I once noticed something during a very busy trading evening that completely changed the way I look at crypto infrastructure.
A simple onchain confirmation that normally took seconds suddenly started behaving unpredictably. One request would clear immediately, another would remain pending, and some data feeds were updating at different speeds entirely. Nothing had technically “collapsed,” but the system no longer felt coordinated. It felt crowded.
That experience stayed in my mind because it reminded me that infrastructure problems are usually not visible during quiet periods. They become obvious only when activity rises and every layer of the network starts competing for resources at the same time.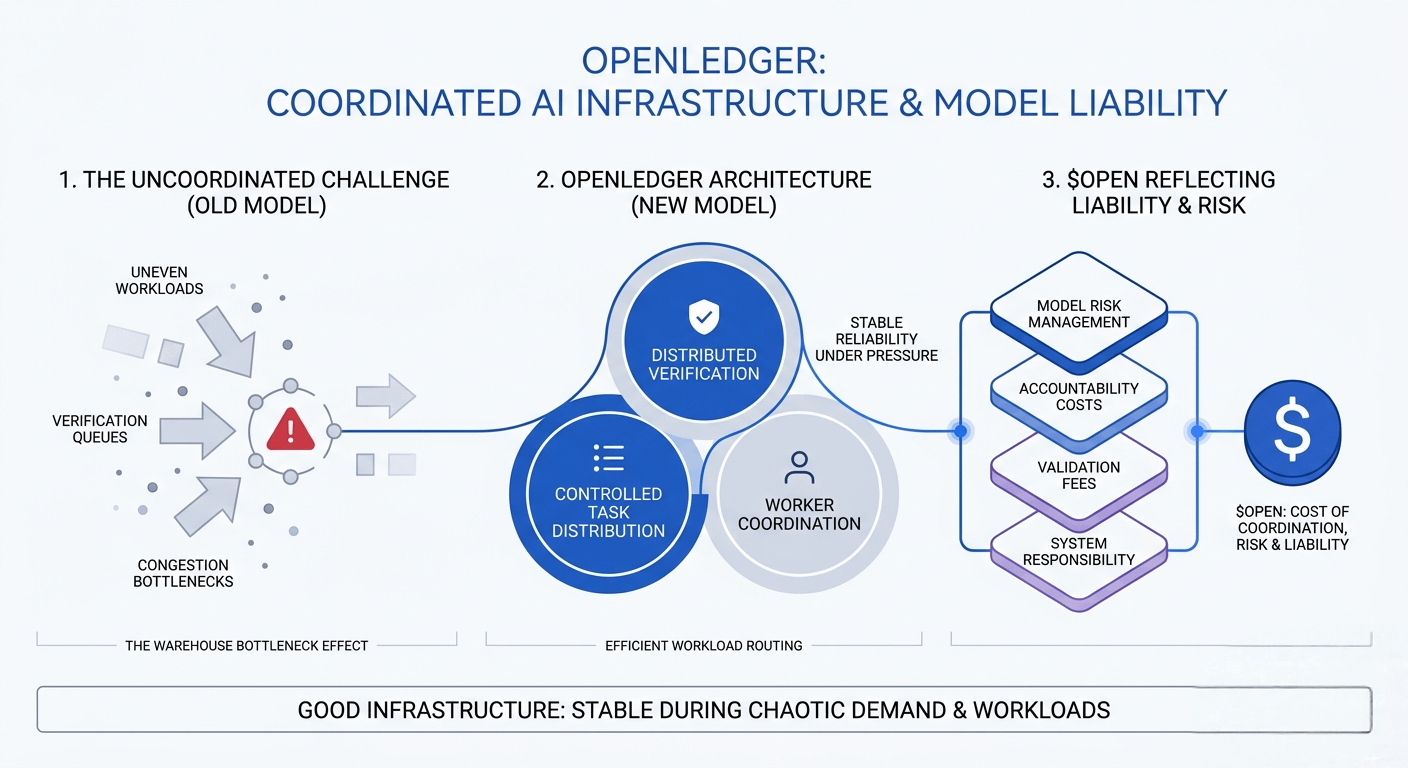
After seeing this happen across different ecosystems, I stopped caring so much about headline performance numbers. What matters in practice is how a system behaves when workloads become uneven, verification requests increase, and multiple operations begin fighting for ordering priority simultaneously.
