
OpenLedger is one of those projects I don’t want to overpraise too early, because
I’ve watched this market recycle the same AI narrative until there’s almost nothing left in it. Every cycle gets its favorite wrapper. Last time it was metaverse. Then gaming. Then modular everything. Now AI gets dragged into every pitch deck like a magic sticker.
So I’m tired.
But OpenLedger is at least pointing at a real wound.
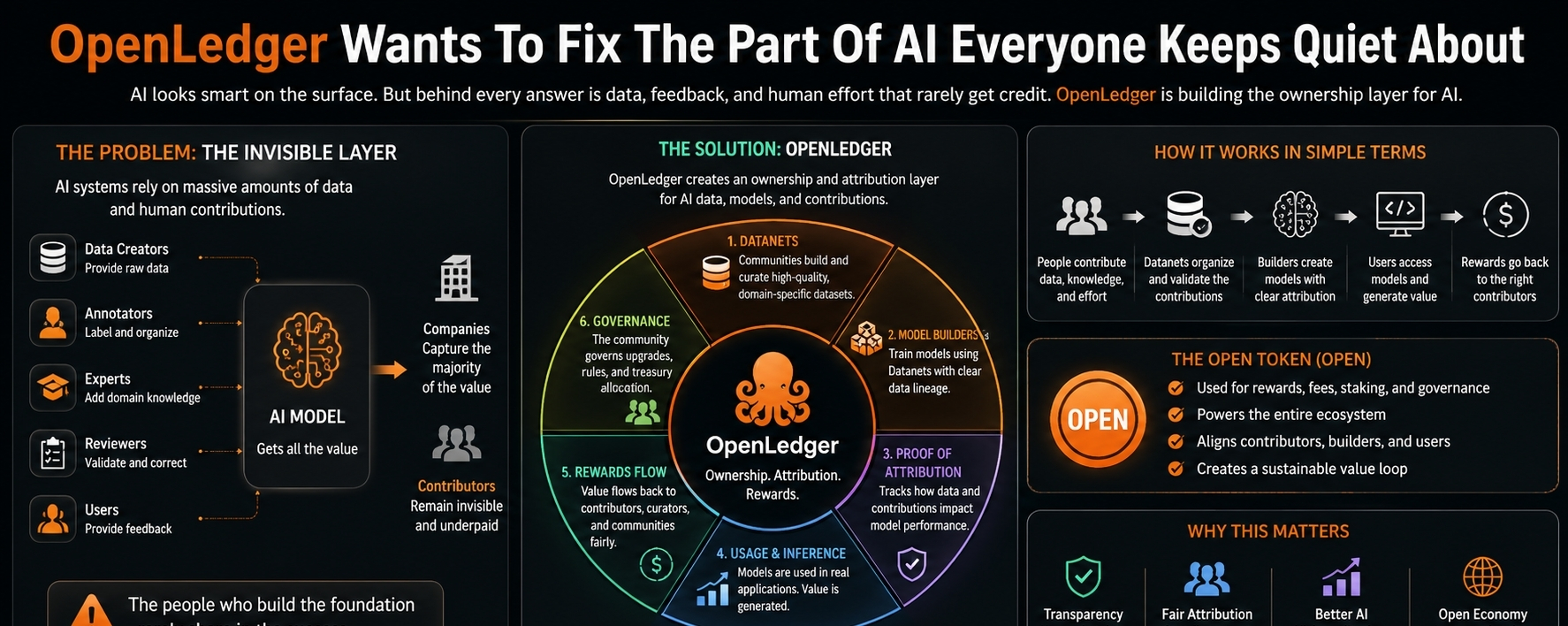
The project is not trying to make AI look prettier from the outside. It is going after the part most people skip because it is slow, messy, and hard to package into a clean thread: ownership. Who owns the data that trains the model? Who gets paid when a dataset makes an AI system better? Who receives credit when thousands of small contributions are swallowed into one polished output?
That question has been ignored for too long.
AI does not become useful by itself. There is always something underneath it. Data. Feedback. Human corrections. Labeled examples. Domain knowledge. Years of work from people who never appear in the final product. The model gets smarter, the product gets sold, the valuation climbs, and the original contributors are pushed into the background like dust under the machine.
OpenLedger is trying to drag that hidden layer into view.
That is the part I care about. Not the token first. Not the chart. Not the usual noise around listings, volume spikes, and short-term liquidity. Those things come and go. I’ve seen enough candles turn into graves. What matters here is whether OpenLedger can make AI contribution traceable in a way that actually survives outside of marketing.
The idea is simple, maybe too simple when you first hear it. If a dataset helps train a specialized model, and that model later creates value, the contributors behind that dataset should not just disappear. They should have a visible claim. A record. Some economic memory.
