

Observ că pe piața AI oamenii sunt obsedați de rezultatele modelelor de inteligență, dar petrec mult mai puțin timp gândindu-se la mâinile invizibile care le-au construit efectiv.
Tratem AI-ul de parcă ar fi o divinitate auto-generatoare. Sărbătorim rezultatele, ajustăm prompturile și evaluăm performanța, presupunând că infrastructura de antrenament de bază este pur și simplu un activ public pasiv.
Nu este.
Este o agregare masivă de muncă umană necompensată.
Aceasta este problema contribuabilului invizibil.
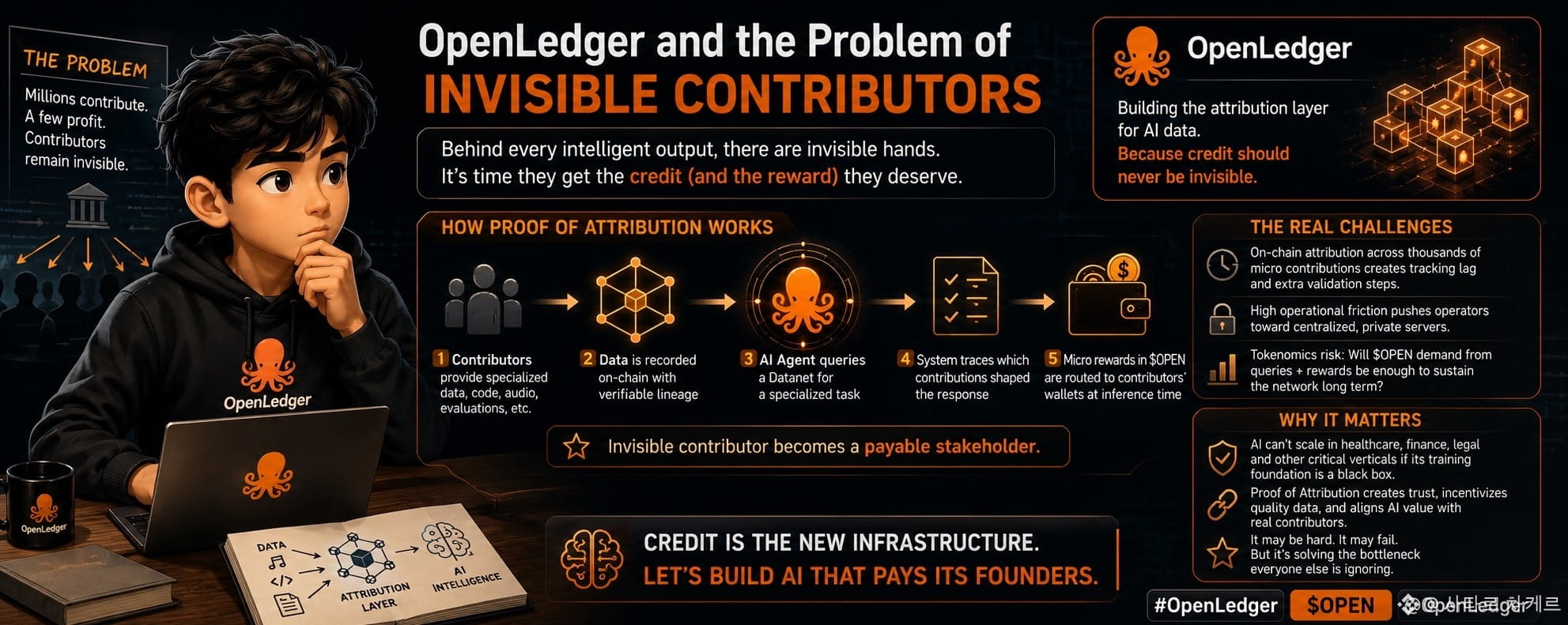
Milioane de oameni scriu cod, transcriu audio, structurează date specifice domeniului și evaluează răspunsurile modelului pentru a construi seturile de date care alimentează inteligența modernă. Dar când ciclul economic se închide, valoarea curge complet către un grup restrâns de companii de modele centralizate. Creatorii reali ai inteligenței rămân total invizibili.
Asta e parțial motivul pentru care OpenLedger mi-a atras atenția, deși poate nu din motivul evident.
Cei mai mulți oameni privesc OpenLedger doar ca pe o altă poveste standard de bază de date AI. Contributorii încarcă date, rețeaua le împachetează, iar dezvoltatorii le consumă. O abordare familiară din Web3. Prezentare ușoară.
Dar cred că acea interpretare ratează schimbarea mai greu de realizat.
Ce se întâmplă dacă adevărata provocare nu este doar colectarea datelor mai repede, ci și făcând influența datelor permanent vizibilă?
Sună abstract până te gândești cum funcționează de fapt AI-ul specializat. Colectările generale de date de pe internet și-au atins limita; AI-ul specializat necesită inteligență specifică, curată. Obținerea acelei adâncimi este imposibilă dacă contributorii rămân invizibili pentru că nu au niciun stimulent să participe.
Acolo este locul unde Proba de Atribuire schimbă dinamica.
Dacă OpenLedger reușește să mapeze linia de date pe lanț, datele nu mai sunt o marfă statică pe care o vinzi o dată unui server corporativ și uiți de ea. Devine un obiect economic activ, urmărit.
Când un agent AI interoghează un Datanet specializat, sistemul urmărește criptografic care contribuții au modelat răspunsul. Atribuirea redirecționează automat recompensele mici înapoi în portofelul contributorului la momentul inferenței.
Contributorul invizibil devine brusc un stakeholder plătit.
Cel puțin, asta este teoria.
Dar realitatea ingineriei este mult mai complicată.
Urmărirea atribuirii pe lanț prin mii de contribuții mici introduce un decalaj vizibil în urmărire și pași suplimentari de validare cu care utilizatorii obișnuiți se confruntă imediat.
Dacă fricțiunea operațională este prea mare, operatorii vor căuta scurtături. Serverele private centralizate câștigă adesea pur și simplu pentru că ușurința operațională cântărește mai mult decât puritatea conceptuală.
Și există întrebarea despre tokenomics.
Dacă fiecare interogare necesită rutare complexă și recompense mici în $OPEN , generează rețeaua suficientă cerere organică de tranzacții pentru a compensa emisia de tokenuri sau este doar o viteză speculativă temporară?
Asta e un risc masiv.
Dar tensiunea este structural reală.
AI-ul nu poate scala în fluxuri de lucru verticale precum sănătatea, finanțele sau conformitatea legală dacă fundația sa de instruire rămâne o cutie neagră de intrări nevalidate.
Proba de Atribuire stă chiar la acel punct de fricțiune.
Ar putea eșua pentru că coordonarea blockchain-ului de bază este prea complexă.
Dar încearcă să rezolve exact blocajul pe care majoritatea pieței îl ignoră.
Ceea ce de obicei înseamnă că este singurul lucru demn de atenție.