In my experience watching networks evolve, congestion is rarely just about transaction volume. It is often a coordination problem.
One part of the system becomes overloaded while another remains underused. Verification queues start forming. Requests arrive faster than they can be processed. Eventually the network spends more time trying to organize work than actually completing it efficiently.
The easiest way I explain this to myself is through warehouse logistics.
Imagine a large shipping center during holiday season. The issue is not simply the number of packages entering the building. The real challenge is sorting, routing, checking, and distributing everything without creating bottlenecks between departments. If too many packages arrive at one checkpoint at once, the entire operation slows down even if workers elsewhere are free.
From a system perspective, blockchain coordination and AI infrastructure are starting to face similar pressures.
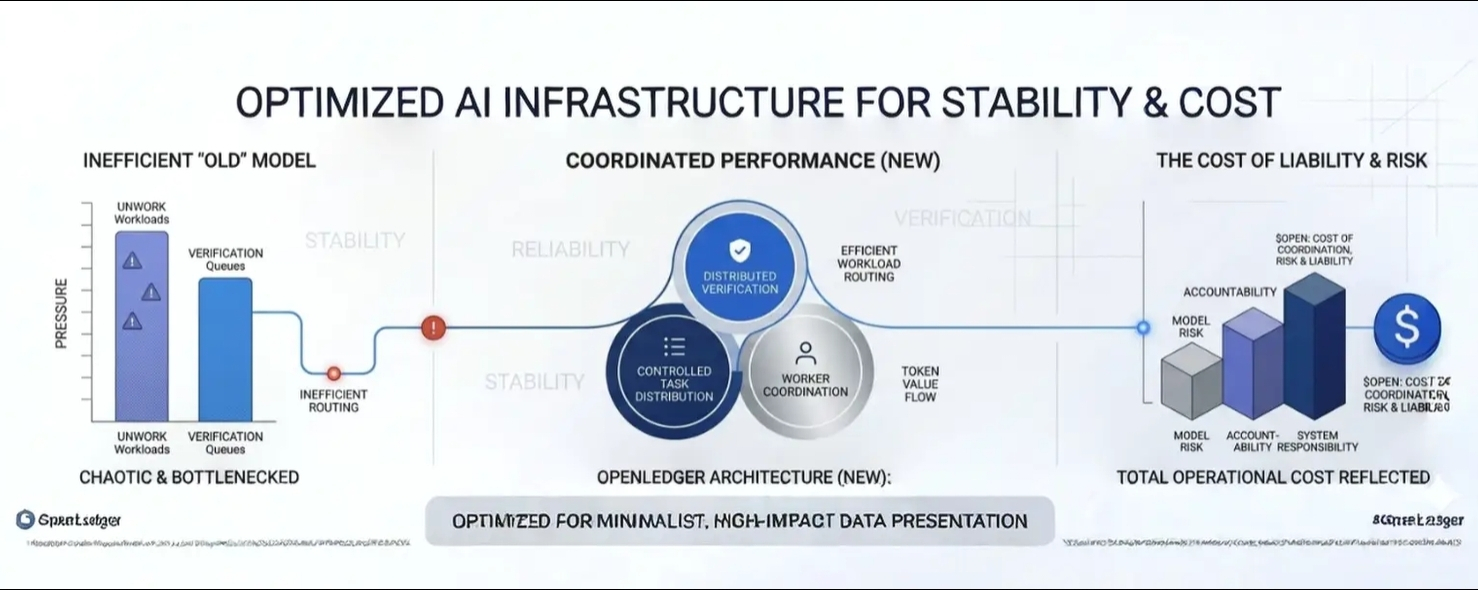
What caught my attention is how @OpenLedger seems to approach this from a structural angle rather than treating scalability as only a speed problem. The design appears more focused on how workloads are separated, verified, and coordinated under pressure.
That distinction genuinely interests me.
A lot of infrastructure discussions focus heavily on output, but what interests me more is what happens behind the scenes when systems need to maintain reliability during unpredictable demand spikes. That is usually where weaknesses appear first.
