

Eram la trei minute de citit o descompunere a fluxului de lucru când l-am observat.
Nu era ieșirea modelului. Nu rezultatul inferenței. O etichetă mică stând în colțul interfeței: "Datanet." Aproape că am derulat pe lângă ea. Aproape că am derulat pe lângă ea.
Asta e semnalul.
Toată lumea urmărește modelul. Ieșirile. Scorurile de referință. Viteza de inferență. Lucrurile astea sunt reale. Dar, structurale, ele sunt ultimul lucru care se întâmplă. Înainte ca orice să ruleze, ceva a trebuit să dețină datele. Ceva a trebuit să știe de unde au venit. Ceva a trebuit să demonstreze că nu au fost extrase la 2 dimineața de un bot fără responsabilitate atașată. Acel ceva este plictisitor. Are un nume plictisitor.
Se numește Datanet.
Un Datanet, în cadrul OpenLedger, este o rețea de date deținute de comunitate, cu proveniență verificabilă. O voi reformula în cuvinte mai proaste și mai plate: este un loc unde datele există, unde aceste date au chitanțe și unde oamenii care le-au contribuit păstrează o anumită revendicare asupra lor. Asta e tot. Nu există dramă în această propoziție și nu ar trebui să existe.
Dar aici este partea incomodă.
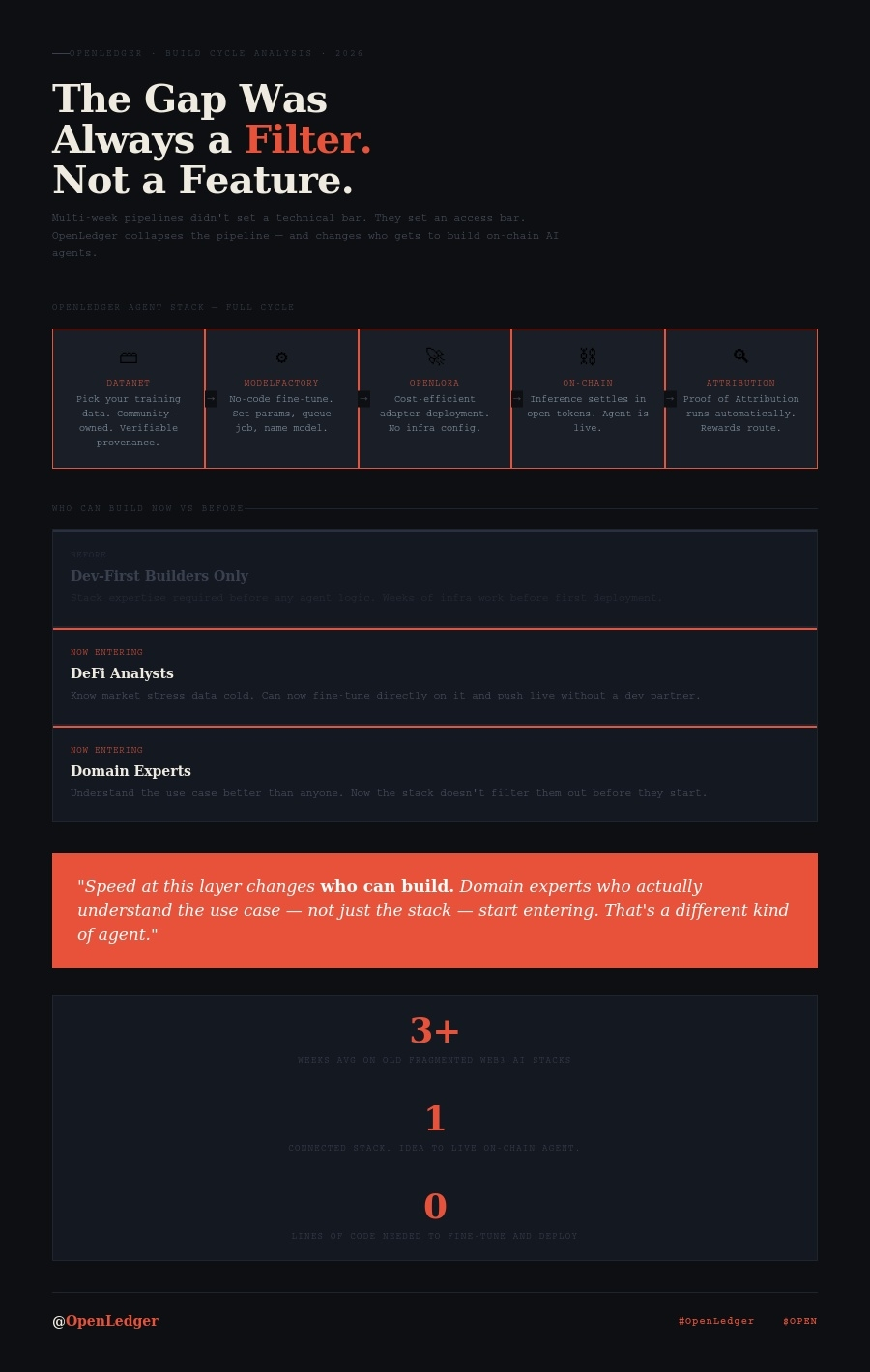
Dacă stratul de date este rupt, totul în aval este rupt. Nu încetinit. Nu degradat. Rupt. Modelul care te entuziasmează s-a antrenat pe ceva. Acest ceva a venit de undeva. Un Datanet este infrastructura care urmărește dacă "undeva" este real, atribuibil și guvernat de oameni reali, nu de agregări pe care nimeni nu le poate audita.
Cine a decis ce date intră într-un Datanet?
Cine guvernează adăugările după lansare?
Ce se întâmplă când doi contribuitori revendică aceeași sursă?
Ce înseamnă de fapt "proprietate comunitară" atunci când capitalul intră în peisaj și stimulentele se schimbă? Cum arată proveniența verificabilă la scară, nu într-o demonstrație controlată cu participanți cooperanți?
