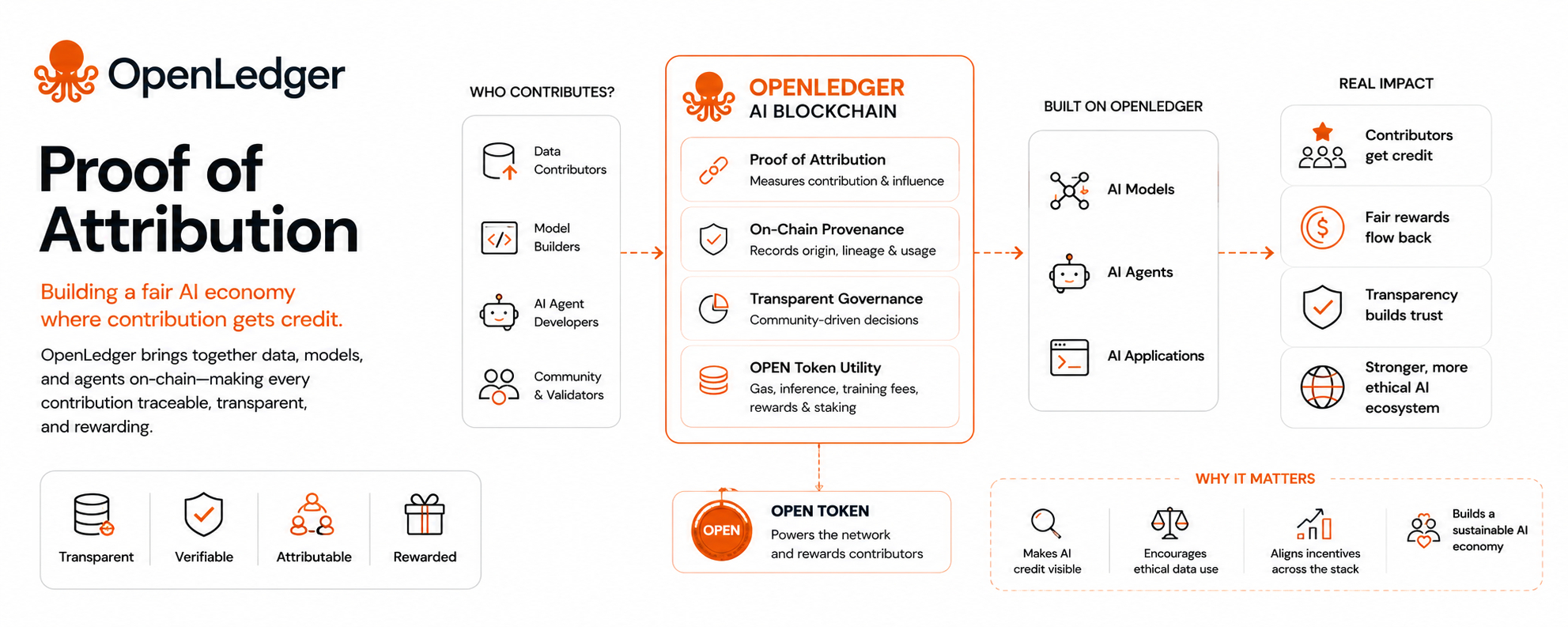
A lot of the noise around AI credit comes from a simple truth that is easy to say and hard to fix: these systems are built on other people’s work, but the trail gets blurry very fast. Data is gathered, models are trained, outputs are produced, and the people and datasets that made the whole thing possible usually disappear from view. OpenLedger is trying to address that gap with something it calls Proof of Attribution, a system meant to trace contribution, make it visible, and attach reward to it inside an AI blockchain built around data, models, and agents.
The idea makes sense on first reading because the problem it is trying to solve is real. NIST has said that provenance and attribution can help transparency and accountability in AI, especially when it comes to understanding how training data shapes model behavior. But NIST also makes the limit plain: provenance is useful, not magical. It helps explain origins and responsibility, yet it does not by itself solve every legal, ethical, or technical issue around AI systems.
That distinction matters. There is a big difference between knowing something came from somewhere and being able to say exactly what part of it mattered, by how much, and to whom value should flow. OpenLedger’s own documentation leans into the practical side of the problem. It describes a network where data uploads, training, governance, and rewards all sit inside the same system, with the OPEN token used for gas, inference, model-building fees, and contributor rewards. In other words, the project is not just talking about fairness in the abstract. It is trying to make attribution part of the machinery itself.
That is the part of the pitch that feels genuinely interesting. AI has spent years becoming better at producing results and worse at explaining where those results come from. The more capable the system gets, the more the credit gets flattened into one invisible bundle. OpenLedger is trying to push back against that by making contribution auditable. Its paper says Proof of Attribution is designed to measure data influence and support transparent reward allocation, and it also acknowledges that the technical problem is hard enough that different attribution methods are needed for smaller and larger models.
That last part is important, because it keeps the whole thing from sounding too neat. The paper does not pretend attribution is simple. It uses approximation methods and token-level techniques because large language models are not the kind of thing you can dissect with a clean, obvious formula. That is probably the most honest sign that the project understands the problem it is tackling. It is not claiming to uncover some pure original source of an AI answer. It is trying to estimate contribution in a system where contribution is usually spread across many layers.
And that is where the real question starts to sharpen. Could proof-of-attribution actually solve AI’s credit problem, or does it mostly help us feel like we are closer to solving it?
The answer is probably somewhere in between. It can absolutely make AI credit easier to talk about, because it turns a vague complaint into something trackable. It gives the industry a way to say, this dataset mattered, this inference was influenced, this contributor should be visible, this reward should flow here. That is not nothing. In a field where credit is often implied rather than recorded, making the chain visible is already a meaningful step.
But visibility is not the same thing as justice. A system can be traceable and still be incomplete. It can be better documented and still miss the deeper issue. The Data Provenance Initiative found that dataset documentation across the AI ecosystem is uneven, and that many important categories of data — including lower-resource languages and newer synthetic data — are concentrated in closed collections. That means the starting point is already messy. Any attribution system built on top of that has to reconstruct a history that was never fully written down in the first place.
That is why the strongest version of the argument for Proof of Attribution is not that it solves everything, but that it creates an infrastructure for something the AI world has always struggled with: remembering where value came from. If a model is useful because of data, and that data can be traced, then there is at least a fairer path to compensation. If a community contributes material that improves a system, that contribution should not vanish the moment the model starts producing results. OpenLedger’s whole design is built around that instinct.
Still, there are limits that no amount of blockchain language can smooth over. Attribution in AI is not like tracking a file download. Model behavior comes from combinations of data, architecture, training choices, tuning, prompt context, and sometimes retrieval systems layered on top. By the time an output appears, the influence is usually too mixed to reduce to one clean answer. That is why the field keeps returning to approximations. It is also why proof-of-attribution should be treated as a useful system for estimation and reward, not as a final proof of authorship in any absolute sense.
So the honest verdict is this: proof-of-attribution can help AI take credit more seriously, but it probably cannot solve the credit problem all by itself. It can make contribution visible. It can make reward distribution more structured. It can make the origins of model behavior easier to discuss without hand-waving. But it cannot erase the fact that many AI systems were built from data that was poorly documented, unevenly governed, and often impossible to assign clean ownership to after the fact.
That is not a disappointing answer. It is just a real one. Most useful systems in AI do not arrive as final solutions. They arrive as better habits. Proof of Attribution may be one of those: not a complete answer to the question of credit, but a serious attempt to make the question harder to ignore. And in a field that has spent years moving fast while leaving attribution behind, that alone is worth paying attention to.