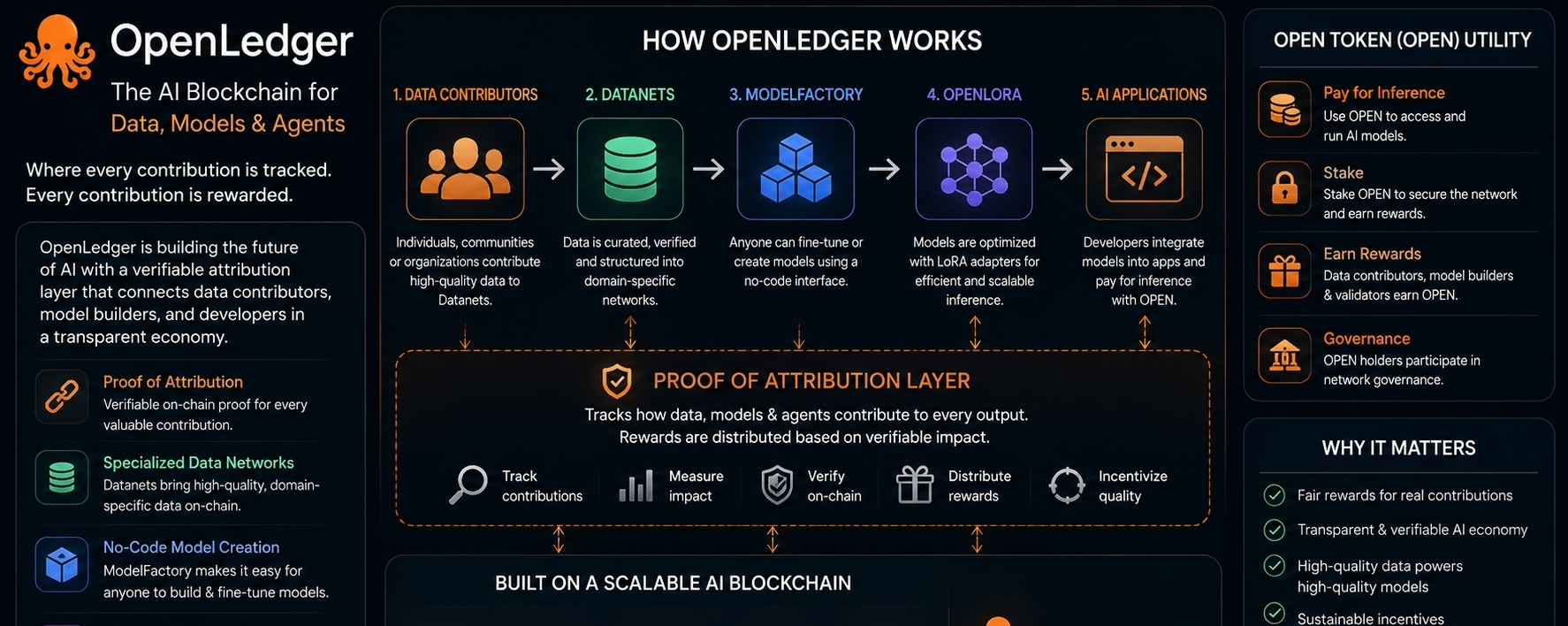

OpenLedger caught my attention because it is not trying to sell only a token story. At least, that is not the part that feels worth taking seriously. The more interesting thing is the problem sitting underneath it: when a model gives an answer, who actually helped create that answer?
That sounds simple until you think about the full chain behind it. A model is not just a model. It has training data, fine-tuning data, adapters, prompts, builders, validators, inference systems, and users calling it through applications. By the time an output appears on the screen, many inputs have touched it. Most of those inputs disappear from view.
OpenLedger is trying to make that hidden chain visible enough that people can be paid for the parts they actually contributed.
That is the core idea. Not just “put AI on blockchain.” Not just “make data monetizable.” The real question is sharper: if someone contributes useful data, and that data improves a model, and that model later earns fees, can the system prove that contribution mattered?
OpenLedger calls this Proof of Attribution.
This is where the project becomes interesting, but also where it becomes difficult to judge from the outside. Attribution is easy to describe. It is much harder to make fair.
Data is messy. Some data is original. Some is copied. Some is useful once and useless later. Some looks valuable because there is a lot of it, but adds almost nothing. Some improves a model in one domain while weakening it somewhere else. If rewards are attached to contribution, people will quickly learn how to game the system.
That is why OpenLedger’s idea only works if the attribution layer is strong. The project needs to know not only who submitted data, but whether that data actually influenced a model’s behavior. It also needs to punish low-quality, repeated, or harmful submissions. Without that, the system becomes another farming machine where people upload anything just to chase rewards.
The Datanet idea is the cleanest part of OpenLedger. A Datanet is basically a focused data network around a specific domain. Instead of pretending one large general dataset can solve everything, OpenLedger pushes toward specialized data. That makes sense. Most useful models are not useful because they know a little about everything. They are useful because they work well inside a narrow area.
A finance model needs financial context. A legal model needs legal structure. A healthcare model needs careful domain data. A coding model needs examples that are actually correct. General models can sound confident in all these areas, but confidence is not the same as reliability.
This is where OpenLedger’s approach feels practical. If communities or organizations can build focused datasets, train models around them, and receive payment when those models are used, there is a real economic idea here.
But there is also a trust problem.
Not every domain should be handled the same way. Public Web3 data is different from medical data. Open-source code is different from private enterprise documents. Community knowledge is different from licensed material. A network can track provenance, but it cannot automatically solve permission, privacy, or quality. Those parts still need rules, review, and enforcement.
