Been going through openledger’s architecture lately, mostly digging into how they handle data attribution and how they plan to connect off-chain ai models with on-chain economic coordination. honestly, the technical diagrams leave me with as many questions as answers right now.
most people think openledger is just another ai + crypto token where you upload a dataset, the token goes up, and somehow we replace the centralized data brokers. but that oversimplified narrative hides the actual engineering problem, which is ridiculously hard: building a verifiable pipeline from raw data to model outputs without requiring everyone to just trust a central server.
there are a few components i'm trying to wrap my head around.
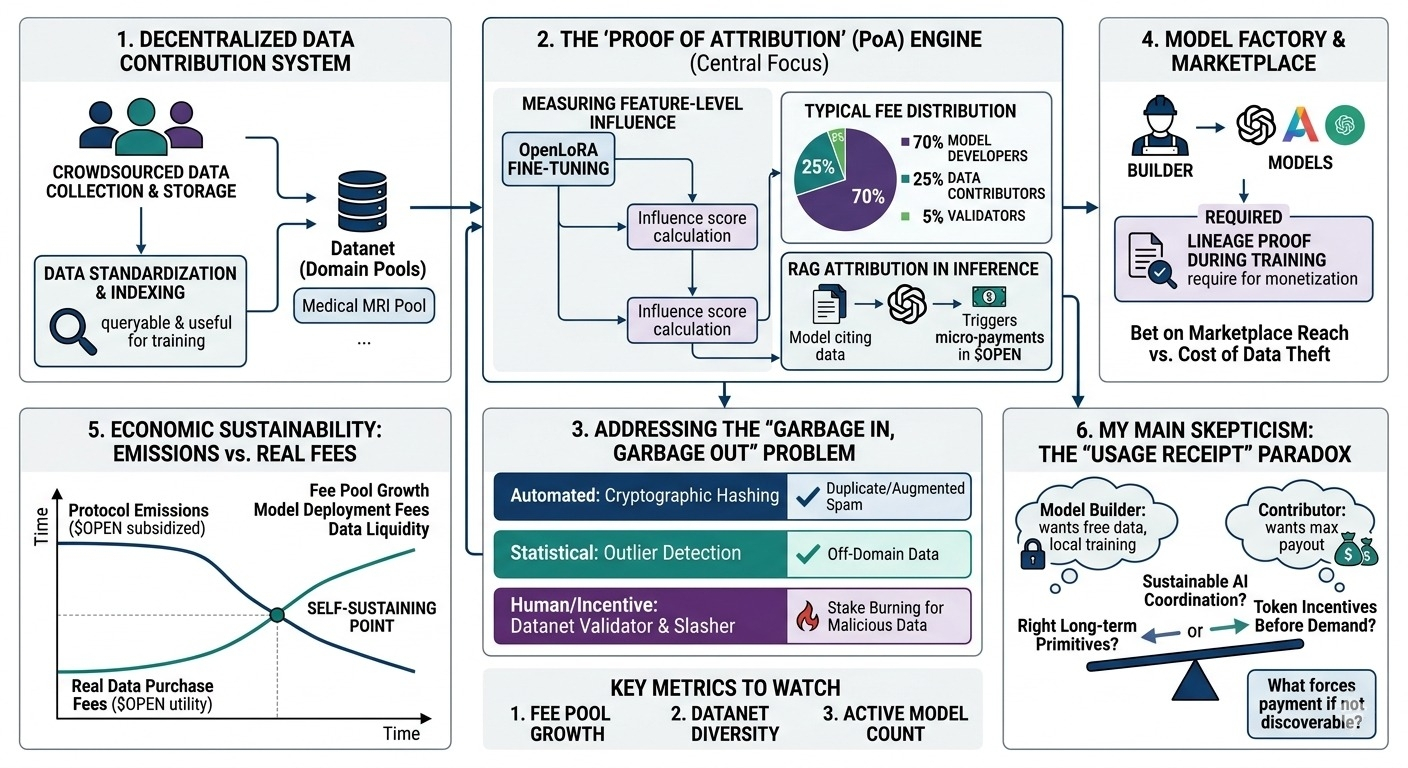
first, the decentralized data contribution system. they are building infrastructure for crowdsourced data collection and storage. what caught my attention is that they aren't just dumping raw files into decentralized storage; they are trying to standardize it so it's queryable and useful for training.
then there’s the attribution + reward mechanism. and this is the part i keep thinking about... how do you actually attribute value to a specific piece of data once a neural network has digested millions of them?
there's also the model/data marketplace dynamics, where builders need data and the protocol sits in the middle. and finally, the token incentives and verification layer. the chain handles the accounting, but verifying that a model actually used the data at scale requires some heavy cryptographic lifting or trusted hardware that i'm not sure is fully baked yet.
so, who actually creates value in this system? contributors provide the raw material, but value is only realized if an ai builder pays to train on it. the protocol assumes that builders will want to buy data piecemeal from a decentralized network rather than just licensing massive, pre-cleaned corpora from centralized platforms.
my main skepticism is around whether this attribution remains trustworthy. imagine a realistic example: a team is training a specialized medical diagnostic model. they need thousands of highly specific, annotated mri scans. openledger could theoretically coordinate this crowdsourcing. but if token incentives are attached to uploading, how do you prevent a flood of low-quality or slightly augmented spam data? you need curators or automated slashers, which introduces friction and centralized bottlenecks.
say a model builder pulls that mri dataset off the network, trains their model locally, and ships it. how does openledger actually enforce the usage receipt? if they rely on self-reporting, there's a massive incentive misalignment. builders want free data, contributors want max payout.
this leads into the classic token tension: emissions vs real utility. early on, protocol emissions will subsidize the rewards. contributors will get paid in tokens even if no one is buying the data. can these incentives remain sustainable over time once emissions dry up? if real demand doesn't materialize, the whole thing just collapses into a decentralized hard drive of unused datasets.
i don't have a perfect conclusion here. i want to believe a sustainable ai coordination layer is possible, but it’s hard to tell if openledger is building the right long-term primitives or just attaching token incentives to ai infrastructure before the real demand exists.
watching:
- the ratio of protocol emissions to actual data-purchase fees (when does the network actually become self-sustaining?)
- dataset rejection and dispute rates (this will signal how much spam is hitting the contribution layer)
- presence of repeat data buyers (not just one-off token-subsidized pilots)
if they solve the attribution problem without making the network insanely slow or expensive, it's genuinely interesting. but until then, what actually forces a model builder to play by the rules and pay up once they have the data?