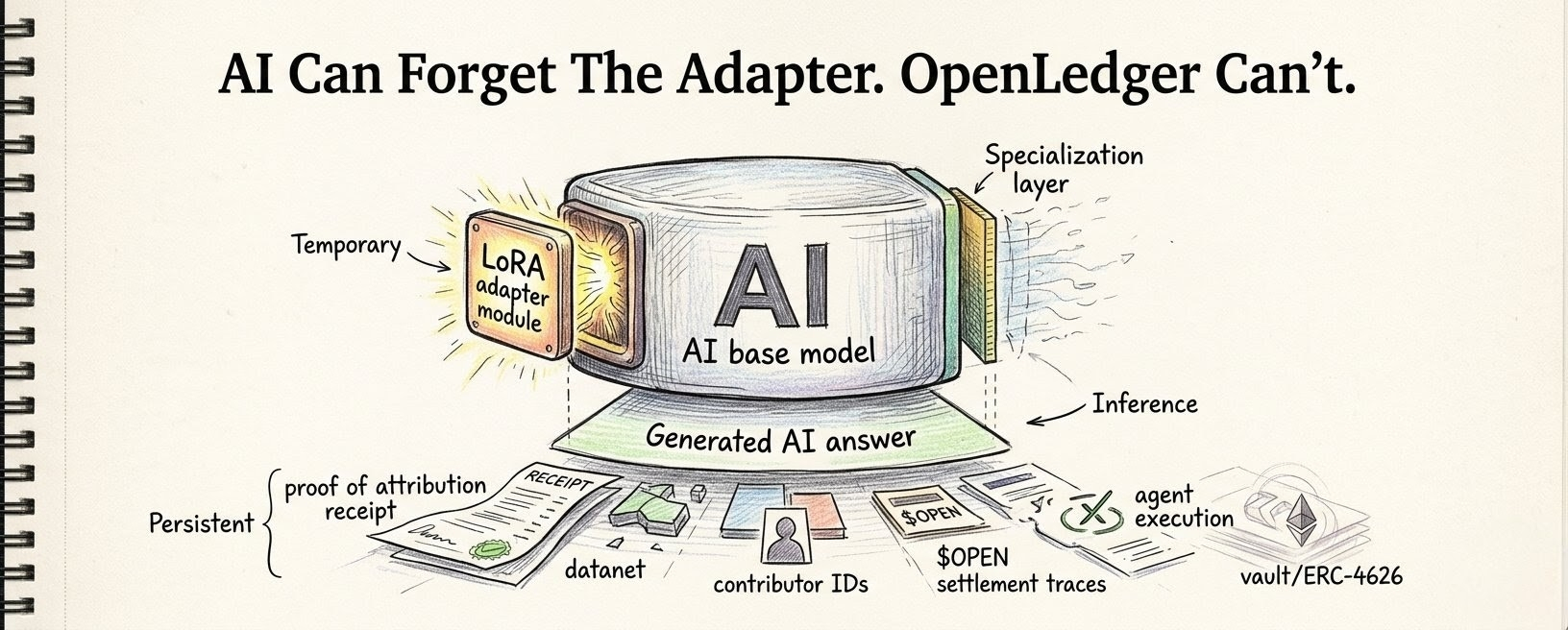

i keep thinking about the moment data stops sitting still inside OpenLedger (@OpenLedger ).
not the upload.
not the clean little record.
not the nice Datanet entry that makes everything look organized from the outside.
the moment after that.
because a openLedger Datanet contribution can look complete too early. it can be tagged, sorted, maybe validated, maybe placed inside some vertical data network where it feels like it has already become part of the AI economy. and maybe it has, technically. but i do not think that is the real turn.
the real turn starts when OpenLedger ModelFactory touches it.
that is where the file starts changing form.
or maybe that is still too clean. maybe the file is still there, still traceable, still part of the Datanet layer, but something else starts happening to it. it gets pulled into a path where data becomes training material, where training material becomes a fine-tune, where a fine-tune becomes a model route, where that route can later answer, earn, fail, or get ignored by actual usage.
