
 A pattern I keep noticing in technology is that systems almost always get optimized for growth long before they get optimized for consequences.
A pattern I keep noticing in technology is that systems almost always get optimized for growth long before they get optimized for consequences.
The internet scaled before anyone seriously thought about misinformation. Social media optimized engagement before realizing attention itself could become socially corrosive. Cloud infrastructure normalized infinite retention because storage was cheap and nobody fully understood the long-term implications of permanent behavioral archives.
AI feels like it is entering the exact same phase now.
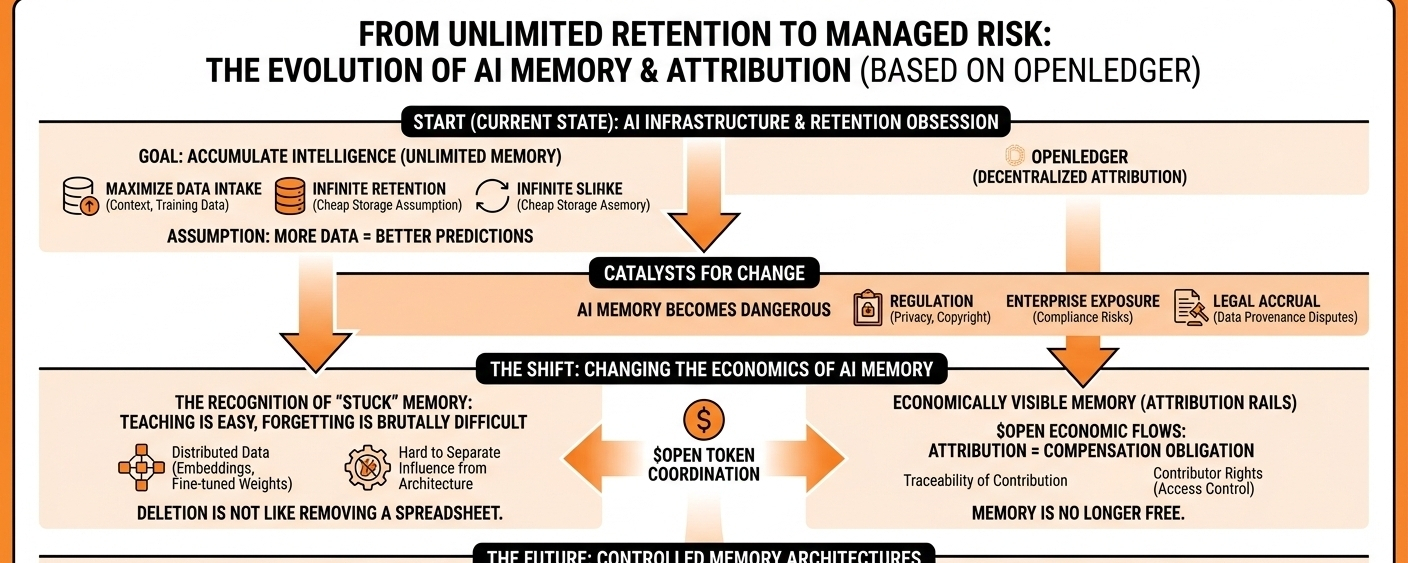
Everyone is obsessed with what models can absorb. More context. More training data. More memory layers. More personalization. The assumption underneath the entire industry is that intelligence improves through accumulation, so the rational strategy is to retain as much information as possible for as long as possible.
That logic works beautifully…
until memory itself becomes dangerous.
And honestly, that is partly why OpenLedger started feeling more interesting to me recently.
Most people still describe OpenLedger using familiar crypto language. Decentralized AI infrastructure. Attribution rails. Contributor incentives. Data coordination through $OPEN . None of that is wrong. But I increasingly think the market may be focusing on the comfortable part of the story while missing the more structurally important one.
Because once attribution becomes persistent, memory stops being passive.
It becomes accountable.
That changes the economics of AI systems completely.
Right now most AI companies still operate under a retention-first mindset. Keep everything because maybe it becomes useful later. Historical interactions improve personalization. Behavioral memory improves prediction. Long-context systems improve continuity. Intelligence scales through persistence.
But the problem is that retained intelligence does not remain neutral forever.
The moment AI systems start operating inside regulated industries, enterprise workflows, healthcare environments, financial systems, or autonomous operational layers, retained memory stops looking like pure upside.
It starts looking like exposure.
And the deeper I think about it, the more I suspect the next major AI infrastructure race may not revolve around who can accumulate the most intelligence…
but around who can manage the risk of retained intelligence most effectively.
That distinction matters.
A lot.
