
Most of us are still obsessed with the wrong question: which model is smarter, faster, or has more funding behind it? We scroll through benchmarks, argue about reasoning scores, and cheer every new funding round like it’s the endgame. But here’s what I’ve come to realize after watching this space for a while — the real war in AI won’t be won by models alone. It will be decided by who owns the data, who verifies it, and most importantly, who actually gets paid for it.
Think about it. Every day people feed these systems their knowledge their corrections their domain expertise, their real-world feedback. The models remember everything. The economy? It forgets the people almost instantly. Once a company trains its model, the contributors largely disappear from the equation. The system absorbs the value and moves on. That imbalance has been staring us in the face for years, and it feels fundamentally broken — kind of like those early Play-to-Earn games that promised players real ownership and rewards but ended up stacking all the value at the top.
 This is exactly why OpenLedger caught my attention in a way most AI-crypto projects haven’t. They’re not just chasing another hype narrative around bigger models. They’re trying to build a system where data becomes traceable labor and contributors actually stack real economic value over time.
This is exactly why OpenLedger caught my attention in a way most AI-crypto projects haven’t. They’re not just chasing another hype narrative around bigger models. They’re trying to build a system where data becomes traceable labor and contributors actually stack real economic value over time.
Their “Payable AI” idea sounds simple on the surface but is pretty profound: contributors submit high-quality datasets into domain-specific Datanets, developers use that data to train specialized models, and smart contracts automatically distribute $OPEN rewards based on real contribution. No more invisible extraction. The data has provenance, the influence can be measured, and the economics flow back to the people who created the value.
What makes this stand out to me is the Proof of Attribution engine they’ve been rolling out. The gradient-based part for smaller models makes sense — if removing one datapoint clearly hurts performance, that data had measurable value. But the more ambitious piece is their suffix-array token attribution for larger language models. Tracing exactly which parts of the training corpus influenced specific output tokens has always been insanely difficult. Outputs feel collective and blurry. Trying to make that transparent is a genuinely hard technical problem, and they’re not pretending it’s perfect — but they’re at least trying to build accountability instead of just optimizing for extraction.
The legal side is another piece that feels ahead of the curve. Their partnership with Story Protocol is smart because as AI moves deeper into commercial use — especially in medicine, finance, law, or any regulated field — enterprises won’t just ask “how good is this model?” They’ll want to know: Is this dataset verified? Licensed? Legally clean? Defensible? Having on-chain attribution plus proper IP licensing could become a massive competitive advantage.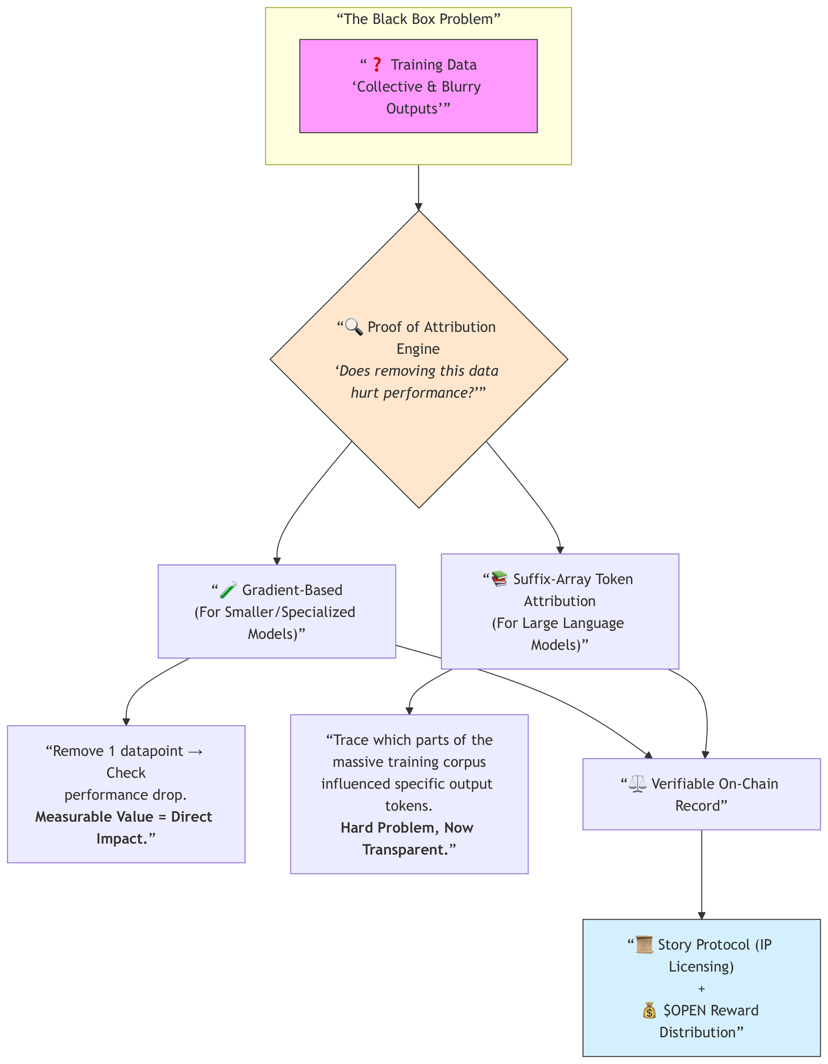
And the numbers from their testnet phase actually give this some weight: over 6 million registered nodes, 25 million+ transactions, and 20,000 AI models built before mainnet even went live late last year. That’s not just paper hype — it shows real participation and scale testing. Now that mainnet is operational with 40+ projects already building on it, the real test begins.
Because let’s be honest — where real money flows, bad behavior follows. We’re going to see leaderboard gaming, low-quality synthetic data spam, attribution disputes, and people trying to optimize for rewards instead of quality. The validation layer and long-term incentive alignment will decide whether this actually works at scale or becomes another interesting experiment.
Still, I respect that OpenLedger is tackling the uncomfortable question most of the industry has been avoiding: If ordinary people help create the value in these AI systems… will the system remember them?
That feels like the right question to be asking in 2026. The model wars will continue, but the projects that figure out fair, transparent data ownership and attribution might end up with the most durable advantage — both technically and economically.
What do you think — is data ownership going to be the real moat in AI, or are we still years away from systems that actually reward contributors fairly? I’m genuinely curious where this lands long-term.