so what changed there?
the file? the model? the future output that does not exist yet?
that transition feels heavier than the word “low-code” makes it sound.
because low-code sounds friendly. too friendly maybe. like the whole point is just making model deployment easier for people who do not want to wrestle with infrastructure. and sure, that matters. nobody wants every builder to become a machine learning engineer, infra engineer, dataset cleaner, deployment admin, and chain accountant at the same time.
but inside OpenLedger, ModelFactory feels less like a shortcut and more like a conversion room.
data enters as possibility.
behavior leaves as consequence.
that is the part i keep coming back to OpenLedger, even when the upload looks like the clean moment.
because before ModelFactory, a contribution is still upstream material. it may have a Datanet position, a trace, maybe reputation around it, maybe validation around it, but it has not yet crossed into model behavior. the model has not been changed by it. the output has not carried it. the usage layer has not tested whether it mattered.
and until the model changes, what exactly happened?
that question keeps making the upload feel like the preface, not the event.
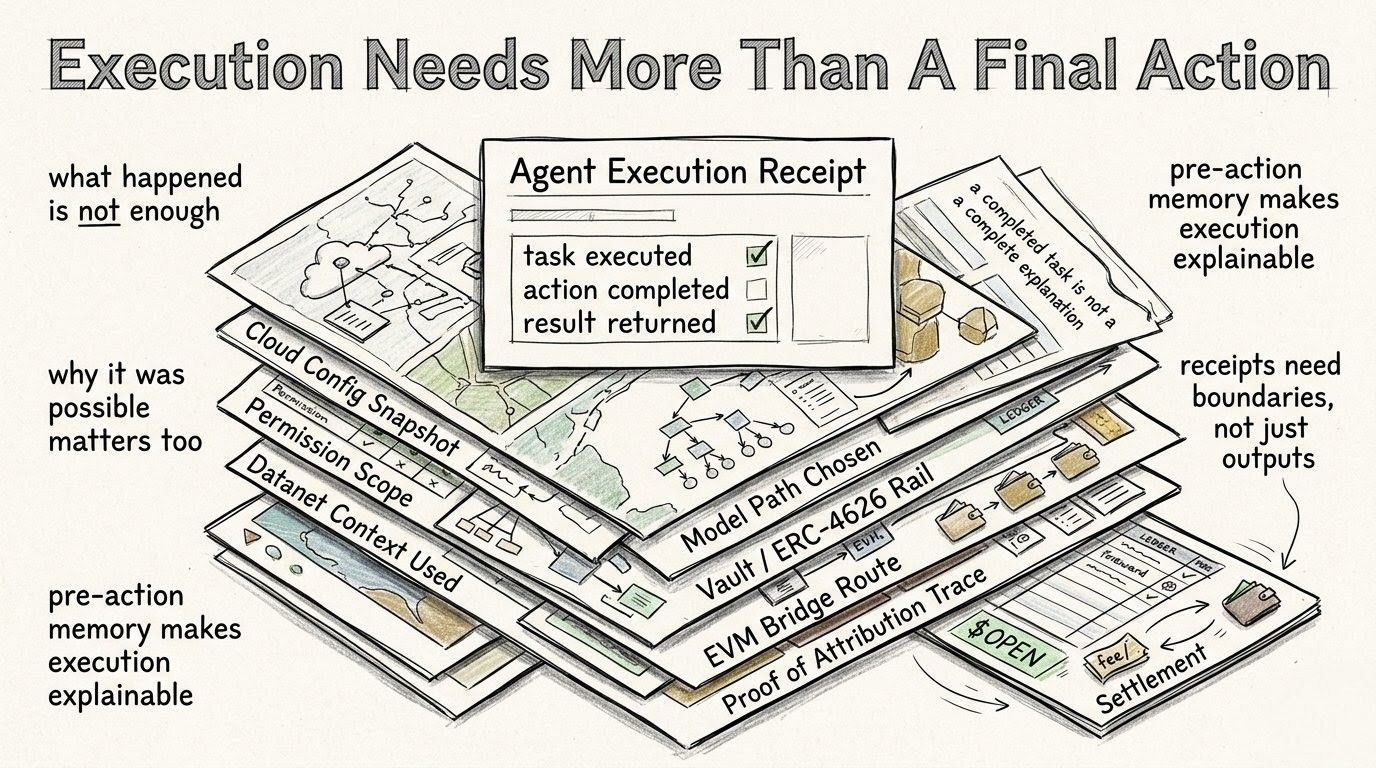
people like to say data is valuable, but that always feels unfinished to me. data is valuable where? for what path? under which model? in what task? did it improve behavior or only increase weight? did it help inference or just make the data layer look fuller than it really is?
