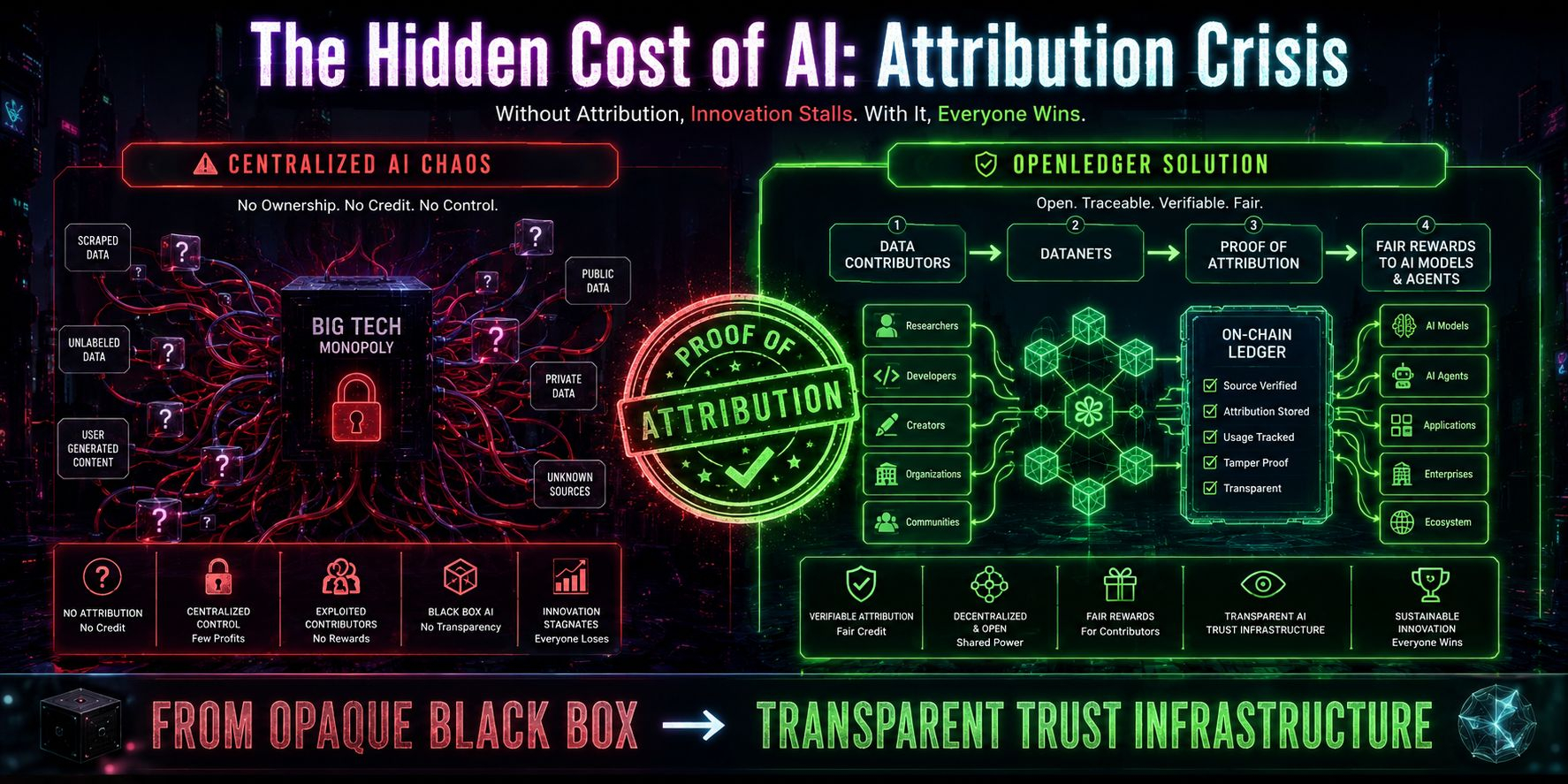
At first glance the answer feels obvious. AI data network. Contributors upload datasets. Models use them. Rewards get distributed. Standard crypto + AI structure.
But the longer I sat with it, the less convinced I became that this is mainly a data marketplace story.
It feels more like an accounting system for AI activity.
And honestly, I think that difference matters more than people realize.
Most AI discussions today still focus on capability: better models, faster inference, autonomous agents, cheaper compute, larger context windows.
Everything revolves around making intelligence more powerful.
But once AI systems start getting attached to real economic workflows, the conversation changes very quickly.