Nu am răspunsuri clare. Nu cred că spațiul are vreunul deocamdată.
Aici devine incomod pentru oricine investește capital în infrastructura AI. Nu pariezi doar pe un model. Pariul tău este pe stratul de date de sub model. Pari că proveniența este reală, că guvernarea este solidă, că Datanet-ul care stochează datele de antrenament nu se fragmentează atunci când stimulentele contribuitorilor deviază. Este o problemă de design al sistemului. Nu o problemă de produs. Nu o problemă de narațiune. O problemă de design al sistemului pe care nimeni din ciclul de acoperire nu o consideră suficient de interesantă pentru a o deschide.
Când stăteam în acea interfață de flux de lucru, uitându-mă la acel mic etichetă, mă întorceam la un singur lucru. Aici se creează sau se distruge încrederea. Nu la nivelul modelului. Nu la inferență. Aici. În această rețea de date plictisitoare, fără glam, guvernată de comunitate, pe care aproape fiecare piesă analitică o ocolește complet.
Acțiunea vizibilă și interesantă este inferența. Sunt ieșirile. Este lucrul pe care îl faci screenshot și îl distribui.
Stratul plictisitor este Datanet-ul. Acolo proveniența fie există, fie nu există. Acolo guvernarea comunității fie se menține, fie se prăbușește în tăcere. Acolo întreaga afirmație că AI este mai de încredere decât ceea ce a fost înainte se destramă dacă nimeni nu a construit fundația corect.
Aproape că am derulat pe lângă asta. Aproape.
Întrebarea cu care am început, cine deține de fapt stratul de date de sub infrastructura AI, este încă deschisă. Este mai grea acum decât era. Și nu sunt sigur că "deținut de comunitate" este un răspuns deocamdată. Ar putea fi încă doar o descriere onestă a problemei.