That sounds fair. It also sounds brutal to execute.
Because AI attribution is not clean. A model does not behave like a spreadsheet. It absorbs patterns, compresses signals, mixes them, forgets some things, exaggerates others, and spits out an answer that may have been shaped by countless inputs. So when a project says it can track contribution and reward the right people, I don’t clap immediately.
I look for the cracks.
OpenLedger’s Datanet idea is where the project gets interesting. A Datanet is basically a focused data network where contributors can build around specific categories of knowledge. Not random data dumping. Not useless uploads just to farm rewards. At least, that is the version that would matter. The useful version is a living, curated data layer that helps train specialized AI models for narrow use cases.
That matters because the future of AI probably is not one giant model pretending to understand everything equally well. That story already feels stretched. Serious use cases need sharper data. A security model needs audit patterns and exploit history. A finance model needs cleaner market structure. A legal model needs legal reasoning, not internet soup. A healthcare model needs careful context, not scraped noise dressed up as intelligence.
OpenLedger is betting that these specialized data layers will become valuable assets.
I can see the logic.
Data is the real grind behind AI. People talk about agents, automation, and outputs because those things are easy to sell. But the strength of an AI system usually comes from the boring foundation: the quality of what trained it, who reviewed it, who corrected it, who kept the garbage out. That work is not glamorous. It is slow. It is repetitive. It has friction. And because it happens below the surface, the market usually underprices it until it becomes impossible to ignore.
OpenLedger wants to make that foundation ownable.
That word gets abused in crypto, so I’m careful with it. Ownership here should not mean a cute badge or a leaderboard position. It should mean that if your data improves a model, your contribution can be tracked. If the model earns, the reward path does not stop at the interface. If a network of contributors builds something useful, the value does not get extracted and locked away by whoever controls the final product layer.
That is the dream version.
The real test, though, is whether OpenLedger can keep the system from becoming another farming playground. Because the second rewards are attached to contribution, people will try to game it. They will upload weak data. Duplicate data. Noisy data. They will chase incentives, not quality. This is where many crypto projects quietly rot. They reward movement instead of usefulness, and for a while it looks alive because dashboards are blinking.
Then the incentives slow down.
Then the users vanish.
So when I look at OpenLedger, I’m not asking whether the idea sounds good. It does. I’m asking whether the network can separate real contribution from recycled junk. Can it reward impact instead of activity? Can it attract people who actually have valuable data? Can it give developers a reason to build models there instead of using easier, closed systems?
That is where this either becomes something serious or just another AI-cycle artifact.
OPEN, the token, sits inside the system as the economic unit for participation, rewards, governance, and model-related activity. Fine. That part is expected. Tokens always get designed to touch everything. The harder question is whether any of those token flows become organic. Not campaign-driven. Not inflated by short-term speculation. Not propped up by people hunting points and exits.
Real usage has a different smell.
You see builders staying even when the chart looks tired. You see contributors caring because the reward path is clear. You see models being used because they solve something specific, not because the narrative is warm. You see less noise and more repeat behavior.
That is what I’m looking for.
OpenLedger is also working in a market that is already exhausted. AI crypto has been stretched thin by too many shallow projects. Everyone claims to be building the future. Most are just recycling the same pitch with different colors. That makes it harder for a project like OpenLedger, because even if the idea is real, it still has to fight through the fog created by everyone else.
But maybe that is why the ownership angle matters.
The current AI economy has a broken memory. It remembers the model. It remembers the app. It remembers the company selling access. It does not remember the small contributors, the data sources, the reviewers, the people who made the system sharper one input at a time. That imbalance cannot stay invisible forever, especially as AI moves deeper into serious industries where provenance, licensing, and trust actually matter.
OpenLedger is trying to build for that pressure.
I don’t think this is an easy road. High-quality data does not just walk into an open network because a token exists. Serious contributors need trust. They need privacy. They need clear economics. They need confidence that their work will not be swallowed, copied, and underpaid all over again. Developers need tooling that does not slow them down. Users need models that are worth calling.
That is a lot of weight for one project to carry.
Still, the direction is worth watching. Not because OpenLedger has solved everything. It has not. Not because the market will suddenly become rational around AI tokens. It probably will not. But because the project is focused on a problem that feels real beneath all the noise: AI needs an ownership layer, or the same extraction pattern keeps repeating.
The model gets the attention.
The data does the heavy lifting.
OpenLedger is trying to make the heavy lifting visible.
I’m not ready to call it anything bigger than that yet. In this market, patience is cheaper than hype. But if specialized AI keeps growing, and if data ownership becomes impossible to ignore, then the question around OpenLedger becomes pretty direct.