Because intelligence alone is not enough anymore.
The moment a model starts influencing fraud checks, insurance support, financial automation, compliance review or enterprise decisions, people stop asking whether the AI is impressive.
They start asking where the output came from.
Who contributed the data? Who verified it? What version was used? Can any of it be audited later if something goes wrong?
That entire layer feels strangely underdeveloped across most AI infrastructure conversations.
And that is why OpenLedger caught my attention.
The project seems heavily focused on attribution as a core primitive.
Not just storing data. Not just connecting contributors with buyers.
But tracking contribution lineage and routing value through that lineage in a structured way.
That sounds clean in theory.
In practice it becomes messy very fast.
Because AI training pipelines are not neat systems.
Data gets filtered, modified, mixed together, augmented, compressed, re-labeled and sometimes transformed so heavily that tracing influence becomes blurry.
People talk about attribution as if models maintain perfect ingredient lists internally.
Reality is nowhere near that simple.
Which is why I keep thinking the hard part of OpenLedger is not storage.
It is enforcement.
How does a network actually verify honest reporting?
If a model builder trains using multiple datasets, who confirms everything was disclosed correctly?

If some data influences a model indirectly, does that still count toward attribution?
And if disputes happen later, who decides what is valid?
The deeper I looked into it, the more the entire problem started feeling less technical and more economic.
Because attribution only matters if buyers trust it enough to pay for it.
That part is important.
A lot of crypto networks look healthy early because emissions create temporary activity. Uploads increase. Wallet counts grow. Transactions move. Everything appears alive.
But emissions are not the same thing as demand.
Long term sustainability only happens when outside buyers consistently spend real money because the coordination layer provides genuine operational value.
That is where things become harder.
Imagine a payments company training a fraud detection model.
The useful information is not generic internet data. It is constantly evolving transaction patterns, merchant descriptions, language variations, chargeback explanations and behavioral signals that shift over time.
The model needs fresh labeled data continuously or performance starts degrading.
In theory, OpenLedger could coordinate that process: contributors provide data, validators check quality, model builders retrain systems, payments route back through contribution layers.
Compared to traditional data vendors, the appeal becomes transparency and programmable payouts.
But enterprises usually care less about ideological openness and more about predictability.
That creates tension immediately.
Centralized vendors may actually feel operationally safer because accountability stays concentrated.
One provider. One contract. One support structure if something breaks.
Decentralized coordination sounds efficient conceptually, but if it introduces too much friction, serious buyers may simply avoid it.
That is why I think OpenLedger’s real challenge is not whether the technology works.
It is whether decentralized attribution can become operationally simpler than existing alternatives.
That is a very different type of problem.
Then there is the issue every open network eventually runs into: incentive distortion.
If rewards are attractive enough, people will optimize around them.
Duplicate uploads. Low-effort labeling. Questionable licensing. Spam datasets. Manipulated quality metrics.
Crypto networks always discover this eventually.
Which means validators become extremely important.
Some layer has to decide what qualifies as useful contribution and what does not.
But once validation starts concentrating around a small group of trusted actors, decentralization pressure starts changing shape.
That does not automatically kill the model.
It just means coordination problems do not disappear because a protocol exists.
They usually reappear somewhere else.
I am also still unsure about the token structure long term.
From what I understand, $OPEN appears connected to multiple functions at once: bootstrapping incentives, validation coordination, and payment settlement.
Maybe that works.
But multi-role tokens can sometimes create confusing economic signals because emissions temporarily compensate for weak organic demand.
A network can appear active while still depending heavily on internal reward loops.
That is why the metrics I would watch are probably less exciting than most people expect:
how much payout volume comes from actual buyers versus emissions
validator concentration over time
rejection rates for low-quality datasets
dispute frequency and resolution outcomes
repeat buyer retention tied to production usage instead of experimental pilots
Those numbers tell a more honest story about whether the coordination layer is becoming economically useful.
Because the longer I think about OpenLedger, the less it feels like a normal AI token narrative.
It feels like an attempt to solve a much quieter problem.
AI systems are becoming commercially important before the infrastructure for attribution and accountability is mature enough to support them properly.
That gap may eventually matter more than raw model performance itself.
Still early. Still uncertain. Still plenty of reasons to stay skeptical.
But I do think the market may be misunderstanding what category OpenLedger is actually trying to enter.
This may not really be a compute race.
It may be a trust infrastructure race.
And those systems usually become important very slowly at first, then all at once.