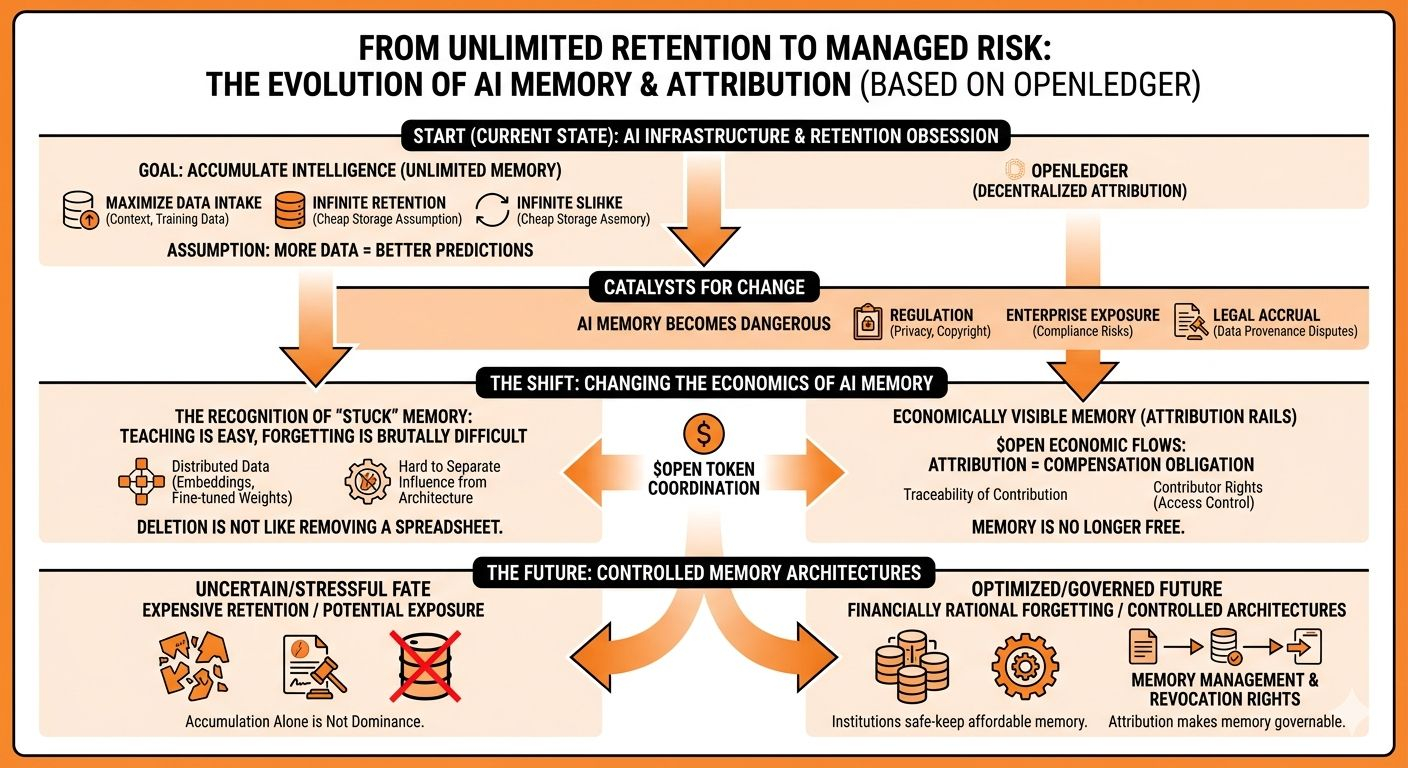
Because machine memory is fundamentally different from human memory. Humans forget naturally. AI systems don’t. Once information gets distributed across embeddings, fine-tuned behaviors, retrieval systems, model weights, and latent representations, separating influence from architecture becomes extremely difficult.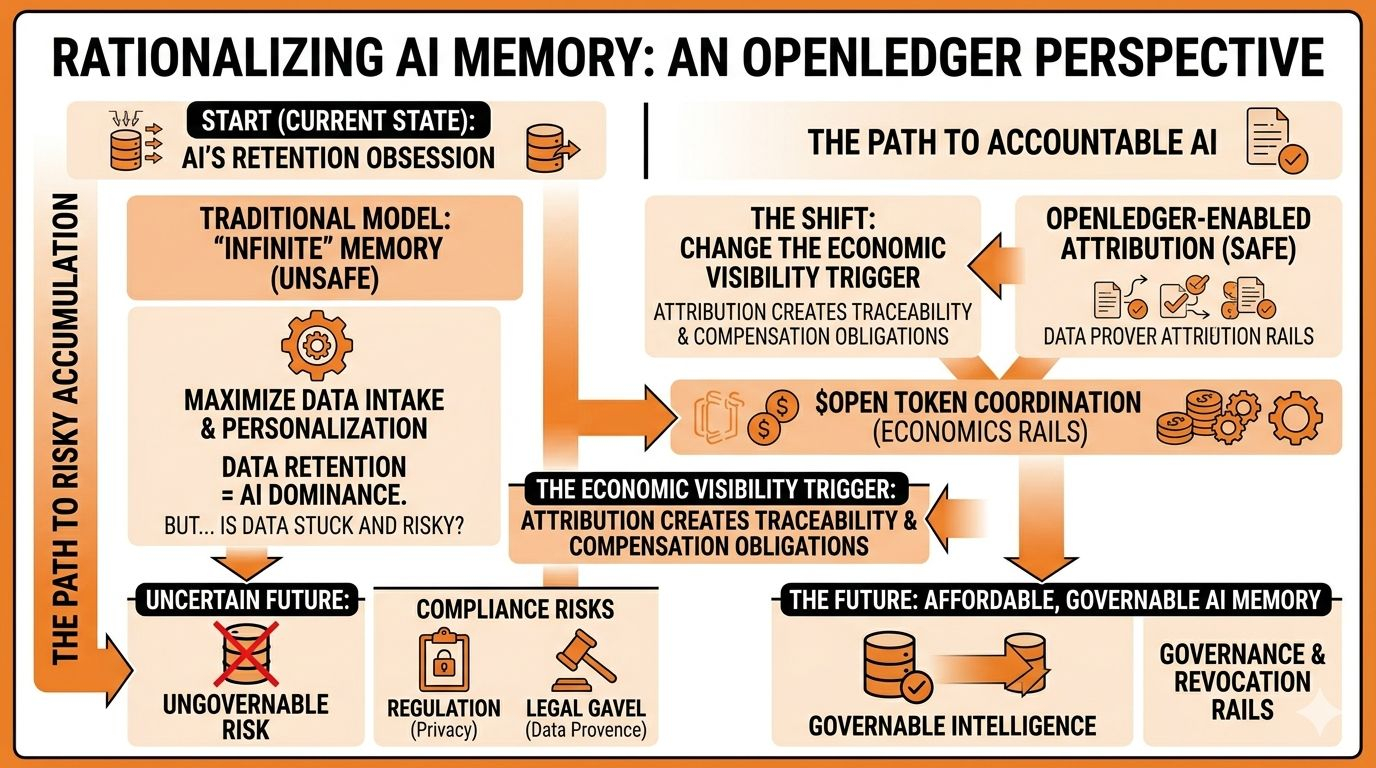
People still imagine deletion in AI the way they imagine deleting a spreadsheet.
That mental model is outdated already.
The uncomfortable reality is that teaching a system something is often dramatically easier than removing the operational consequences of what it learned later.
And once regulators, enterprises, and institutions fully internalize that reality, the economics around AI data retention may change very quickly.
That is where OpenLedger becomes much more than a contribution marketplace.
If attribution remains tied to intelligence flows through persistent economic coordination, then retained memory effectively carries ongoing cost. Provenance creates traceability. Traceability creates responsibility. Responsibility creates operational pressure.
Suddenly infinite retention stops looking efficient.
Because memory is no longer free.
It carries compensation obligations. Compliance implications. Governance disputes. Potential legal exposure. Economic accountability toward contributors whose data continues influencing active systems.
And once retaining intelligence becomes expensive enough…
forgetting becomes financially rational.
That possibility feels massively underpriced to me.
Especially because the current AI market still behaves like accumulation alone guarantees dominance. Bigger datasets. Longer memory. More historical context. More personalization layers.
Very few people are seriously asking whether future AI systems may eventually need controlled memory architectures instead of permanent memory architectures.
Crypto people, oddly enough, may understand this contradiction earlier than most industries.
Blockchains taught the market something uncomfortable years ago: permanence sounds elegant until permanence collides with privacy, regulation, or human error. Suddenly immutability stops feeling universally positive.
AI may be heading toward its own version of that realization now.
