and i’m still hunting for the real trust anchor
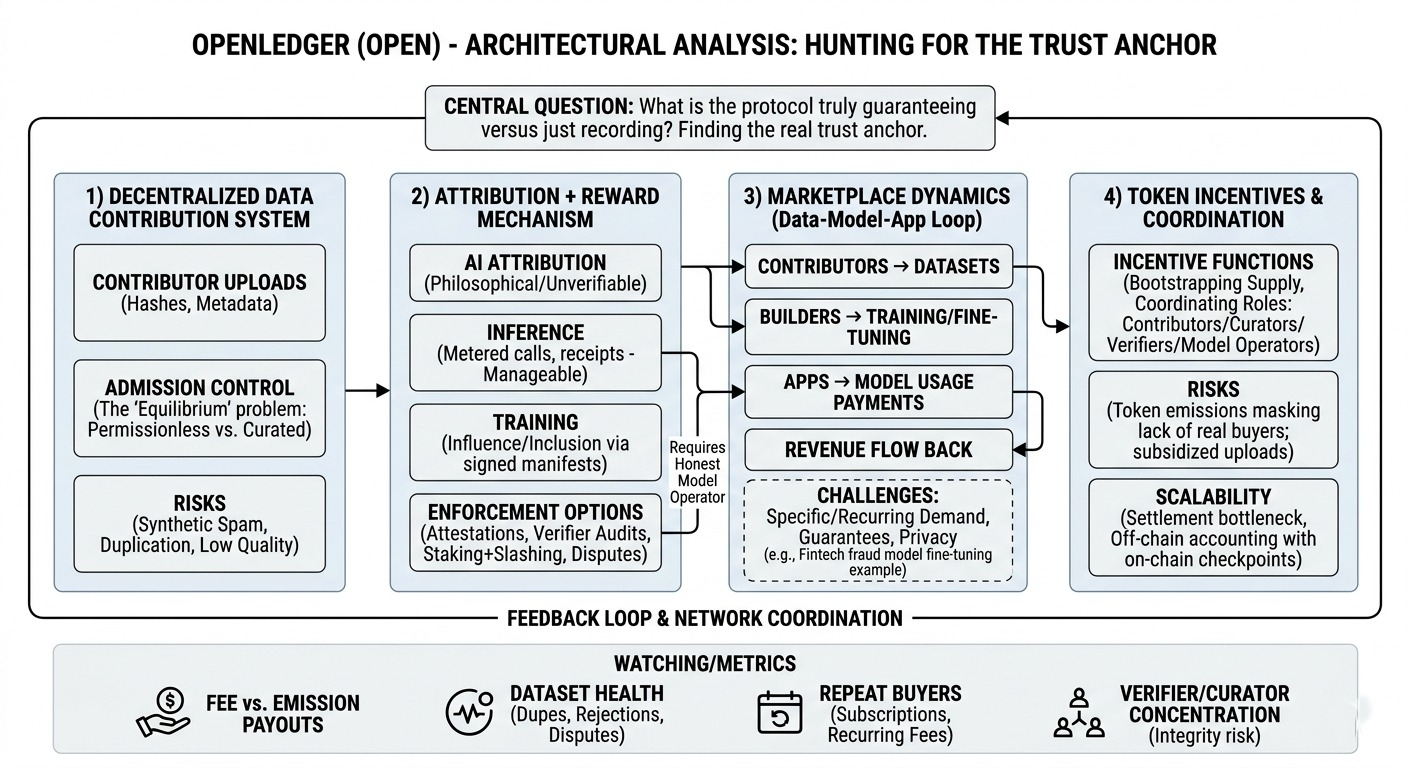
Been going through openledger’s architecture and i keep stopping at the same question: what exactly is the protocol guaranteeing, versus what is it just recording after the fact? what caught my attention is the focus on attribution as a first-class thing. not “here’s a storage network for datasets,” but “here’s a way to reference data, track how it flows into models, and settle payouts on-chain.” honestly, that’s the only reason to involve a blockchain here, but it’s also where all the sharp edges live.
