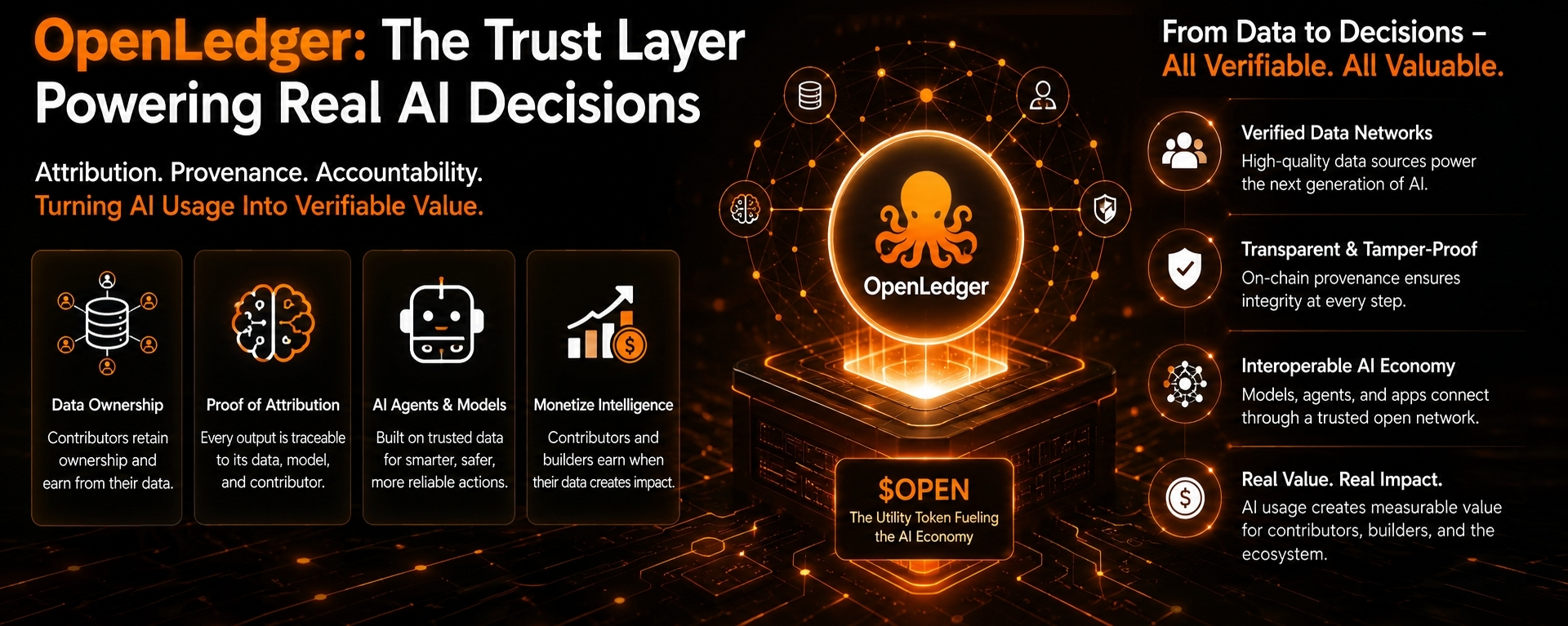

OpenLedger started making more sense to me when I stopped looking at it like another “AI infrastructure” project and started thinking about what actually happens when too many AI systems need reliable information at the same time.
Most people only see the clean side of AI. You type something, wait a second, and get an answer. Simple. But the deeper you go, the messier it gets. Especially when AI starts touching money, trading, automation, research, or anything that carries real consequences.
That is where trust becomes a problem.
A chatbot can guess and nobody really cares. But if an AI agent is helping move capital, scanning market conditions, or handling important decisions, people want more than a polished answer. They want to know where the information came from. They want to know if the data is reliable. They want to know the system is not just stitching together random noise and calling it intelligence.
That is the part I think OpenLedger is trying to solve.
The project talks a lot about data ownership, attribution, models, and AI agents, but underneath all of that, the real idea feels much simpler. AI systems are going to need cleaner inputs and better records if people are going to trust them long term.
And honestly, that feels true already.
The internet is filling up with generated content, copied information, recycled opinions, fake engagement, and low-quality data. AI models are learning from all of it. At some point, the valuable thing is not just producing more answers. The valuable thing becomes knowing which information is actually worth using.
That changes everything.
Suddenly, the system that can track useful data, verify where it came from, and connect it back to the output starts becoming important. Not flashy important. Quietly important. The kind of infrastructure people ignore until they depend on it.
That is why $OPEN feels more interesting to me than the usual AI token story.
I do not think the opportunity is simply “more AI usage means token goes up.” That idea is too shallow. The bigger opportunity could come from AI systems needing trusted context before they can make decisions people are willing to rely on.
Think about an AI trading assistant for a second.
If it shows a route or a strategy, serious users will not just care about the final result. They will ask better questions. What data did it use? Was the information fresh? Was liquidity actually there? Did the agent pull from trusted sources or just generate something that looked convincing?
Those questions matter more as AI becomes more powerful.
And that is where OpenLedger could fit in.
Not as another chatbot project. Not as another flashy AI narrative. More like a system sitting underneath the process, helping organize which data gets trusted, reused, and connected to the final output.
That may sound boring at first, but boring systems usually become valuable when pressure increases.
Crypto already showed this with blockspace. Nobody cared much until demand exploded and people needed reliable settlement fast. Storage became important when people needed permanent records. In AI, the pressure point might end up being trust itself.
Because there is going to be too much content.
Too much data.
Too many agents.
Too many generated answers.
When everything can be created instantly, people start caring more about what is real.
That is why attribution matters more than people think. Not just for giving credit, but for helping systems understand what information deserves weight. If certain data keeps improving outcomes, the system should remember that. If contributors provide valuable inputs repeatedly, there should be a way to track that value over time.
Otherwise AI just becomes a giant pile of disposable output.
And I think that is the hidden risk a lot of people are ignoring right now. Everyone talks about smarter models, faster models, cheaper models. Very few people talk about the quality of the information feeding those systems once the internet becomes flooded with synthetic content.
OpenLedger seems focused on that layer.
The hard part, though, is proving real demand.
A lot of crypto projects can create activity for a while through rewards, campaigns, and speculation. That is easy. The harder thing is building something people keep coming back to because they genuinely need it.
That is the difference I would watch closely with OpenLedger.
Do AI systems actually depend on these verified records over time?
Do builders keep using the platform because it improves outputs?
Do agents rely on trusted context because it reduces mistakes or increases confidence?
That is where the real answer probably is.
Because if OpenLedger becomes part of the process that helps AI systems separate useful information from noise, then $OPEN becomes more than another trend token. It becomes connected to something much harder to replace.
And honestly, that feels like the more important story here.
Not the hype around AI.
The pressure AI creates once trust starts becoming scarce.