
Я відкрив studio.openledger.xyz і пішов одразу в розділ Datanets - не у головну вітрину проекту, а у робочий інструмент. Хотів зрозуміти одну річ. @OpenLedger каже, що повертає людям власність над даними, якими "годують" AI. Я хотів побачити, чи стоїть за цим продумана механіка чи тільки гарне формулювання.
Спочатку що таке Datanets простими словами. Це спільний набір даних за конкретною темою, який будує спільнота. Не загальний скрейп інтернету, а вузький домен - юридичні контракти, медичні фрагменти, приклади коду, кейси з кібербезпеки. Будь-хто може створити новий Datanet або додати дані в існуючий. Кожна контрибуція хешується і прив'язується до того, хто її зробив. Потім коли на цих даних тренують модель і модель дає відповідь - система через Proof of Attribution має визначити чий це внесок вплинув на цю відповідь і нарахувати винагороду.
Логіка чиста. Зараз AI-компанії беруть дані з форумів, з відкритого вебу, від волонтерів - і ніхто з цих людей не отримує нічого, коли модель на їхніх даних заробляє мільярди. Datanet пропонує інший устрій. Ти не просто завантажив файл, який зник у тренувальному прогоні. Ти став учасником ланцюга вартості - твої дані працюють і приносять тобі дохід щоразу, коли впливають на відповідь моделі.
Це звучить справедливо. І тут починаються мої питання.
Перше. Я шукав конкретні цифри - скільки реально заробили контрибутори Datanets за час від запуску мейннету у листопаді. Не знайшов. Документація описує механізм. Whitepaper описує математику. Але публічних даних про реальні виплати - скільки людина внесла даних і скільки $OPEN отримала назад - я не бачив. Без цих чисел уся економіка лишається теорією на папері. Гарною теорією. Але теорією.
Друге і це глибше. Сам механізм attribution для великих мовних моделей технічно обмежений. Whitepaper OpenLedger чесний у цьому - для LLM вони використовують метод під назвою suffix-array token attribution. Простими словами він перевіряє, чи збігається вихід моделі зі шматками тренувального тексту. Він добре ловить, коли модель дослівно запам'ятала фрагмент. Але він не доводить причинність. Якщо твій внесок вплинув на відповідь не дослівно, а опосередковано - через стиль, через структуру міркування, через загальну ідею - suffix-array цього не побачить. Тобто attribution працює точно там, де модель скопіювала, і приблизно або ніяк там, де модель навчилася. А навчання це і є головне, що роблять моделі.
Це не наклеп на проект. OpenLedger сам це пише у whitepaper - чесно, прямим текстом. Я просто звертаю на це увагу, бо рекламні матеріали кажуть payable AI і fair compensation, а технічна реальність складніша. Винагорода за дослівне запам'ятовування - це майже вирішене питання. Винагорода за справжній вплив на навчання - це відкрите дослідницьке питання всієї індустрії, і OpenLedger його не закрив, він тільки чесно його окреслив.
Третє питання просте. Datanet з одним контрибутором - це Datanet чи особистий блокнот? Цінність ідеї спільних даних залежить від того, скільки людей реально беруть участь. Концепція Data Club працює тільки коли в клубі є люди. Я не маю даних про те, наскільки населені реальні Datanets зараз - і це саме те, що визначає чи жива екосистема, чи це поки що тільки красива архітектура, яка чекає на своїх учасників.
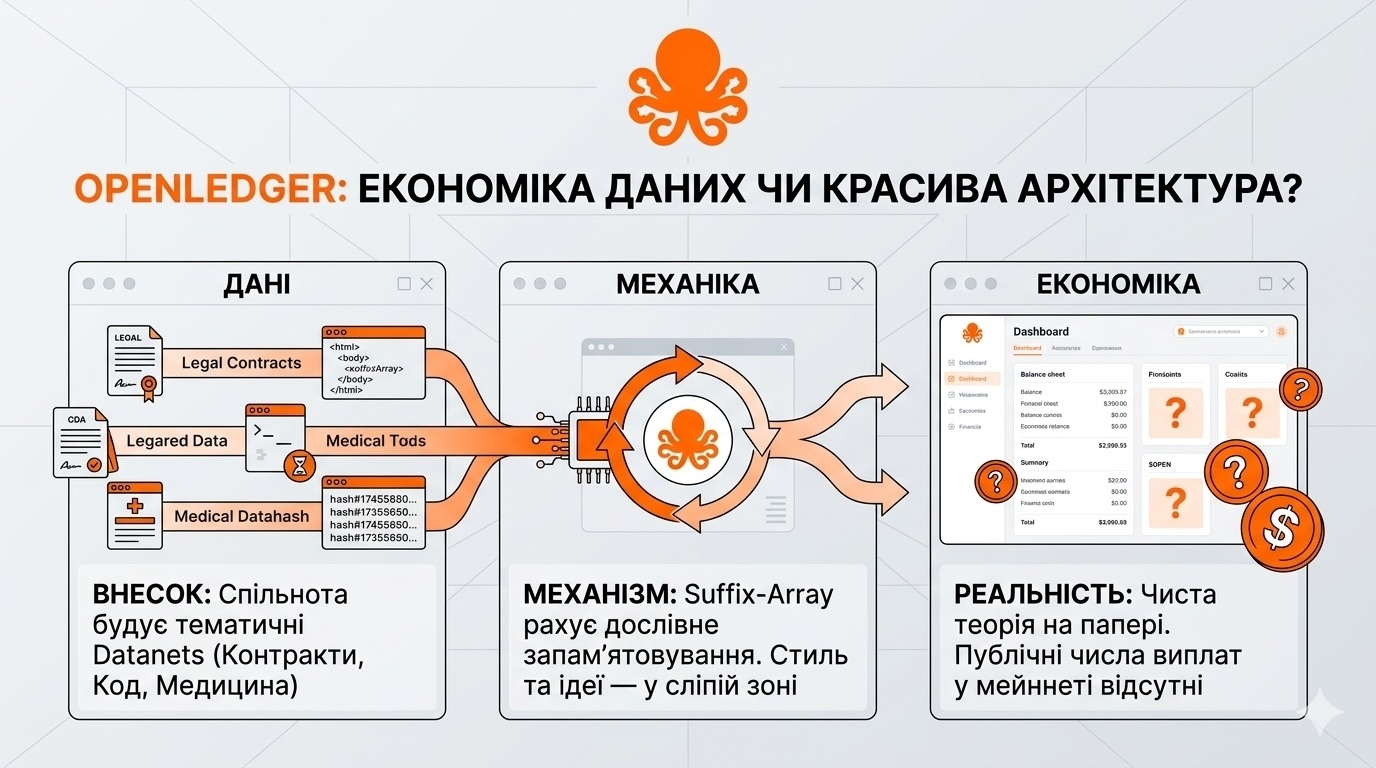
Я не пишу це, щоб знецінити Datanets. Ідея сильна і чесніша за те, як працює AI зараз. Я пишу це бо між вразою "Ми повертаємо людям власність над даними" і реально працюючою економікою, де контрибутори бачать дохід - лежить дистанція. OpenLedger зробив архітектуру. Чи наповнилася вона життям - покажуть числа, яких поки немає.
Якщо ти колись віддавав свої дані для тренування AI - будь то завантажував датасет, розмічав, чи просто погодився на use my data - чи отримував ти з цього хоч щось, крім обіцянок?
Цікаво почути реальний досвід, не теорію.