The architecture in white OpenLedger appears designed around controlled task distribution, verification flow, and worker coordination instead of forcing every operation through the same path. I also find it interesting how the framework seems aware that AI systems introduce another layer of operational responsibility model reliability, verification cost, and accountability.
To me, that is where $OPEN starts reflecting something deeper than simple infrastructure activity.
It quietly represents the growing cost of coordination, validation, and system responsibility inside distributed AI environments. Those invisible operational layers are becoming just as important as raw computation itself.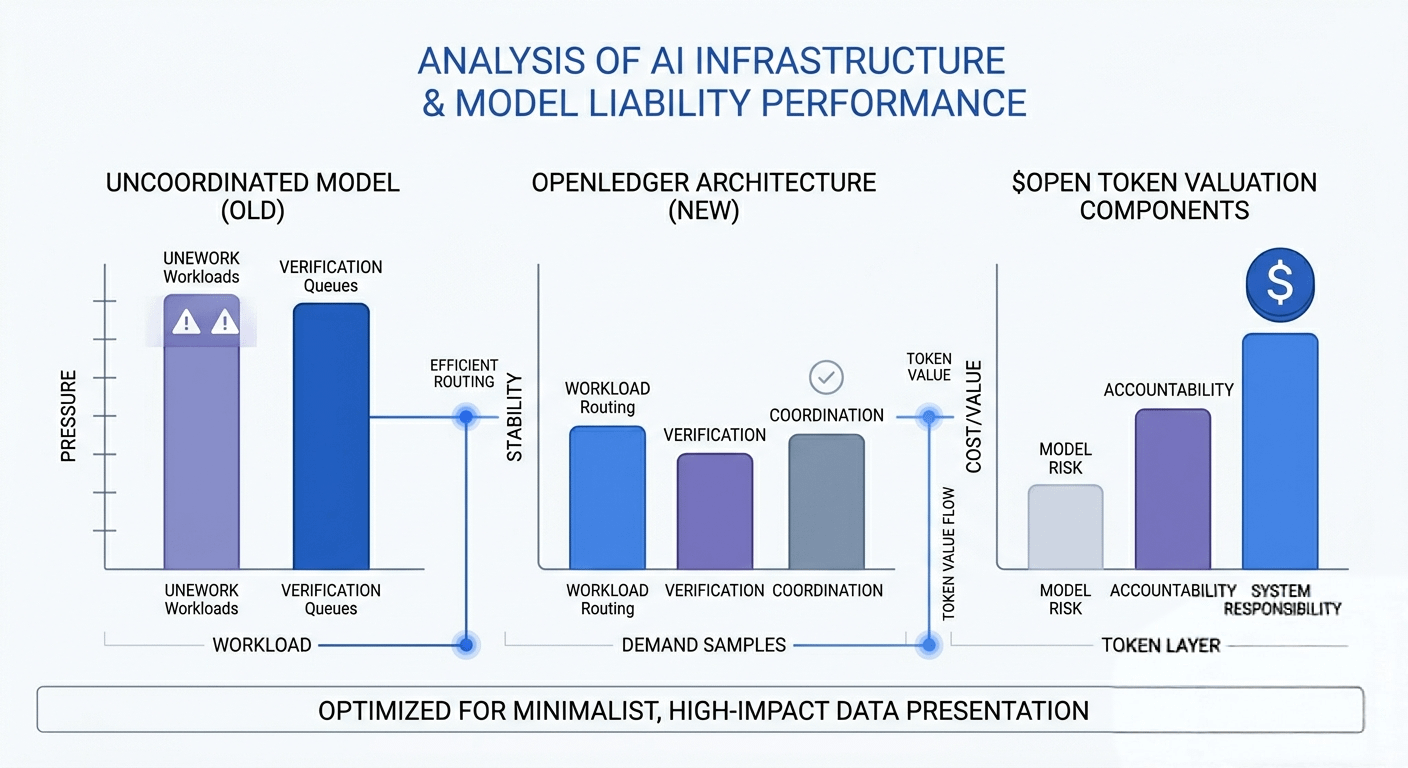
Good infrastructure is rarely the loudest part of a network.
Most people only notice it when it fails.
But the systems that leave the strongest impression on me are usually the ones that remain stable when demand becomes chaotic, workloads become uneven, and pressure begins exposing weaknesses everywhere else.