inside OpenLedger, ModelFactory is where those fake-clean questions start becoming harder to avoid.
because once Datanet material moves into ModelFactory, it is no longer just sitting as supply. it is being shaped into something a model can use. maybe a fine-tune. maybe a deployable model path. maybe a specialized behavior that later gets served through the compute layer. maybe something that becomes useful enough that a user query pulls it into the real economy.
that is where the data starts carrying risk.
not just value.
risk.
because if the data becomes behavior, then the quality problem does not stay inside the Datanet. the attribution problem does not stay inside the contributor profile. the mistake does not stay upstream. it travels. it gets baked into a model route. it can show up in an answer later with no obvious smell of where it came from.
and that is reason openLedger ModelFactory cannot just be treated like a builder tool.
a builder tool helps someone make something.
ModelFactory changes where responsibility begins.
if approved Datanet material becomes a fine-tune, then the system has to remember what entered. if that fine-tune becomes useful, Proof of Attribution has to know which source helped. if it becomes weak, the OpenLedger system should not pretend the model failed by itself. some upstream material pushed it there. some route carried it. some contributor may have added signal, or noise, or both.
that is messy.
but AI is messy once you stop staring only at the final answer.
i keep thinking about a builder using ModelFactory to turn a narrow dataset into a model path. maybe it is DeFi code. maybe wallet behavior. maybe legal text. maybe medical imagery. whatever. the vertical does not matter as much as the route. the Datanet gives the supply. ModelFactory gives the place where supply becomes behavior. OpenLoRA may later make specialized serving cheaper. Proof of Attribution tries to remember the parts that mattered. OpenLedger sits around the usage, reward, fee, or settlement layer when that behavior becomes economically relevant.
but the dangerous temptation is to flatten all of that into “deploy a model.”
that phrase hides too much.
deploy what?
a model shaped by which Datanet?
trained or tuned through which path?
carrying which contributor influence?
ready for which user demand?
and if usage happens later, who actually earned?
on openLedger ModelFactory makes these questions practical. not philosophical. because once the model exists, the argument changes. the contributor is no longer only saying, i uploaded something that might matter. the system can start asking whether it entered behavior. whether it got used. whether it shaped output. whether the model path carried it into demand.
a contribution is not the same thing as influence.
that difference feels like the whole OpenLedger problem hiding in plain sight.
old AI made the conversion invisible. data disappeared into training, training disappeared into behavior, behavior disappeared into product, product turned into revenue, and everyone upstream got erased unless the platform wanted to tell a nice story later. the model looked like it created intelligence from itself. very clean. very convenient. also very fake.
OpenLedger is trying to make that conversion less silent.
and ModelFactory is one of the places where silence would be most dangerous.
because easier model creation means more model paths. more fine-tunes. more specialized behavior. more chances for Datanet material to move from passive supply into active intelligence. that sounds exciting until you ask what happens when all those new model paths start producing value.
who tracks the ancestry?
who knows which Datanet helped?
who sees whether the model became useful because of one dense source, or many small sources, or some contributor who kept adding boring but valuable corrections?
who gets paid when the output earns?
and maybe worse: who gets less trust if the behavior turns out weak?
that is where ModelFactory starts feeling like pressure.
