
OpenLedger is trying to do something that does not sound exciting at first.
That may actually be the reason I keep coming back to it.
I have watched too many crypto AI projects dress up the same recycled idea and call it a fresh cycle. Agents. Compute. Automation. A token glued to a dashboard. A whitepaper filled with words that look expensive but say very little. The market eats it for a week, maybe two, then moves on to the next shiny thing.
So when I look at OpenLedger, I am not looking for noise.
I am looking for friction.
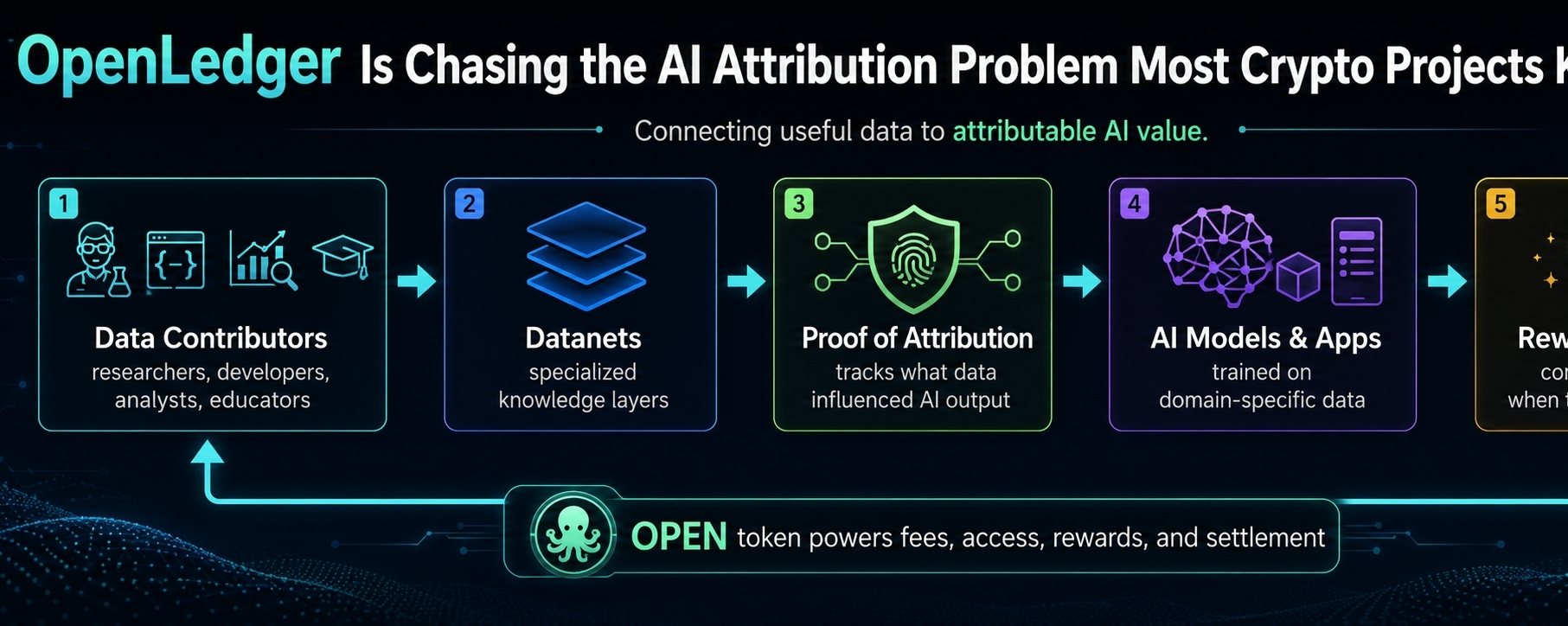
The project is not really trying to win the loudest AI narrative. It is working on something uglier and more useful: attribution. Where did the AI’s intelligence come from? Who gave the data? Who created the knowledge? Who helped the model become better? And if that knowledge creates value later, why does the original contributor usually get nothing?
That is the broken part nobody likes to talk about.
AI does not appear out of nowhere. It feeds on years of human work. Research notes. Code examples. market commentary. educational content. technical documentation. audit reports. on-chain analysis. trading patterns. niche expertise. The sort of material people build slowly, usually through pain, repetition, and mistakes.
Then a model swallows it.
The output looks clean.
The reward goes somewhere else.
I have seen this game before. Different wrapper, same extraction.
OpenLedger is trying to change that loop by making data contribution traceable. If a dataset helps an AI model produce something useful, the system should be able to show that influence and reward the contributor behind it.
Simple sentence. Hard problem.
That is why I do not want to oversell it.
Attribution sounds good when written down. Everyone agrees creators should be paid. Everyone agrees useful data should have value. Everyone agrees AI should be more transparent. Then you get into the actual mechanics and the whole thing becomes messy.
How do you measure which data mattered?
How do you stop garbage contributors from farming rewards?
How do you separate real signal from recycled filler?
What happens when five datasets say the same thing in slightly different words?
What happens when data is useful but legally sensitive?
This is where most projects start to crack.
And honestly, this is where I am watching OpenLedger most closely. Not the slogans. Not the token chart on a random green day. Not the posts saying AI plus crypto is the future for the thousandth time.
I’m looking for the moment this actually works under pressure.
The core idea behind OpenLedger is that AI data should not be treated like disposable fuel. It should be treated like something with memory, ownership, and economic weight. If a person or community contributes knowledge that keeps helping a model, that contribution should not vanish after one upload.
