Most people judge AI by the final answer.I think that misses the more important question: who helped create the intelligence behind that answer?In today’s AI systems, contribution often disappears very quickly. A finance expert may clean a useful market-risk dataset. A researcher may label difficult examples. A domain specialist may remove bad information or organize high-quality documents. That work can improve a model, but once training is finished, the contributor usually becomes invisible.
The model keeps the value.The platform captures the usage.The person who improved the system often gets no clear record. $OPEN #OpenLedger @OpenLedger
That is the practical friction OpenLedger is trying to address.To me, OpenLedger’s real angle is not simply “AI plus blockchain.” That phrase is too broad and has been used too many times. The more serious idea is contribution visibility.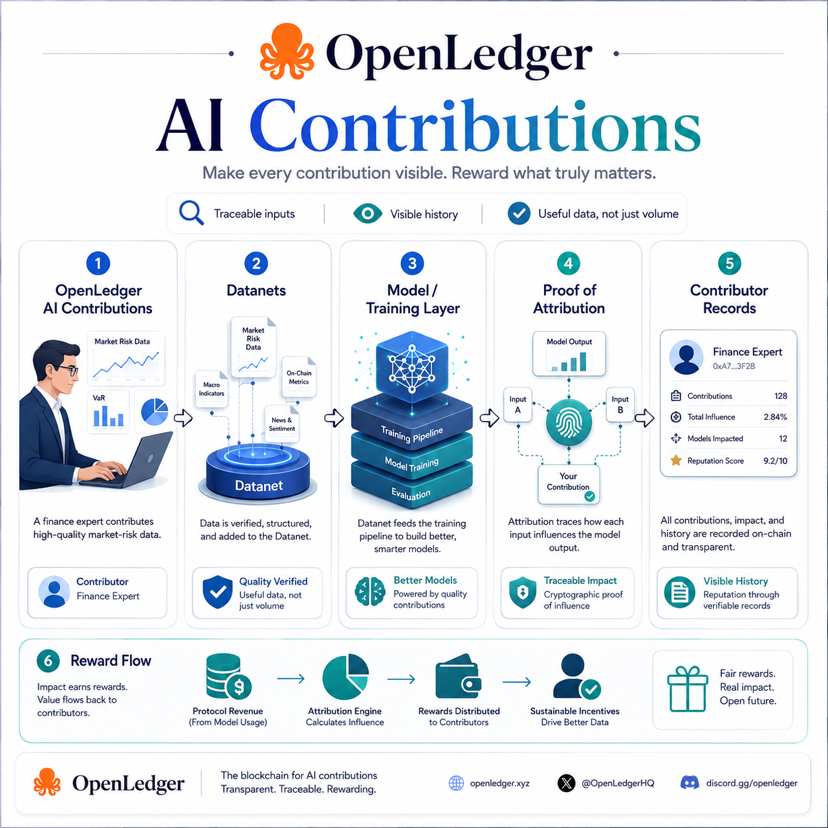
OpenLedger is trying to make AI contribution traceable, attributable, and eventually rewardable. In simple terms, it wants to create a system where the people who add useful data or improve AI models do not disappear into a black box.
The thesis is fairly clear: if AI is going to become a major economic layer, then the inputs behind AI also need better records.
That matters because AI is not built by models alone. It is built from datasets, domain knowledge, training history, feedback loops, and continuous improvement. If all of that stays hidden, then users cannot really understand where the intelligence came from. Contributors cannot prove their role. And reward systems become difficult to trust.
This is where OpenLedger’s design becomes interesting.One part of the system is Datanets. Instead of treating data as one large anonymous pool, Datanets organize contributions around specific domains, topics, or use cases. That matters because AI quality often depends on context. A small but clean finance dataset can be more useful for a market-risk model than a huge pile of random internet text.
Another part is contributor records. If someone uploads data, improves a dataset, or participates in a model-building process, that activity can be recorded. The goal is not just to say “someone contributed.” The goal is to create a clearer history of who added what, when it happened, and how it connects to the system.
Then comes Proof of Attribution. This is the more important layer. OpenLedger is not only trying to record contribution at the upload stage. It is also trying to connect AI outputs and model usage back to the data or contributors that influenced them.That is a difficult problem, but also the problem that matters most.Because contribution is not valuable just because it exists. It becomes valuable when it actually improves the system.
Imagine a finance expert contributes a clean dataset about market-risk signals. The dataset includes useful examples around liquidity stress, credit behavior, volatility patterns, and risk classification. In a normal AI system, that contribution may disappear after training. The model becomes better, but the expert has no easy way to prove that their work helped.
With OpenLedger’s approach, that contribution could leave a visible trail. The dataset could be part of a specific Datanet. The contributor’s activity could be recorded. If a specialized model later uses that Datanet or benefits from it, attribution logs could help show the connection.
That changes the psychology of participation.
People are more likely to contribute useful work when they believe the system can recognize it. Not perfectly, but clearly enough to matter. A data contributor does not want to feel like they are donating value into a machine that forgets them. They want some record that their work existed and had a role.
For crypto, this is an important idea because it moves beyond the usual token narrative.
A lot of crypto-AI projects talk about compute, agents, or decentralized infrastructure. OpenLedger is focusing on a quieter but very real issue: the ownership and visibility of AI inputs. If contribution can be tracked, then rewards can become more connected to usefulness instead of pure speculation.
For users, this could also make AI systems easier to trust. If a model is improved through traceable data sources, users may have more confidence in where the intelligence came from. They may not need to see every technical detail, but the existence of a record matters.