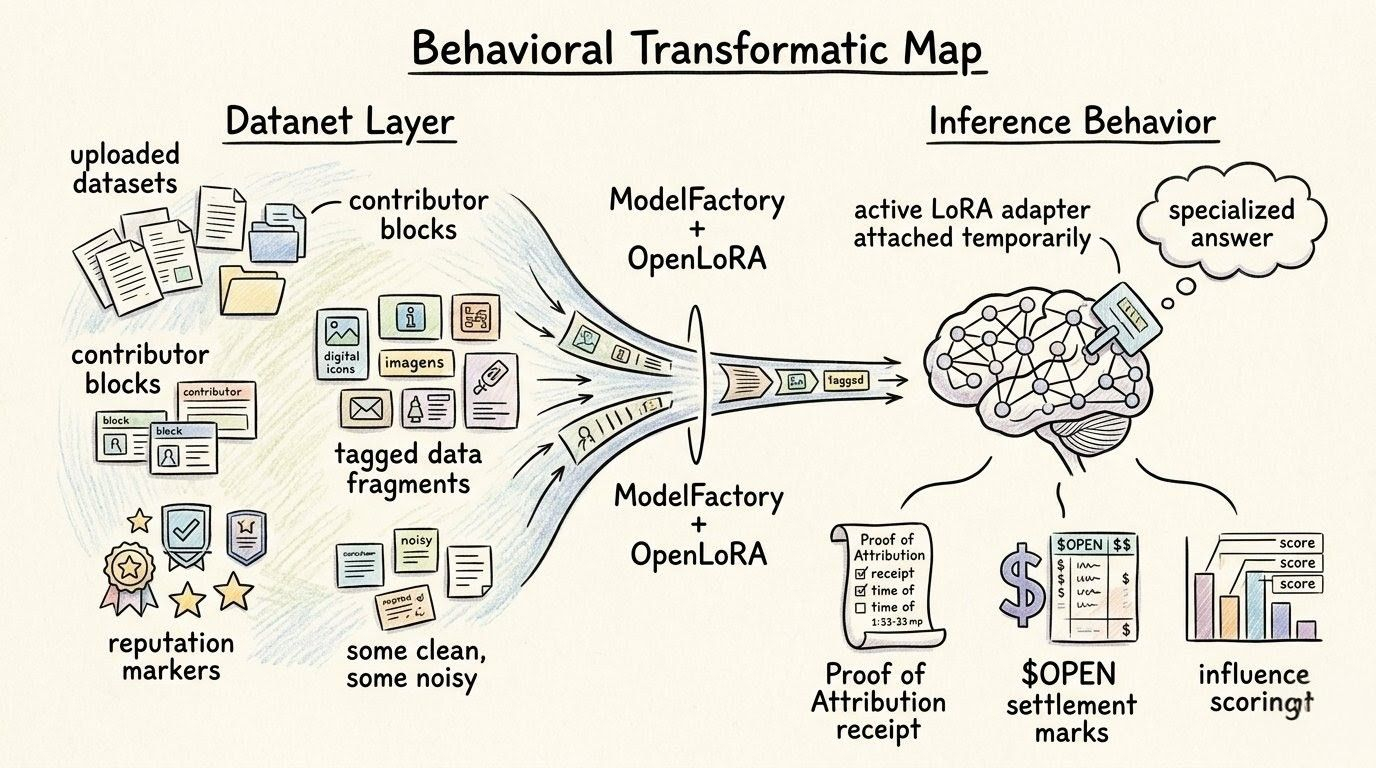
not pressure in the dramatic way. more like the pressure of making the system honest. if anyone can deploy or shape models more easily, then attribution cannot be lazy. otherwise OpenLedger would just make AI creation easier while repeating the old problem at higher speed.
faster forgetting.
that would be ugly.
