
Most people reading about OpenLedger's technical architecture absorb the OP Stack detail as a background fact and move on to the more interesting-sounding parts: model tokenization, no-code AI training, the agent platform. I've done that myself. But the longer I spend with the project, the more I believe the L2 decision is actually the founding choice that defines every capability and every constraint OpenLedger carries. It's not a footnote. It's the frame.
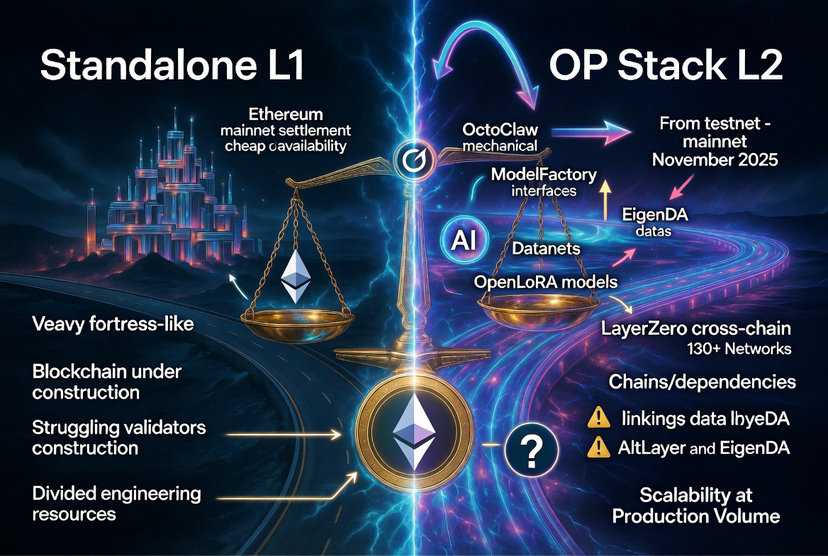
Let me describe what the decision actually entailed. OpenLedger could have launched as a standalone Layer 1 blockchain, building its own validator set, its own consensus mechanism, its own security model from scratch. That path is long, expensive, and risky. It requires convincing enough validators to stake capital and run nodes before the network has product-market fit. It requires maintaining the validator incentive system in parallel with building actual AI products. It requires engineering resources split between two completely different problem domains: core chain security and application-layer product development. The list of L1 projects that chose this path and struggled to do both things well simultaneously is long.
OpenLedger chose OP Stack instead. That's the Optimism framework, a well-tested rollup infrastructure that lets you build an L2 on Ethereum without engineering the consensus layer yourself. Combined with EigenDA for data availability and AltLayer for rollup-as-a-service operations, OpenLedger essentially rented a working blockchain foundation and focused its engineering capacity on the products living on top of it. ModelFactory, Datanets, OpenLoRA, OctoClaw, the contribution tracking system, these are the things that differentiate OpenLedger from every other chain. The OP Stack handles the base layer that doesn't differentiate anything.
The benefits are real and I don't want to undersell them. Ethereum's security model transfers to OpenLedger's L2 through EigenLayer's Active Validated Service framework. That's not a minor inheritance. Ethereum's security is backed by hundreds of billions in staked capital and years of adversarial testing. A new L1 with six months of validator history doesn't have anything close to that. EVM compatibility means every Ethereum developer can deploy on OpenLedger without learning new tooling. Every Ethereum wallet works. Every existing bridge infrastructure works. The migration friction for a developer who already builds on Ethereum is near zero. That matters enormously for building an ecosystem quickly.
