It was late, my screen was too bright, and I had too many OpenLedger tabs open. Datanets here. ModelFactory there. OpenLoRA, AI Studio, Proof of Attribution, agents, data monetization, model monetization. All the right pieces were sitting in front of me, and for a few minutes I honestly liked the shape of it.
Then the annoying thought hit me.
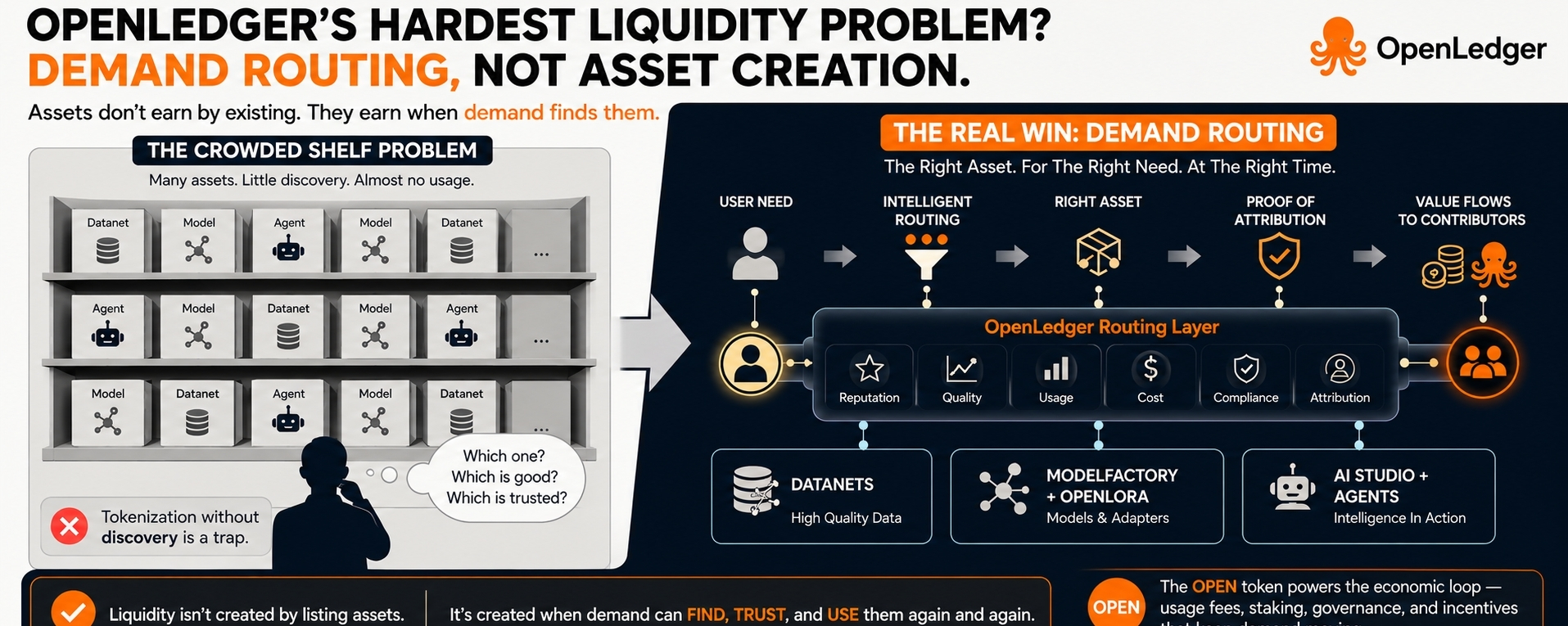
What happens when there are hundreds or thousands of these AI assets, and most of them are just sitting there?
Because let’s be honest, crypto-AI loves counting the wrong things. Total models registered. Data on-chain. Number of agents launched. Number of contributors. Number of assets created. It looks great in a dashboard. It looks great in a campaign post. It makes the ecosystem feel alive.
But here is the ugly truth. A model nobody finds is not liquid. A Datanet nobody uses is not earning. An AI agent nobody routes demand through is just another object on a crowded shelf.
That is the OpenLedger question I cannot ignore.
OpenLedger is not weak because it tries to monetize data, models, and agents. That is actually the interesting part. Datanets give data a structure. ModelFactory gives builders a way to create specialized models. OpenLoRA makes adaptation and deployment lighter. AI Studio gives users a place to build and interact. Proof of Attribution tracks who contributed value when AI output happens. The OPEN token then sits inside that economic loop.
Fine. But all of that mostly explains how supply enters the system.
The harder part is demand.
It drives me crazy when people talk like putting AI assets on-chain automatically makes them liquid. No. That is not how markets work. Tokenization does not magically create buyers. Attribution does not magically create usage. A registry does not magically create relevance. You can have perfect ownership and still have dead inventory.
This is what I call the Crowded Shelf syndrome.
The shelf looks impressive. It has models, datasets, adapters, agents, maybe even reputation signals and attribution trails. But when a real user arrives, the question is brutally simple. Which one should I use? Which one is good enough? Which one is trusted? Which one fits my task? Which one has real demand behind it and which one is just technically available?
That decision layer is where OpenLedger’s real liquidity problem lives.
If OpenLedger becomes only good at creating AI assets, it risks building a beautiful warehouse. A huge one. Full of technically registered assets that barely earn because demand keeps flowing to the same small group of visible winners. That is not broad AI liquidity. That is concentration wearing a decentralization costume.
Look, Proof of Attribution matters. I am not dismissing it. If a model uses someone’s data, the contributor should not disappear into the black box. That is a real problem in AI. OpenLedger is right to attack it. But attribution answers what happens after usage. It does not answer how the right asset gets picked before usage.
And that “before” part is everything.
An app builder does not want to browse a museum of models. They want the right model for the job. An agent does not need ideology. It needs reliable routing. An enterprise user does not care that a thousand Datanets exist if it cannot identify which one is accurate, compliant, affordable, and alive. Even retail users will not tolerate confusion for long. They follow whatever feels easiest, fastest, and most trusted.
So the challenge for OpenLedger is not just to say, “We can monetize AI assets.”
The challenge is to prove that demand can move through those assets intelligently.
That means discovery has to become economic infrastructure, not a side feature. Ranking, reputation, usage history, attribution quality, cost, model performance, and agent reliability all start to matter. If those signals are weak, the network becomes noisy. If they are strong, OpenLedger can start turning passive AI inventory into active economic flow.
This is where I want the OpenLedger community to be more honest with itself. Stop celebrating only the number of assets created. Ask how many are being used repeatedly. Ask whether Datanets are getting real downstream demand. Ask whether ModelFactory outputs are becoming useful products or just more supply. Ask whether OPEN utility is tied to live movement across the network or mostly to the promise that movement will come later.
Because tokenization without discovery is a trap.
It gives people the feeling that value has been unlocked when value has only been labeled. It makes ownership visible before demand is proven. It can make contributors feel included while the actual earnings stay thin. That is the gap OpenLedger has to close.
The bullish version of OpenLedger is not “many AI assets on-chain.”
The bullish version is much harder. It is a network where a user’s need can find the right Datanet, where a builder’s model can find real usage, where agents route work through reliable intelligence, where Proof of Attribution pays contributors because actual inference demand keeps happening.
That is real liquidity.
Not the screenshot kind. Not the campaign metric kind. The kind where assets earn because the market keeps choosing them.
So yes, I am watching OpenLedger. But I am not watching only the asset count. I am watching the shelf. I am watching whether it becomes a marketplace or a graveyard.
Because in AI, the asset that matters is not the one that exists.
It is the one demand can find.