so ModelFactory cannot just produce models. it has to produce traceable model paths. that is the part i keep coming back to. the model that comes out should not feel like a clean object with no past. it should carry its route. Datanet source, fine-tuning path, contributor influence, compute usage, later inference demand. all the annoying residue that centralized AI usually scrubs away because clean products sell better than honest ones.
but OpenLedger is not supposed to make AI feel cleaner.
it is supposed to make the mess count.
and maybe that is why the “factory” word is weirdly useful. a factory is not magic. inputs enter. process happens. output leaves. if the output breaks, you do not just blame the shiny thing at the end. you inspect the line. raw material. machine. timing. quality control. route. everything.
OpenLedger needs that kind of boring accountability exactly at the conversion layer.
especially if the output is going to become payable.
because once a model path starts generating usage,OpenLedger ( $OPEN ) cannot just move because a model exists. it has to move because measurable use happened. because some path carried value. because Proof of Attribution can say which parts deserve weight. the payment trail should not reward the finished model like the Datanet route, fine-tune path, and compute work vanished before usage.
the model has a past.
that past should not be free.
but it also should not be overpaid just because it exists. that is the hard part. ModelFactory turns data into behavior, but behavior still has to meet usage. a fine-tuned model sitting unused is not the same as a fine-tuned model that keeps getting called because it solves a real task. a beautiful model path with no demand is still potential wearing better clothes.
so maybe ModelFactory is not the end of data monetization.
maybe it is the middle.
Datanets supply the material. ModelFactory changes its form. inference later tests whether anyone cared. Proof of Attribution remembers the route. OpenLedger only makes sense when usage becomes economic.
that route is not clean, but it feels honest. and it keeps the thought from becoming the lazy story where OpenLedger just “lets people build AI models.” that is too small. the surface version is easy model deployment. the deeper OpenLedger version is deployable behavior with provenance still attached.
because without that, ModelFactory would almost be dangerous.
not because tools are bad. because tools accelerate whatever structure sits under them. if the attribution layer is weak, easier model deployment just creates more places to hide influence. if the input trail is weak, ModelFactory can turn unclear origin into model behavior faster. if usage accounting is weak, valuable model paths can earn without knowing who actually helped them become valuable.
speed without memory is just faster forgetting.
that line keeps sitting there.
ModelFactory makes one part of AI creation easier, and that is exactly why the trace around it has to get stricter. more models, more routes, more fine-tunes, more outputs that look clean from the outside. but the more paths there are, the easier it becomes to lose origin unless the system is built to keep origin attached.
and if the origin gets lost right there, then where does it come back?
or does it never come back at all?
OpenLedger’s ModelFactory becomes interesting because it sits exactly where that blur usually begins.
the moment data becomes behavior.
the moment the system could either remember the path or start lying like everyone else.
and if it remembers, then the model is not just a product. it is a record of what shaped it. not in a boring archival way only. in an economic way. a Datanet contribution can matter later because it entered a model path. a model creator can earn because they shaped useful behavior. compute can be accounted for because the inference had to be served. OpenLedger can move because usage becomes something billable, rewardable, or worth settling.
that feels less magical.
good.
magic is usually where someone is not getting paid.
i do not think users will care about this directly. they will ask a model for something, use an agent, maybe consume an output, maybe never ask which Datanet sat behind it or how ModelFactory shaped the route. normal. people do not stare at factory floors when they buy the product.
but the system has to care.
because if ModelFactory is where data becomes behavior, then that is where OpenLedger’s promise gets tested in a very specific way. not at the slogan level. not at the upload level. at the conversion level.
did the system remember what entered?
did it remember what changed?
did it remember who helped?
did it remember enough to pay later?
inside OpenLedger (#OpenLedger ), ModelFactory is not just the place where builders avoid infrastructure headaches. it is the place where data stops being a quiet file in a Datanet and starts becoming something that can answer, earn, fail, and leave a trace.
that is the part i keep staring at.
because once Datanet material becomes model behavior, the output has an upstream route whether the user sees it or not.