stau cu update-ul motorului de atribuire din ianuarie 2026 de câteva săptămâni acum.
la prima vedere, pare a fi un progres simplu. openledger a actualizat sistemul său de dovadă a atribuirii pentru a menține legăturile de date intacte pe măsură ce modelele AI sunt ajustate și evoluează în timp. bun. asta e exact tipul de problemă de infrastructură care face sau desface un sistem de recompensare a contributorilor.
dar cu cât mă gândeam mai mult la mecanica din spatele acelui update, cu atât mă simțeam mai incomod.
iată ce vreau să spun.
dovada atribuirii funcționează prin urmărirea datelor de antrenament care au influențat care ieșire a modelului. datele contributorului A au modelat modelul într-o direcție măsurabilă, apare inferența, atribuirea este calculată, fluxul de recompense revine. ciclul are sens atunci când modelul este static, antrenat o dată, implementat, utilizat.
problema este că modelele AI nu rămân statice. ele sunt ajustate. actualizate. îmbunătățite. date noi se suprapun peste date vechi. fiecare ciclu de ajustare schimbă comportamentul modelului treptat de la ceea ce datele de antrenament originale au produs.
deci, ce se întâmplă cu scorul de atribuire al contributorului A după ce modelul a fost ajustat de trei ori de contributorii B, C și D?
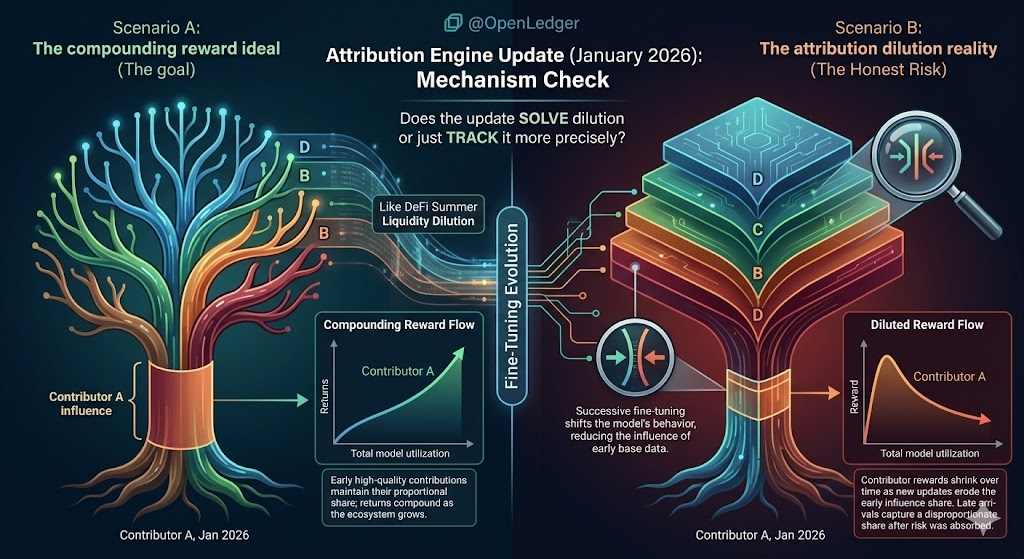
actualizarea motorului de atribuire spune că linkurile sunt "menținute", dar menținute cum, exact. dacă modelul a derivat cu 40% de la distribuția sa originală de antrenament prin cicluri succesive de ajustare, contributorul A mai primește credit pentru 100% din influența sa originală? sau partea sa de atribuire este diluată de fiecare îmbunătățire ulterioară?
nu am găsit un răspuns clar public la acea întrebare nicăieri în documentație. și contează mai mult decât pare. 🔍
gândește-te cum arată stimulentul pentru contributori dacă diluarea atribuției este reală.
contribui cu date de domeniu de înaltă calitate devreme. scorul tău de atribuire este puternic inițial. apoi dezvoltatorii încep să ajusteze modelul. fiecare îmbunătățire schimbă ușor distribuția rezultatelor. influența contribuției tale originale asupra rezultatelor curente scade cu fiecare actualizare. fluxul tău de recompense se micșorează în liniște în timp, nu pentru că datele tale s-au înrăutățit, ci pentru că modelul s-a îmbunătățit în jurul lor.
asta este opusul a ceea ce structura recompensei ar trebui să facă. ar trebui să creeze randamente compuse pentru contributorii de înaltă calitate timpurii. dacă ajustarea dilutează atribuirea în schimb, creează un sistem în care a fi devreme este de fapt un dezavantaj; ai contribuit înainte ca modelul să fie suficient de valoros pentru a genera cerere de inferență semnificativă, iar până când cererea de inferență apare, partea ta de atribuire a fost erodată de toți cei care au îmbunătățit modelul după tine.
am urmărit ceva similar să se desfășoare în furnizarea de lichiditate în timpul verii DeFi.
LP-urile timpurii au furnizat lichiditate înainte ca pool-urile să aibă volum. au luat cel mai mare risc. au obținut cea mai proastă execuție. apoi, când a sosit volumul și taxele au început să curgă, LP-urile ulterioare au intrat la prețuri mai bune, au avut un risc mai mic de pierdere impermanentă și au capturat o parte disproporționată din venitul din taxe. a fi devreme nu a fost recompensat. a fost diluat de persoanele care au sosit după ce riscul a fost deja absorbit.
problema diluării atribuirii de la openledger are aceeași formă dacă citirea mecanicii mele este corectă.
actualizarea din ianuarie a abordat urmărirea evoluției modelului, ceea ce înseamnă că echipa a identificat clar aceasta ca o preocupare reală demnă de inginerie. acesta este de fapt un semnal pe care îl găsesc cu adevărat încurajator. nu construiești infrastructură pentru o problemă pe care nu crezi că există.
dar descrierea actualizării este suficient de vagă încât nu pot spune dacă a rezolvat problema diluării sau doar a urmărit-o mai precis. aceștia sunt rezultate foarte diferite. unul înseamnă că contributorii timpurii sunt protejați. celălalt înseamnă că sistemul are acum o vizibilitate mai bună asupra cât de mult sunt diluați.
ceea ce nu sunt pe deplin convinsă este care dintre ele a fost de fapt livrată.
riscul onest aici este specific. dacă diluarea atribuției este reală și compusă, openledger se va confrunta în cele din urmă cu o problemă de retenție a contributorilor care nu seamănă deloc cu o problemă de achiziție a contributorilor. datanets se vor umple. volumul de contribuții va părea sănătos. și sub acea suprafață, cei mai timpurii și de cea mai înaltă calitate contributori, cei ale căror date au modelat efectiv capacitățile fundamentale ale modelului, vor câștiga în liniște din ce în ce mai puțin pentru munca care a contat cel mai mult.
asta nu este o eșec catastrofal. este o structură lentă. genul care nu apare în metricile on-chain până când contributorii care o observă deja au încetat liniștit.
ce aș vrea să văd de la openledger și nu am văzut încă este o descompunere transparentă a modului în care evoluează acțiunile de atribuire pe parcursul istoricului de ajustare al modelului. nu o descriere în whitepaper a mecanismului. date on-chain reale dintr-un datanet live care să arate ce s-a întâmplat cu recompensele contributorilor timpurii după ce modelul a fost actualizat. acea divulgare specifică mi-ar spune dacă actualizarea motorului de atribuire din ianuarie a rezolvat problema sau doar a numit-o mai precis.
până când acele date nu există public, urmăresc activitatea de ajustare pe datanets active mai atent decât orice altceva despre acest protocol.