most people think openledger is just another ai + crypto token with a contributor rewards program. upload data, earn open, end of story. but that narrative is too neat. in a system like this, the token is the easy part; the hard part is building a market where model builders pay repeatedly for data (or model outputs) because the provenance/quality signals are strong enough to beat private procurement.
a few components feel like they determine the long-term network shape:
1) decentralized data contribution system
the docs suggest a pipeline where contributors publish datasets as content-addressed artifacts (hashes), with metadata and versioning so builders can reference “dataset x at commit y.” that’s good distributed-systems hygiene. but the missing piece is admission control. if publishing is cheap, you’ll get duplicates, minor perturbations, and synthetic spam. if publishing is expensive (stake-to-publish, curated lists, reputation gates), then decentralization becomes more about auditability than pure permissionlessness. i don’t think either is “wrong,” but the protocol has to pick an equilibrium.
2) attribution + reward mechanism
and this is the part i keep thinking about… ai attribution is not naturally verifiable. for inference it’s manageable: meter calls, sign receipts, split fees. for training, attribution gets philosophical fast. you can do “included in training run” via signed manifests, or “influence” via heuristics, but both depend on the model operator emitting honest data. openledger can notarize manifests on-chain, sure, but notarization isn’t verification.
so i end up looking for the enforcement story: are they leaning on attestations from trusted hardware? a verifier network that audits logs? staking + slashing for provably false reporting? some dispute process where challengers can force disclosure of evidence? each approach has tradeoffs. stronger verification usually means more friction and higher costs, and builders are allergic to anything that slows iteration or leaks proprietary training details.
3) marketplace dynamics (data ↔ models ↔ apps)
there’s an implied loop: contributors supply datasets, builders consume them to train/fine-tune, then apps pay for model usage and revenue flows back. but it only works if demand is specific and recurring. centralized data vendors win today because they offer boring guarantees: quality control, licensing clarity, and someone to call when something is off. openledger has to approximate that with transparent provenance + incentives + reputation. i’m not sure the “default” buyer is a generalist model lab. it’s probably teams with narrow needs: updated domain eval sets, preference data, or time-sensitive vertical datasets.
realistic example: a fintech company fine-tunes a fraud model weekly using merchant-contributed chargeback narratives plus outcomes. that data is fresh, hard to scrape, and economically valuable. openledger could coordinate contributions and route payouts as the fine-tuned model is used. but then you immediately need (a) privacy constraints, (b) label validation, and (c) anti-sybil protections so one actor can’t upload 10,000 low-effort synthetic “chargeback stories” to farm rewards.
4) token incentives + network coordination / scalability
open’s incentives are doing two jobs: bootstrapping supply and coordinating roles (contributors/curators/verifiers/model operators). the risk is token emissions masking the absence of real buyers. you can get “growth” that’s just subsidized uploads. also, settlement has to scale: you can’t put every micro-usage event on-chain without turning the protocol into an accounting bottleneck, so batching/off-chain accounting with on-chain checkpoints seems inevitable. which is fine, but it reinforces that the verification layer (not the chain) is where integrity lives.
zooming out: who creates value? contributors create value only if their data is usable and differentiated. builders create value when they turn that into model performance and revenue. but builders also control the main surface for attribution manipulation. so the protocol is betting that honest reporting will be cheaper than cheating, either through enforcement or through market pressure (buyers prefer “verifiably sourced” models). i’m uncertain that market pressure exists at meaningful scale yet.
watching:
- fee-funded payouts vs emission-funded rewards (ratio, not just absolute volume)
- dataset health: duplication rates, rejection rates, dispute frequency
- repeat buyers: subscriptions to dataset updates / recurring model usage fees
- verifier/curator concentration: does integrity depend on a small set of actors?
no perfect conclusion. openledger might become a practical coordination layer for a few data niches, or it might just be paying people to produce datasets until real demand shows up. the question i’m left with: what’s the smallest verification scheme that keeps attribution honest without making integration so annoying that builders route around it?