And OpenLedger appears to be sitting directly near that pressure point.
Not because it magically solves machine forgetting. It doesn’t. That challenge remains brutally difficult technically.
But because attribution systems transform memory into something economically visible.
And visible systems eventually become governable systems.
That creates entirely new tensions the AI market still barely discusses.
Who controls revocation rights?
Who decides whether historical intelligence remains operationally active?
Can contributors economically pressure operators by restricting future access?
Can enterprises justify indefinite retention once attribution becomes transparent?
What happens when sovereign regulation collides with decentralized governance around memory rights?
Those are not theoretical edge cases.
Those are future infrastructure conflicts.
And honestly, I think the market still underestimates how politically complicated AI memory becomes once autonomous systems start interacting with real-world economic activity at scale.
That is also why I keep coming back to the token layer around $OPEN.
The easy version of the thesis is simple: AI activity grows, attribution expands, network usage increases, token demand follows.
Maybe.
But infrastructure economics are rarely that clean. The harder question is whether attribution-based coordination becomes operationally necessary enough that participants tolerate the additional complexity. Because history shows markets routinely choose simpler systems over philosophically superior systems if the friction gap becomes too large.
That risk is real.
OpenLedger could absolutely end up being too early, too complex, or too idealistic for the direction enterprise AI evolves.
But I also think the market may be underestimating how quickly AI retention itself could become controversial once machine intelligence starts operating closer to legal, financial, and sovereign systems.
Because eventually the AI industry stops asking: “How much can models learn?”
And starts asking: “How much memory can institutions safely afford to keep?”
That is a very different infrastructure market.
And OpenLedger increasingly feels like one of the few projects already thinking several layers ahead of that transition.