The Liquidity of Things That Aren't Liquid
I've been sitting with this one longer than I expected.
AI and blockchain. I know. I know how that sounds. I've made the face too — that particular expression that forms involuntarily when you've watched enough projects glue two trending words together and call it infrastructure. It's not even skepticism anymore. It's something closer to muscle memory. And for a while, that reflex kept me from looking at OpenLedger with any real attention.
Then I kept bumping into the same question from a different angle. Not about the project specifically. About the problem underneath it. Who actually owns the data that trains the models that are quietly becoming load-bearing walls inside everything? And more uncomfortably — does "own" even mean anything useful if you can't do anything with it?
That's where I started paying closer attention. Not because the pitch got better. Because the question got harder to ignore.
The thing about data monetization is that it's one of those ideas that sounds obvious until you try to actually do it. Of course people should be compensated for the data that makes models smarter. Of course there should be some kind of provenance trail. Of course the contributors shouldn't be invisible. These feel like statements so reasonable that agreeing with them costs nothing.
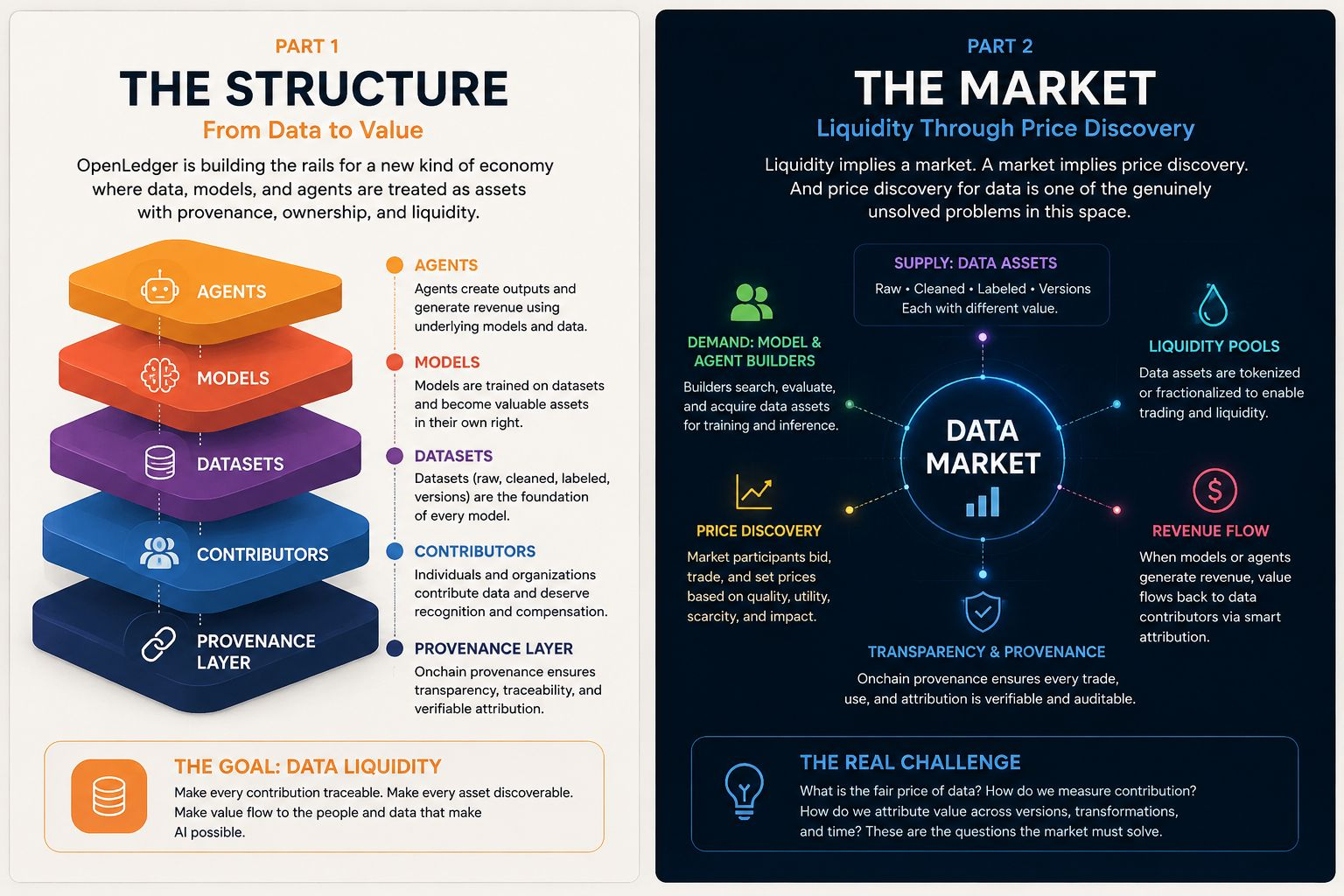
But the implementation is where things get strange. What does it mean to "monetize" a dataset? Is it the raw data? The cleaned version? The labeled version? The dataset as it existed at training time versus now? If a model was trained on something three versions ago, and the model is now generating revenue, what fraction of that revenue traces back to any specific contributor, and who does the math?