For contributors, the benefit is even clearer. A useful dataset, feedback loop, or domain-specific improvement could become part of a visible contribution history.Over time, that history could become even more valuable than a single one-time upload. It would show that a person or group has been consistently improving AI systems in a specific area.But there’s also a serious risk.Attribution is really hard.If the system measures contributions poorly, the rewards can easily end up going to the wrong people.Someone who uploads a massive but low-quality dataset might look way more important than someone who adds a small but extremely valuable one.Or the system may struggle to separate real influence from simple data volume.
That would create the wrong incentives.Instead of encouraging quality, it could encourage spam. Instead of rewarding useful contributors, it could reward people who learn how to game the attribution system. And if contributors do not trust the reward logic, the whole idea becomes weaker.
There is also a complexity problem.AI attribution is already difficult to understand. If OpenLedger makes the system too technical, normal contributors may not know why they were rewarded or why they were ignored. Transparency only works when people can understand the logic behind it. A system can be fully recorded onchain and still feel confusing if the reward rules are unclear.
That is what I’m watching next.I want to see how OpenLedger explains attribution in practice. Not only in whitepaper language, but in simple contributor terms. How does a user know their data mattered? How are rewards calculated? Can low-quality uploads be filtered out? Can smaller expert datasets compete with larger generic datasets? And can the system remain usable without forcing every contributor to become an attribution expert?
The bigger idea is strong.AI contribution should not be invisible forever. If people help build the intelligence, there should be a better way to show their role. OpenLedger is trying to create that visibility layer through Datanets, contributor records, Proof of Attribution, and reward flow.
But the execution will matter more than the narrative.Because the hard part is not saying that contribution should be rewarded. Most people agree with that. The hard part is proving contribution value accurately enough that users, builders, and contributors can trust the system.
If OpenLedger can do that, it could make AI participation feel more like an economy and less like unpaid background work.
Can OpenLedger make AI contribution visible without making the system too complex? $OPEN #OpenLedger @OpenLedger 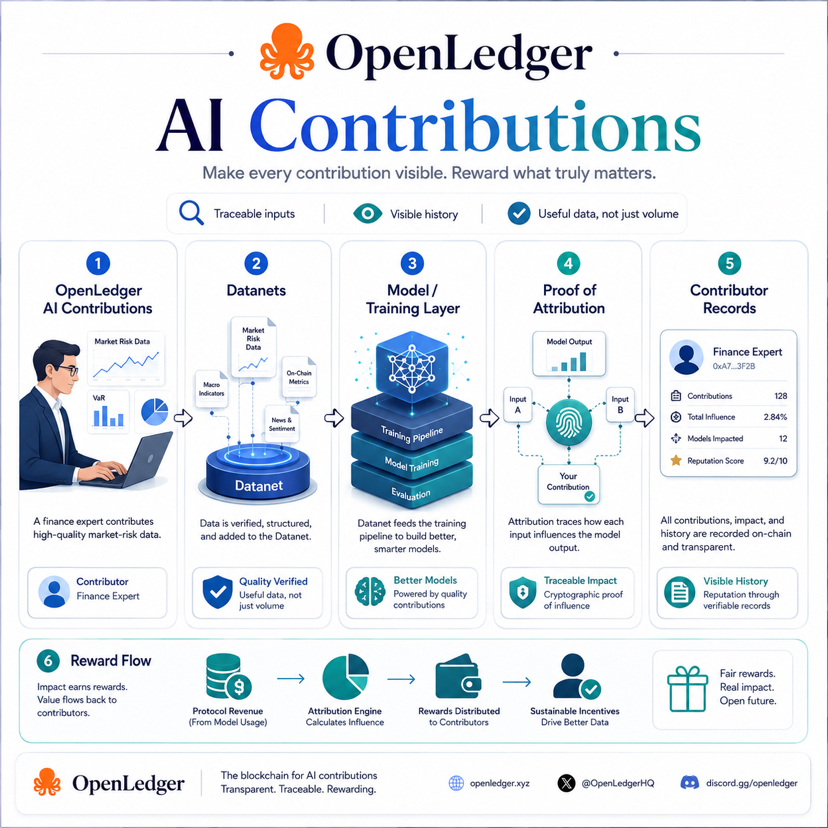
Articol
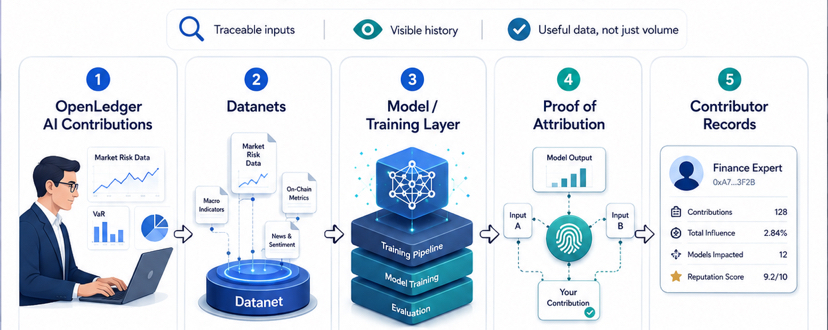
Why OpenLedger Wants AI Contributions to Be Traceable

--
Declinarea răspunderii: Include opinii ale terților. Acesta nu este un sfat financiar. Poate include conținut sponsorizat. Consultați Termenii și condițiile