EigenDA deserves specific attention because it's doing something structurally important for OpenLedger's use case. Traditional L2s handle data availability by posting transaction data back to Ethereum mainnet, which is the secure and simple approach but costs real money at scale. Every byte costs gas. For a platform where AI data contributions, model training events, inference records, and contributor attribution scores need to be written on-chain frequently and cheaply, Ethereum mainnet data availability pricing would be prohibitive at any meaningful usage volume. EigenDA decouples availability from execution, providing data integrity guarantees at significantly lower cost. The architecture is designed for high-frequency, low-cost data operations, which is exactly what an AI contribution tracking system needs. Sreeram Kannan, the founder of EigenLabs, is also an angel investor in OpenLedger. That's not just a credential; it signals that the people who built the security layer understand what OpenLedger is trying to do with it.
What does the L2 choice cost, though? This is the part that rarely gets acknowledged in any OpenLedger coverage I've read. Building on OP Stack and AltLayer creates a genuine infrastructure dependency. OpenLedger doesn't fully control its own base layer. If AltLayer changes its service terms, its pricing model, or its technical roadmap, OpenLedger's rollup infrastructure is affected in ways the team can't fully prevent unilaterally. If the OP Stack framework introduces a change that conflicts with OpenLedger's specific requirements, adapting may mean engineering work that wasn't planned. These aren't catastrophic risks, and AltLayer has strong incentives to maintain stable relationships with its L2 clients. But they are real dependencies that a standalone L1 would not carry.
The second cost is harder to quantify but more important for the long-term brand story. The "AI Blockchain" tagline implies something foundational and standalone. An L2 is, definitionally, not foundational in the same sense. It settles on Ethereum. It depends on EigenDA for data integrity. It uses AltLayer for rollup operations. OpenLedger is a sophisticated application layer built on top of other people's infrastructure, which is a completely legitimate and common design pattern in 2025 blockchain development, but it creates a gap between the positioning and the technical reality that informed investors notice. Whether that gap matters commercially depends on whether OpenLedger's application-layer products are compelling enough to make the base layer choice irrelevant to users. If Datanets are full of high-quality domain data and ModelFactory is producing models that domain experts actually use, nobody cares what stack the chain runs on.
The LayerZero integration from October 2025 extends the L2 logic into cross-chain territory. Connecting to 130-plus blockchains through LayerZero means assets and data can move between OpenLedger and the rest of the EVM ecosystem without custom bridge engineering. That interoperability comes from the same pattern: use existing infrastructure rather than build it. For a platform where AI models might be trained on data sourced from multiple chains and deployed to serve inference requests from users across ecosystems, cross-chain connectivity isn't optional at scale. The decision to integrate LayerZero before mainnet launched in November 2025 is consistent with the broader infrastructure-first sequencing OpenLedger has followed.
The lesson that other AI blockchain projects should probably take from OpenLedger's L2 decision is this: the time and capital not spent building a validator set and consensus mechanism is time and capital available for building the actual products that users interact with. OpenLedger had a functional mainnet with EVM compatibility, cross-chain connectivity, and Ethereum-grade security before most comparable projects had finished designing their consensus algorithms. That head start is real, even if the dependencies it creates are also real.
What I keep returning to as the fundamental question about this design choice: does the L2 path scale to the vision? OpenLedger's roadmap describes a nine-layer full-stack platform for accountable AI, an AI Marketplace, an IAO system for model tokenization, OpenFin, OctoClaw at production scale. All of that activity settles transactions on Ethereum mainnet through the OP Stack rollup. At very high transaction volumes, rollup sequencing costs and data availability costs both grow. EigenDA is cheaper than mainnet data posting, but it's not free. AltLayer's pricing is a function of throughput. OpenLedger's token economics depend on inference fees and contribution rewards flowing efficiently at scale. Whether the infrastructure can support that scale at acceptable cost is a question the testnet phase, with its incentive-driven rather than organic activity, doesn't fully answer.
That's the L2 decision's final unresolved tension: it was clearly the right choice for getting a credible mainnet live quickly with real security and low migration friction. Whether it remains the right choice when OpenLedger's AI economy is running at full production volume depends on the cost curves of infrastructure providers that OpenLedger doesn't fully control.
@OpenLedger $OPEN #OpenLedger $BSB