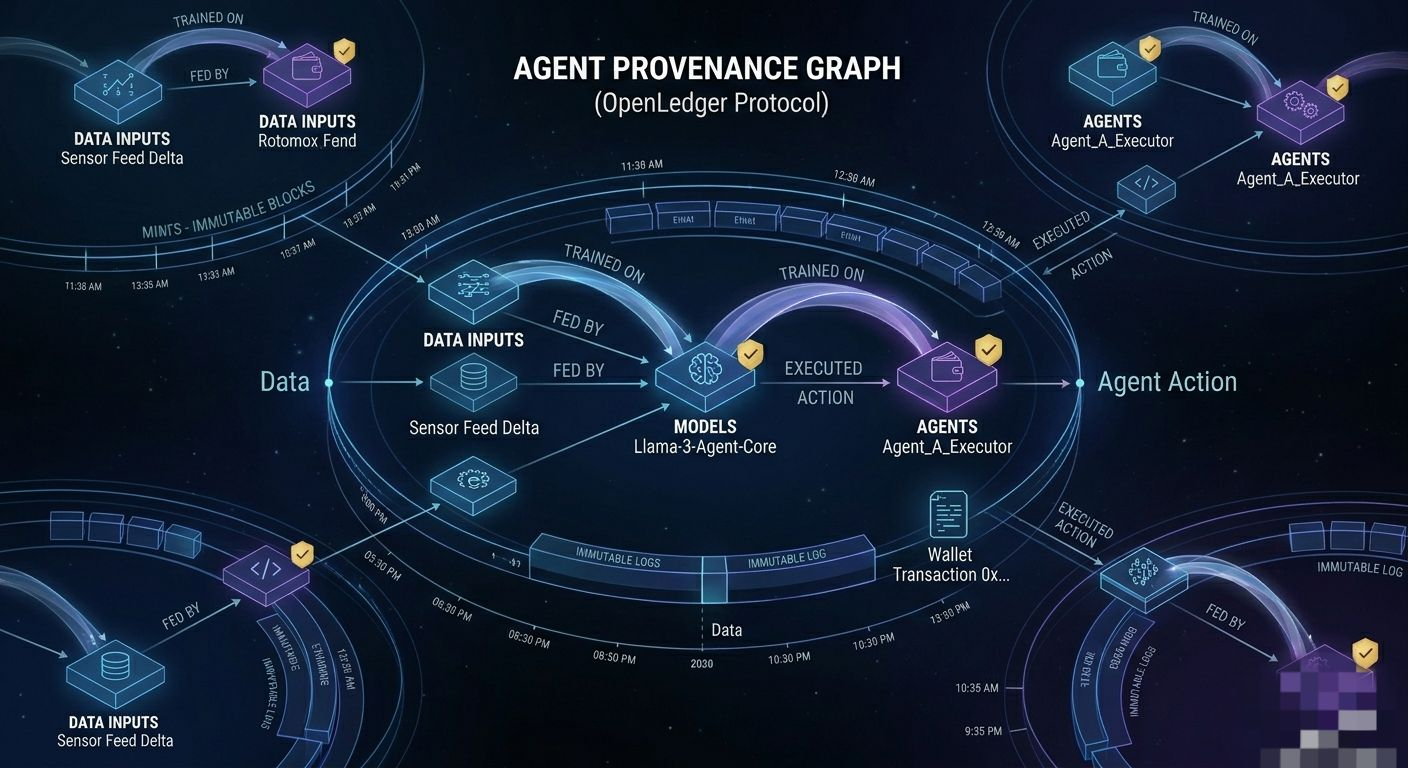
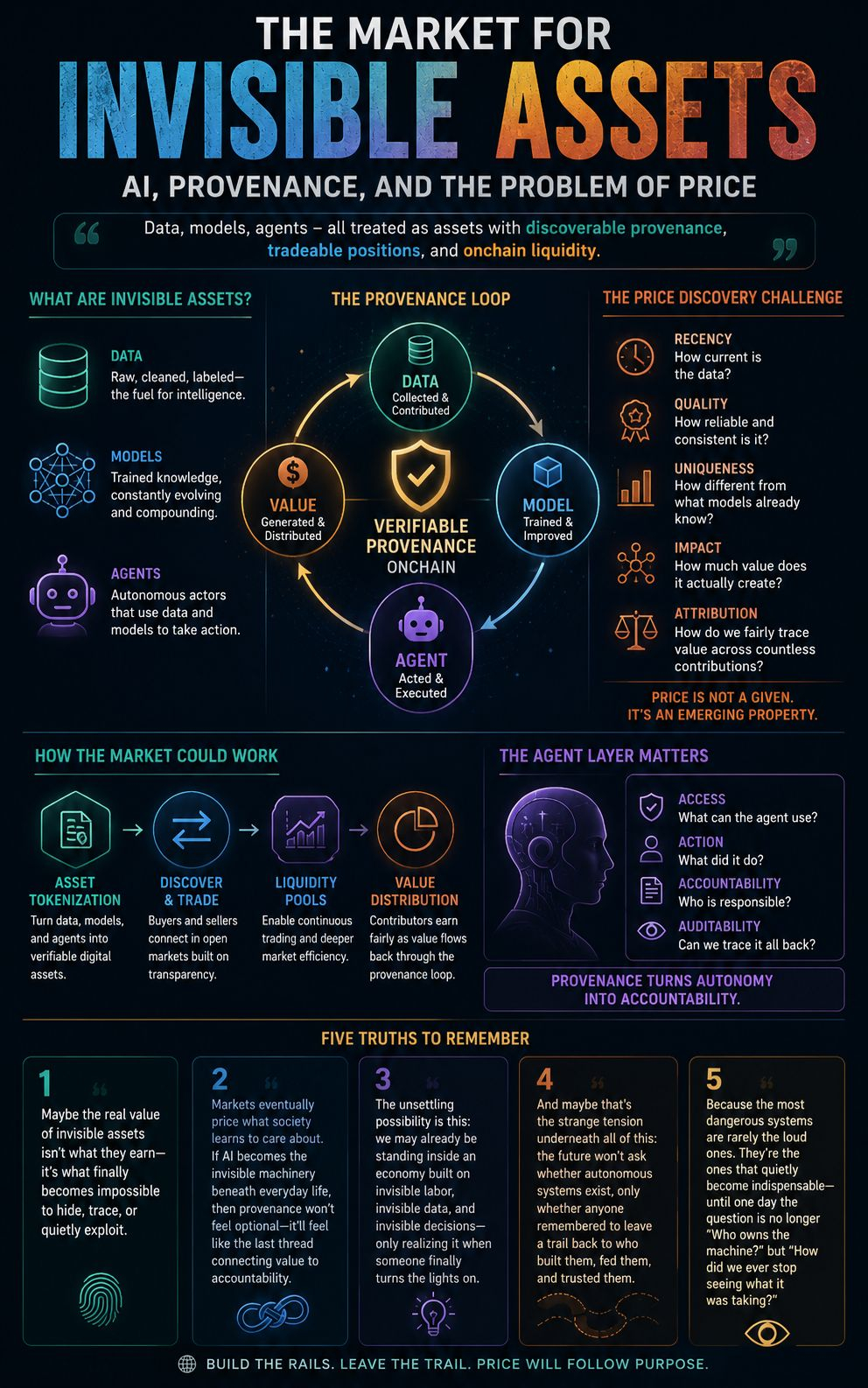
OpenLedger is trying to answer that. Or at least trying to build the rails on which that answer could eventually run. Data, models, agents — all of it treated as assets with discoverable provenance, tradeable positions, some form of onchain liquidity. That's the frame. And it's a more serious frame than it sounds.
But I keep coming back to the word liquidity. Because liquidity implies a market. And a market implies price discovery. And price discovery for data is one of the genuinely unsolved problems in this whole space.
That's where things start to feel uncomfortable.
Not because the idea is wrong. Because it's right in a way that might be ahead of the infrastructure needed to support it. Data doesn't behave like a fungible asset. Two datasets covering the same domain can have wildly different values depending on recency, quality, labeling consistency, what models have already seen similar data, and half a dozen other variables that are hard to encode cleanly into a price. You can tokenize the claim of ownership. Tokenizing the actual utility is a different problem.
And models are even messier. What's the liquidity of a fine-tuned model that was useful six months ago but has since been surpassed by something trained on more data? What's the floor? What sets the ceiling? These aren't rhetorical questions. They're the actual questions a functioning market would have to answer continuously, in real time, under conditions where the underlying technology is shifting faster than most pricing mechanisms can track.
Maybe that's too harsh. Maybe the point isn't to solve price discovery immediately. Maybe the point is to establish the coordination layer first — the identity of assets, the traceability of contributions, the basic infrastructure of who-made-what — and let the market figure out value once the rails exist.
I find that argument genuinely persuasive, actually. And then I immediately distrust my own persuasion, because that's also the argument that gets made for every infrastructure play that never quite finds its terminal use case.

The agent layer is the part I think about most. And the part most people probably gloss over in the headline.
Agents are becoming real in a way that feels different from previous AI hype cycles. Not because they're smarter. Because they're being given access to things — APIs, wallets, execution environments, other agents. The question of what an agent owns, what it owes, what trail it leaves, and who is accountable for what it does is not a philosophical question anymore. It's an engineering question with legal and financial consequences.
If OpenLedger actually becomes a place where agent provenance is trackable — where you can see what data fed what model fed what agent and what that agent did with that access — that's not a small thing. That's closer to an audit layer for autonomous systems. And an audit layer for autonomous systems is the kind of boring, critical infrastructure that nobody talks about until something goes wrong and suddenly everyone needs it yesterday.
I don't know if that's where this is going. I'm not sure the team knows either, or if knowing matters at this stage.