
Toată lumea construiește același lucru acum.
Piețele de date AI. Rețele de contribuție. Infrastructură de antrenament. Narațiunea este identică: mai multe date → modele mai bune → evaluări mai mari. Poveste curată. Logică familiară. Plictisitor de-a dreptul.
Cred că @OpenLedger construiește din greșeală ceva mai ciudat.
Și piața nu a descoperit încă asta.
Problema despre care nimeni nu vorbește
Iată ce tot observ: companiile tech sunt obsedate de ce pot învăța sistemele AI, dar petrec aproape zero timp gândindu-se la ce ar trebui să-și amintească acele sisteme.
Această distincție nu a contat când AI a generat poezii sau răspunsuri de chatbot. Contează foarte mult când AI începe să influențeze deciziile de împrumut, fluxurile de conformitate, verificarea identității sau sistemele de consultanță financiară.
Pentru că, odată ce inteligența ia decizii reale, memoria nu mai este un activ pasiv. Devine o suprafață de responsabilitate.
Cei mai mulți oameni văd #OpenLedger ca infrastructură pentru contribuția de date AI. Contributorii oferă seturi de date. Constructorii le consumă. Modelele se îmbunătățesc. $OPEN coordonează stimulentele. Manualul standard de cripto.
Dar cred că adevărata poveste este invers.
Ce dacă următoarea constrângere a AI nu este învățarea - este uitarea?
Gândește-te cum funcționează de fapt AI-ul modern. Odată ce datele sunt absorbite în procesele de antrenament, embedding-uri, straturi de recuperare sau comportamente ajustate, eliminarea nu este ca ștergerea unui fișier. Informația se difuzează.
Dezvățarea mecanică este un întreg domeniu de cercetare care admite în liniște ceva incomod: a învăța mașinile este ușor. A le face să uite cu precizie este practic imposibil.
Asta era tolerabil când AI stătea în sandbox-uri. Nu mai este.
Regulatorii devin mai atenți. Întreprinderile devin mai prudente. AI se integrează în fluxuri de lucru ce implică plăți, identitate, comunicații interne, conformitate - suprafețe unde greșelile costă bani reali.
Și când sistemele ating operațiuni reale, întrebarea se schimbă de la "poate acest model să performeze?" la "ce anume poartă acest model mai departe?"
Întrebare diferită. Consecințe mai mari.
Jocul infrastructural ascuns pe care majoritatea oamenilor îl ratează.
Aici devine interesant OpenLedger:
Dacă atribuirea devine persistentă și economic semnificativă, atunci memoria păstrată nu mai este o infrastructură gratuită. Devine un obiect economic gestionat.
Aceasta răstoarnă complet structura stimulentelor.
În acest moment, sistemele AI rețin informații pentru că reținerea este utilă. Personalizare mai bună, continuitate mai bună, rezultate mai bune. Presupoziția de bază este simplă: menținerea contextului este întotdeauna benefică.
Dar într-o rețea unde contributorii pot fi identificați și fluxurile de valoare sunt legate de proveniență, memoria începe să implice costuri.
Și odată ce memoria implică costuri, uitarea devine rațională.
Imaginează-ți un asistent AI pentru întreprinderi antrenat pe interacțiuni proprietare cu clienții. Șase luni mai târziu, un client revocă permisiunile de date. Sau reglementările se schimbă. Sau firma decide că anumite interacțiuni istorice creează expunere legală.
Problema nu este doar ștergerea jurnalelor. Este deciderea dacă inteligența modelată de acele interacțiuni ar trebui să rămână activă operațional.
Sistemele de sănătate fac asta și mai urât. Sistemele financiare la fel.

De ce această narațiune contează acum
Explozia adoptării AI creează o criză de încredere despre care nimeni nu vrea să discute.
Instituțiile nu sunt alergice la AI. Sunt alergice la incertitudinea pe care nu o pot operaționaliza. Și memoria păstrată fără atribuție creează exact acea incertitudine.
Acesta este motivul pentru care cred că $OPEN s-ar putea să nu concureze acolo unde majoritatea oamenilor cred.
Nu calcul. Nu acces la model. Nu piețe de date.
Infrastructura pentru negocierea a ceea ce sistemele AI sunt permise să-și amintească, cât timp își amintesc și cine este recunoscut economic în timp ce acea memorie rămâne activă.
Aceasta este o teză mult mai puțin strălucitoare. Tocmai de aceea ar putea conta.
Cazul bullish
Dacă această teză se dovedește a fi corectă:
Fiecare implementare AI pentru întreprinderi are nevoie de infrastructură de atribuire.
Efectele de rețea se compun pe măsură ce mai multe sisteme se integrează.
Utilitatea token-ului crește dincolo de speculații în necesitate operațională.
OpenLedger devine "instalația plictisitoare" care captează o valoare masivă.
Narațiunile despre infrastructură îmbătrânesc bine. Întreabă investitorii timpurii în cloud.