That is the interesting part.
It turns data from a one-time input into something closer to a living asset. Not in the usual empty crypto way where everything becomes an asset because someone minted it. I mean in a practical sense. Useful knowledge keeps producing value. If OpenLedger can track that value, then contributors have a reason to bring better data instead of handing it over to closed systems for free.
That changes the incentive game.
Maybe.
I say maybe because crypto has a bad habit of confusing design with adoption. A system can look clean on paper and still die because nobody uses it. A token can have ten utilities and still trade like pure attention. A marketplace can launch with nice branding and still have no real supply, no real demand, and no reason for serious people to stay.
OpenLedger still has to earn the right to be taken seriously.
The project’s Datanets are where that proof has to show up. The idea is to build focused data networks around specific topics instead of throwing generic information into a giant machine and hoping intelligence comes out the other side.
That matters more than people think.
General AI is already crowded. Brutally crowded. The biggest players have compute, distribution, users, capital, and patience. Most small projects are not going to beat them by pretending to build a smarter general model.
Specialized AI is a different fight.
A model trained on clean smart contract exploit data can be more useful for security than a broad model that vaguely understands Solidity. A trading model trained on real on-chain behavior, liquidity movement, and market structure can be more useful than a chatbot repeating yesterday’s headlines. A legal model with properly sourced jurisdiction-specific material can beat a polished general answer that sounds right and quietly gets things wrong.
Better data beats bigger noise.
That is the bet.
OpenLedger is trying to create the rails where that better data can be contributed, traced, and rewarded. The project wants data creators, model builders, and users connected in one loop instead of sitting in separate rooms while value leaks upward.
I like that idea.
I also know ideas are cheap here.
The grind is execution. Getting high-quality contributors is hard. Keeping them is harder. Making rewards feel fair is harder still. If the people bringing useful data feel like the system is random, delayed, or easy to exploit, they will leave. Good contributors do not stay in broken markets out of loyalty. They go where the value is clearer.
That is the part many people ignore. Data quality is not a technical detail. It is the whole business.
If OpenLedger attracts thin datasets, duplicated content, and low-effort farming, the whole thing becomes another noisy crypto incentive loop. Looks busy. Feels alive. Produces very little.
But if it attracts real domain knowledge, then the project starts becoming more serious.
Smart contract security. On-chain research. education. legal references. market intelligence. technical documentation. These are areas where specialized data actually matters. Not because they sound nice in a pitch deck, but because bad information costs money.
Sometimes a lot of money.
That is why attribution becomes more important as AI moves into heavier use cases. A casual user may not care where an answer came from. They just want something fast. But a business, a developer, a trader, or a researcher will care. They need to know whether the answer came from reliable material or from a pile of recycled internet sludge.
Trust is not decoration there.
It is the product.
OpenLedger is aiming at that trust layer. That is the best way I can describe it. It wants to sit underneath AI systems and give them a record of where knowledge came from, who contributed it, and how rewards should move when that knowledge creates value.
If that works, it is not a small idea.
But here’s the thing.
Markets usually do not price boring infrastructure correctly until the problem becomes painful. Nobody cares about plumbing until the room floods. Attribution may feel boring now because most people are still staring at AI outputs. They are impressed by the answer, the speed, the demo, the agent doing something flashy on screen.
The deeper question comes later.
Can this be trusted?
Can this be audited?
Can this be paid fairly?
Can this system explain itself when something goes wrong?
That is where OpenLedger may find its opening.
The OPEN token sits inside this system as the network asset for fees, rewards, governance, staking, model access, and settlement. That gives it a role. But I am not going to pretend token utility automatically means token demand. We have seen that mistake too many times.
The token matters if the network matters.
That is it.
If Datanets grow, if models use them, if inference creates attribution events, if contributors receive rewards tied to actual usage, then OPEN has a stronger reason to exist. If most of the activity stays speculative, then it becomes just another AI ticker moving with the mood of the market.
No mystery there.
The real test, though, is whether OpenLedger can make attribution feel real to normal builders. Not just to protocol people. Not just to early token holders. Not just to the crowd that already wants to believe.
Can someone bring a valuable dataset and understand how they earn?
Can a developer build a useful model without fighting the system?
Can a user trust that the output has a traceable data trail?
Can the network stop low-quality data from turning rewards into a farm?
Can it show proof without burying everyone in complexity?
That last one matters. Crypto projects love building systems that only the team can explain. Then they wonder why adoption stays thin.
OpenLedger has to avoid that trap.
Its strongest story is actually very human. People create knowledge. AI uses that knowledge. The people should not disappear from the economics.
That is clean.
The system behind it can be complex, but the reason for existing should stay simple.
I do not think OpenLedger needs to be the loudest AI project. Loud projects often burn fastest anyway. What it needs is evidence. Real Datanets. Real usage. Real contributors who are not just farming campaigns. Real model activity. Real attribution that does not feel like marketing language.
That is what I would watch.
Not every partnership.
Not every price spike.
Not every thread calling it hidden gem.
I would watch whether the project can turn attribution from a nice sentence into a working market.
Because if AI keeps growing, the fight over data will get worse. Not better. More models will need better knowledge. More creators will ask why their work is being used without upside. More companies will demand traceability. More users will question outputs that sound confident but have no visible roots.
OpenLedger is standing near that pressure point.
Maybe it becomes important.
Maybe it gets buried under the same grind that kills most ambitious crypto infrastructure.