For the past few years, the AI industry has mostly been obsessed with size.
Bigger models. Bigger funding rounds. Bigger clusters of GPUs running day and night in giant data centers somewhere most people will never see. Every major conversation seemed to circle back to compute power, as if the future of AI belonged only to whoever could afford the largest machines.
But beneath all of that noise, another question has been slowly becoming more important.
Where does the data come from?
Not in the vague sense. In the real sense. Who created it, who owns it, who benefits from it, and whether any of that can still be traced once a model has absorbed it.
That is the space OpenLedger is trying to step into.
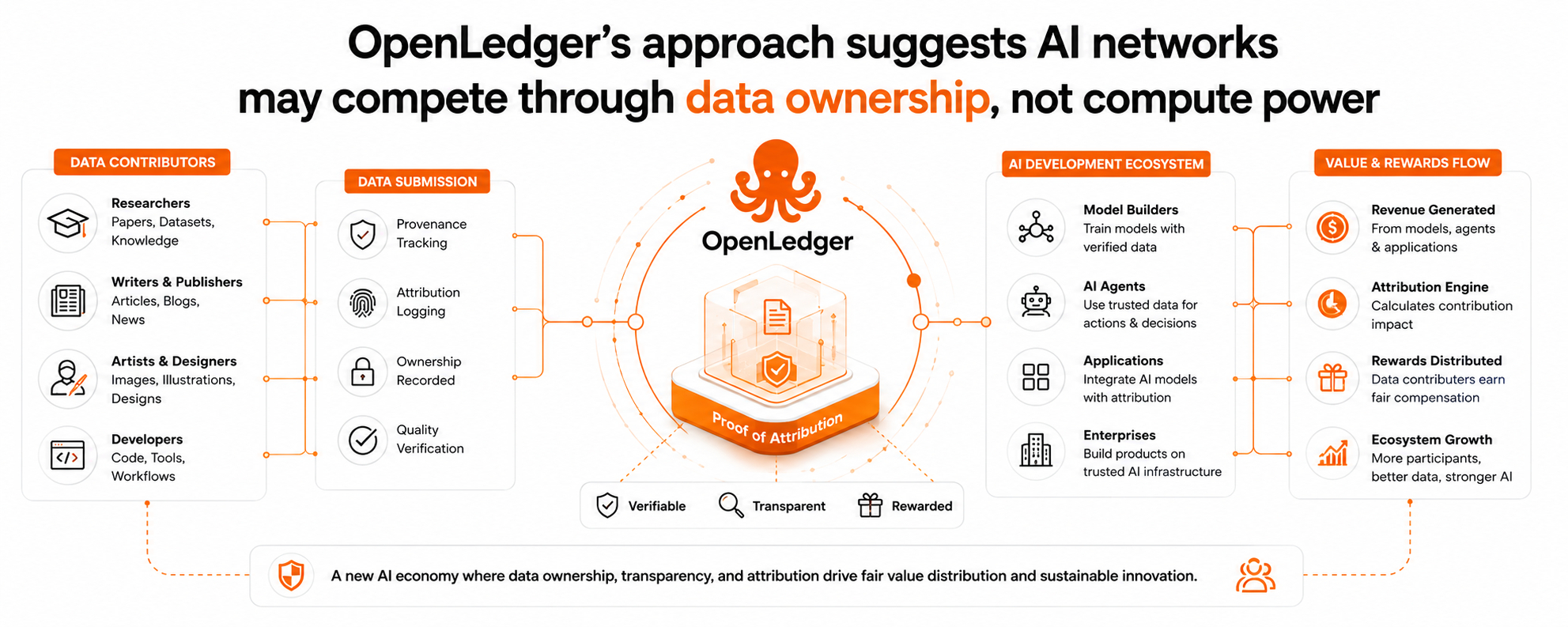
The project describes itself as an AI blockchain focused on monetizing data, models, and agents. On paper, that sounds like something that could easily disappear into crypto jargon. A lot of projects have tried to combine AI and blockchain by simply placing two popular words beside each other and hoping the market fills in the blanks.
OpenLedger feels slightly different because its central idea is actually straightforward.
It is built around the belief that data itself may become the most valuable layer of AI infrastructure.