Cazul bearish
Riscul de execuție este real. Attribuirea este tehnic greu de realizat. Uitarea mecanică este cu adevărat dificilă.
Economia token-urilor poate să se complice prea mult. Infrastructura privată câștigă adesea pentru că simplitatea operațională bate puritatea conceptuală.
Și există o întrebare de cerere: de ce există o presiune organică sustenabilă în loc de speculație temporară?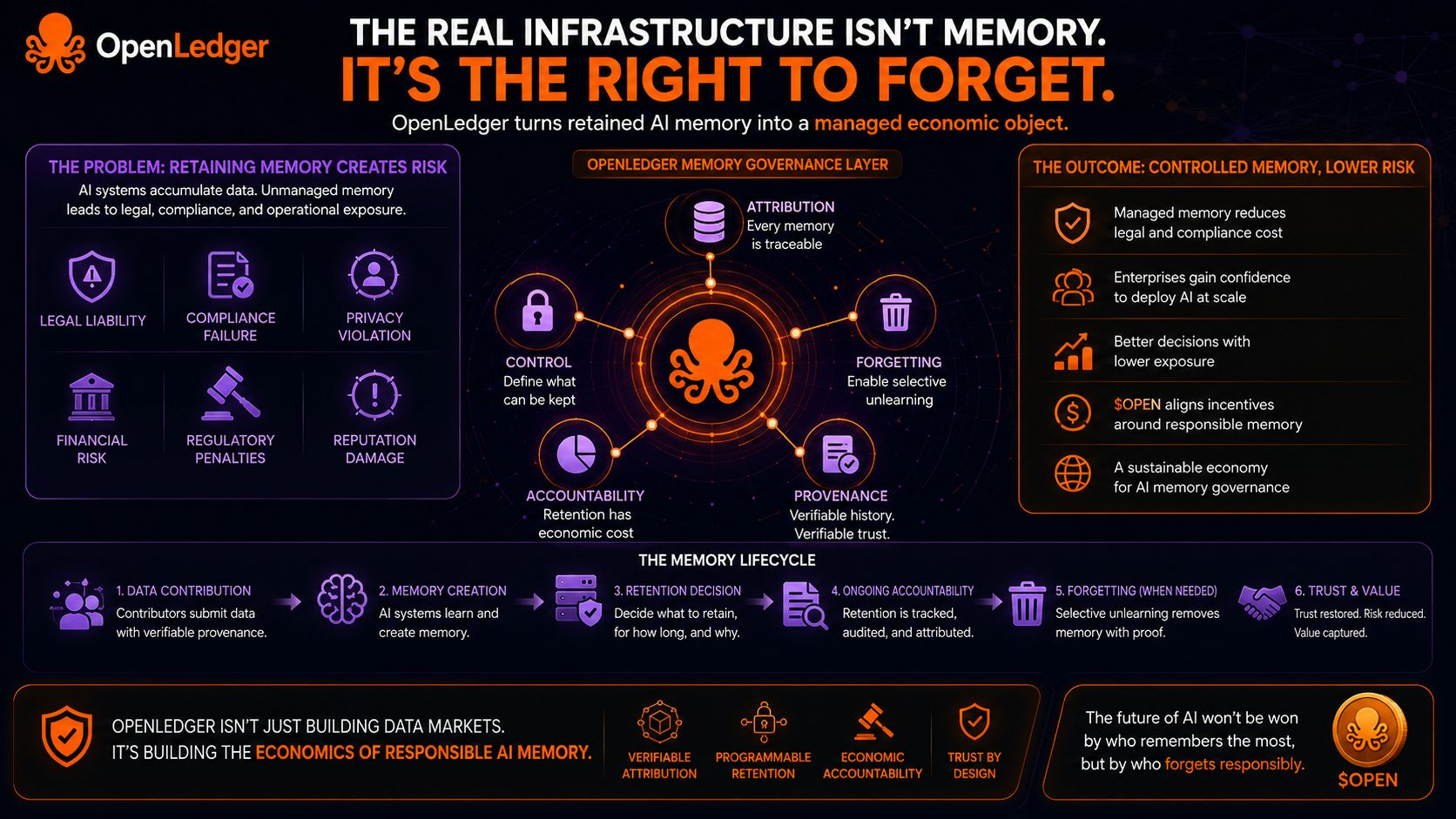
Concluzia contrariană
Piața AI încă se comportă ca și cum inteligența este activul rar.
Încep să cred tot mai mult că responsabilitatea ar putea deveni mai rară decât inteligența.
Dacă am dreptate, @OpenLedger nu doar tokenizează contribuțiile de date. Construiește infrastructura de guvernare a memoriei pentru sistemele AI care trebuie să uite corect.
Întreabă-te asta: în 12 luni, vor conta mai mult întreprinderile calitatea modelului sau responsabilitatea deciziilor?
Pentru că, dacă este ultima variantă, cu toții supraevaluăm ce infrastructură contează cu adevărat.
#OpenLedger #AIInfrastructure #CryptoAi #DecentralizedAI #DataEconomy