OpenLedger这个项目,我琢磨了得有两个月了。白皮书打印出来翻得边都卷了,还拿Excel老老实实算了一笔账。算完之后,我对着屏幕愣了半天。不是说这项目不行,而是那个成本数字,看得我肉疼。
先说我为什么关注它。去年底刷到他们融资的消息,当时就觉得PoA(归因证明)这个点挺有意思,你贡献的数据如果真的被模型用了,推理时候你就能分到钱。比那些光喊“数据主权”口号的项目实在多了。我甚至还拉着几个做算法的朋友讨论过,他们说技术上Infini-gram那套东西确实能跑通。
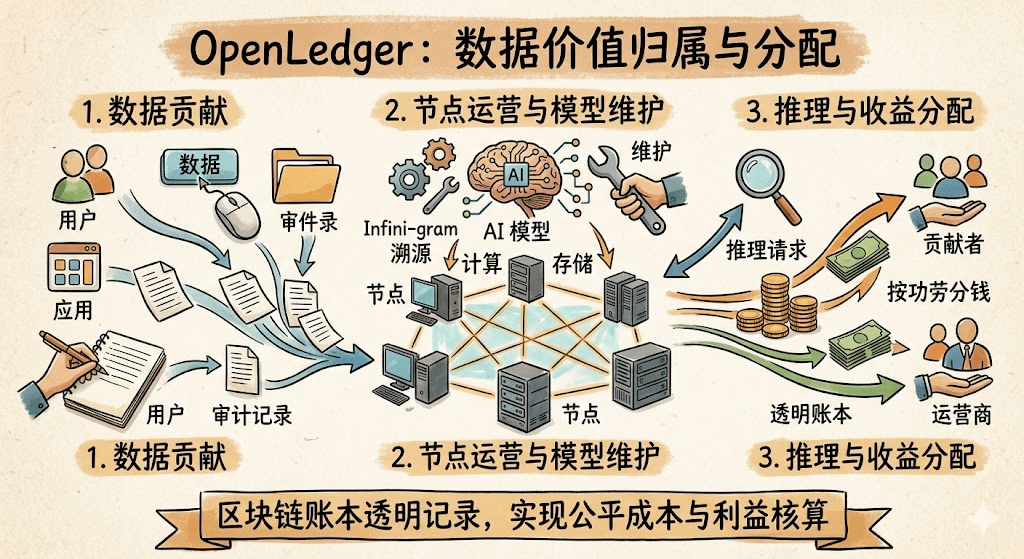
他们想干嘛,我理解是这样的
现在AI拿你数据训练模型,你连声谢谢都听不到,更别说分成了。@OpenLedger 想用区块链搭个透明账本,谁贡献了数据、谁跑了节点、谁维护了模型,推理时候按功劳分钱。思路不飘,挺落地,Infini-gram这种技术也能做到实时追溯来源。用户每次调用付的费用,扣掉运营成本,按权重分下去。理论上这套闭环是跑得通的,也是能审计的。
节点运营这事儿,算完账我真沉默了
白皮书里给的数据我看了,中等规模的Datanet,光存储成本在AWS上每月就是一笔硬支出。这还没算CPU、内存、带宽、运维。对象存储便宜点?行,但随机查询延迟能让你怀疑人生,体验直接崩了。关键是早期数据量小的时候,节点该交的固定成本一分不少,收入全靠推理调用量撑着。那问题来了,调用量没上来之前,谁来垫这笔钱?白皮书里对增量更新、索引维护这些日常运营成本的补贴,写得太模糊了。还有那个数据质量惩罚机制,方向是对的,但节点运营者的容错空间有多大?一个不小心被罚了,可能一个月白干。
结果就是大家都不太敢动
主网上线有一阵了,节点增长曲线挺平的。不是大家不感兴趣,是算完账之后心里没底。我也跟几个跑过测试网的朋友聊过,普遍态度是“再看看”,看看经济模型能不能再跑一段时间验证一下,看看官方会不会补一些激励细节。
我的真实看法
OpenLedger不是那种靠吹牛拉盘的项目,它是真想解决数据确权和利益分配这个真问题。这点我认可。但现实很骨感:节点准入门槛高、运营成本刚性、收入预期不确定。轻节点方案或者分片存储如果不上,散户基本没机会参与。光靠大户和机构跑节点,那还谈什么去中心化?所以我现在就是保持关注,不吹不黑。技术上他们确实在补行业短板,这事儿值得肯定。但能不能成,最终还是看成本结构和激励机制能不能跑通。技术和落地之间,差的往往不是代码,是算得过账的经济模型。(本文是平台任务,不构成任何投资建议。)