Not just large amounts of data, but trusted data. Traceable data. Data that still carries a visible connection to the people who contributed it.
That distinction matters more than it used to.
For a long time, most AI systems were trained in ways that felt almost industrial. Massive datasets were gathered from across the internet, cleaned up, compressed, and fed into models at scale. Once training finished, the original sources became blurry. The model learned patterns, but the individuals behind those patterns usually disappeared from the equation entirely.
That approach worked when the industry was moving fast and regulation was still catching up. But now the conversation is changing.
Artists are questioning how their work is used. Publishers are challenging scraping practices. Governments are beginning to ask for more transparency around training data. Even companies building AI products are becoming more cautious because they know unclear data origins can create legal and reputational problems later.
The pressure is no longer theoretical.
And this is where OpenLedger’s approach becomes interesting.
Instead of treating data as something temporary that gets consumed during training, the network tries to treat it like an asset with history attached to it. The project talks about “DataNets,” which are essentially structured data networks designed to keep track of contribution and provenance over time.
In simple terms, the system is trying to answer a question the AI industry has mostly ignored:
If a model becomes valuable because of certain data, should the contributors of that data remain invisible forever?
OpenLedger’s answer is no.
The project’s technical framework revolves around something called Proof of Attribution. The idea is to create a verifiable connection between outputs and the datasets that influenced them. If that connection can be measured properly, contributors could theoretically be rewarded when their data helps generate value later on.
Whether that works perfectly at scale is still uncertain. Attribution inside machine learning is complicated. Models do not think in clean, traceable lines. A single response can reflect thousands of tiny influences blended together in ways that are difficult to isolate.
OpenLedger does not magically solve that complexity overnight.
But the important thing is that it is trying to build around the problem instead of pretending the problem does not exist.
That alone separates it from a large portion of the AI conversation right now.
Because if you strip away the hype surrounding artificial intelligence, the industry is quietly running into a trust issue.
People are becoming less comfortable with systems built on invisible foundations. They want to know where information came from. They want clearer ownership structures. They want transparency around what is being used, especially when money starts flowing through the system.
In that environment, data provenance stops being a technical detail and starts becoming part of the product itself.
And that may change how AI networks compete in the future.
For years, the assumption was that the strongest AI companies would simply be the ones with the deepest pockets and the largest compute infrastructure. There is still truth in that. Hardware matters. Compute will continue to matter.
But compute alone is becoming easier to access than it once was. Cloud infrastructure spreads. Open-source models improve. Optimization gets better. The gap narrows over time.
High-quality data, on the other hand, is harder to replicate.
Especially specialized data.
A model trained on carefully curated medical records, legal workflows, financial behavior, scientific research, or industry-specific expertise carries advantages that generic internet-scale scraping cannot easily reproduce. The more useful and domain-specific the data becomes, the more valuable ownership and provenance become alongside it.
That is the deeper argument underneath OpenLedger.
The project is essentially betting that the next major AI moat may not come purely from compute power. It may come from trusted data ecosystems where contribution, ownership, and attribution are built directly into the network itself.
That is a quieter thesis than most AI narratives today.
It does not rely on futuristic promises or dramatic claims about replacing existing systems overnight. If anything, the idea feels surprisingly practical. AI models need data. The people supplying valuable data increasingly want recognition, protection, or compensation. OpenLedger is trying to build infrastructure around that tension before it becomes impossible to ignore.
And honestly, the timing makes sense.
The AI industry is entering a phase where maturity matters more than spectacle. The early years were defined by acceleration. Everything moved fast because almost nobody wanted to slow down long enough to ask difficult questions.
Now those questions are arriving anyway.
Who owns the training data?
Who gets paid?
Who decides what is fair use?
Can AI systems remain open while still respecting contribution and attribution?
Those questions are no longer sitting at the edge of the conversation. They are slowly moving toward the center.
OpenLedger is not the only project exploring those issues, but it is one of the few building its identity around them so directly.
Whether it succeeds is still uncertain. Most ambitious infrastructure projects fail long before their ideas are fully tested. That is simply reality. But the broader shift it points toward feels real enough to pay attention to.
Because the next stage of AI may not belong only to the companies with the largest models.
It may belong to the networks that can build trust around the data those models depend on.