That is the part people often skip when talking about data markets. The hard problem is not collecting data. The hard problem is collecting data that is legal, useful, clean, and trusted.
OpenLedger seems aware of this, but awareness is not execution. The system has to prove that Datanets can stay useful after incentives arrive. Incentives bring contributors, but they also bring spam.
The other important piece is ModelFactory. This is OpenLedger’s no-code model creation layer. The idea is that people should be able to fine-tune or create specialized models without needing to manage complex machine-learning infrastructure themselves.
That choice makes sense. The people who understand valuable domain data are not always engineers. A researcher, analyst, community expert, or business operator may know exactly what kind of data matters, but may not want to touch command-line tools or training scripts.
A simple interface can bring those people in.
But no-code tools have a weakness. They can make hard things look easy.
Fine-tuning a model is not just uploading data and pressing a button. The data format matters. The quality matters. The evaluation matters. A model can appear improved while becoming worse in ways users do not immediately notice. If OpenLedger wants ModelFactory to be more than a nice dashboard, it needs to show users what changed after training.
Did the model improve?
Where did it improve?
Where did it fail?
Which data helped?
Which data was ignored?
How does it compare to the earlier version?
These questions matter because model creation without evaluation becomes theater. A clean interface is not enough. Users need reasons to trust the result.
OpenLoRA is less flashy, but it may be one of the more useful parts of the system. OpenLedger wants to support many specialized models and adapters. Running each one separately would be expensive and inefficient. LoRA adapters make this more manageable because they allow smaller fine-tuned versions to run without copying full models every time.
This is practical infrastructure. It shows that OpenLedger is not only thinking about ownership and rewards. It is also thinking about cost.
That matters because specialized models only work economically if they are cheap enough to serve. If every niche model becomes expensive to deploy, developers will avoid them. OpenLoRA is OpenLedger’s attempt to make many fine-tuned models usable without turning inference costs into a problem.
The chain layer is there for records and payments. OpenLedger uses an Ethereum-compatible L2 structure, with OPEN used for gas, inference payments, staking, governance, and rewards. This is not the most unusual part of the project, and that is probably good. The project already has enough complexity. It does not need to reinvent everything at once.
The better version of OpenLedger makes the blockchain layer feel quiet. Users should not have to think about infrastructure all the time. A data contributor should care about whether their contribution was accepted, whether it was used, and whether they were paid fairly. A developer should care about model quality, API reliability, cost, and logs. The chain should keep receipts in the background.
That is where OpenLedger has to be careful. Crypto products often make the wallet the center of the experience. For this project, the center should be attribution. The user should be able to see what happened and why.
The developer side looks more grounded than I expected. OpenLedger uses familiar API patterns, which is smart. Developers do not want to learn a strange new system just to test a model. If they can call models in a way that feels close to existing AI APIs, the barrier is lower.
The spend-tracking layer also matters. Usage logs, token counts, model names, request IDs, timestamps, and metadata are not exciting, but they are necessary. Serious users need to know what they used, what it cost, and whether the system behaved as expected.
A model network without good usage records is not ready for real applications.
The token design is easy to understand. OPEN is used across the system: fees, staking, governance, model access, inference, and rewards. On paper, the loop is simple. Contributors provide useful data. Builders create better models. Applications pay to use those models. Rewards flow back to the people who helped create value.
That loop sounds good.
The question is whether real demand appears.
Many crypto networks can create early activity through rewards. People join, upload, run nodes, complete tasks, and talk about the project. Dashboards look alive. But that does not always mean the product has real users. OpenLedger needs developers and applications that use its models because the models are useful, not because there is a campaign attached.
That is the difference between a working network and a temporary incentive machine.
The most important signal will not be community noise. It will be inference demand. Are applications actually calling these models? Are users returning? Are certain Datanets producing better results? Are contributors earning because their data matters, not because the system is trying to bootstrap activity?
That is what I would watch.
Compared with other projects in the same area, OpenLedger feels more focused on attribution. Bittensor is broader and more market-like, with subnets producing different kinds of digital work. Vana is more focused on user-owned data. Sahara has a strong data and agent infrastructure angle. OpenLedger’s specific bet is that the contribution chain behind models can be measured and paid.
That is a narrower bet, but it is also easier to judge.
If attribution works, OpenLedger has a real reason to exist.
If attribution becomes vague, gameable, or hard to verify, the project loses its strongest point.
The parts that feel believable are the practical ones. Datanets make sense because specialized models need specialized data. ModelFactory makes sense because useful contributors are not always technical. OpenLoRA makes sense because serving many adapters needs cost control. Familiar APIs make sense because developers hate unnecessary friction. Spend logs make sense because real usage needs accounting.
The unfinished part is trust.
How transparent are attribution scores?
How are duplicate datasets handled?
What happens when bad data gets rewarded?
Can contributors dispute decisions?
Can model builders reject weak data?
Can private or licensed data be used safely?
Can non-technical users understand why they earned what they earned?
These are not side questions. They are the product.
OpenLedger is trying to solve a real problem: model outputs have supply chains, and those supply chains are mostly invisible. The project wants to attach memory, measurement, and payment to that chain.
That idea is believable.
The execution still needs proof.
Not proof in the marketing sense. Real proof. Proof that useful data can be identified. Proof that contributors can be rewarded fairly. Proof that developers will use the models after incentives fade. Proof that the system can resist spam and still produce something valuable.
OpenLedger is not interesting because it says people should monetize data. Everyone says that now.