
Ori de câte ori mă gândesc la unde AI este de fapt deficitar, tot revin la aceeași întrebare incomodă.
Cine de fapt deține ceea ce învață AI?
Și cu cât stau mai mult cu această întrebare…. cu atât îmi dau seama că majoritatea oamenilor din acest spațiu încă se uită la problema greșită.
Toată lumea vorbește despre care model este mai deștept. Care blockchain este mai rapid. Care protocol oferă randamente mai mari. Dar lucrul pe care nimeni nu-l întreabă suficient de tare este…. când AI se antrenează pe datele tale, pe scrisul tău, pe munca ta creativă…. unde ajunge recompensa ta?
Practic, nicăieri.
Aceasta este ceea ce numesc Vidul de Atribuire. Și ar putea fi cea mai mare scurgere tăcută din întreaga economie AI în acest moment.

Acum lasă-mă să explic de ce @OpenLedger mă face să mă opresc și să gândesc serios aici...
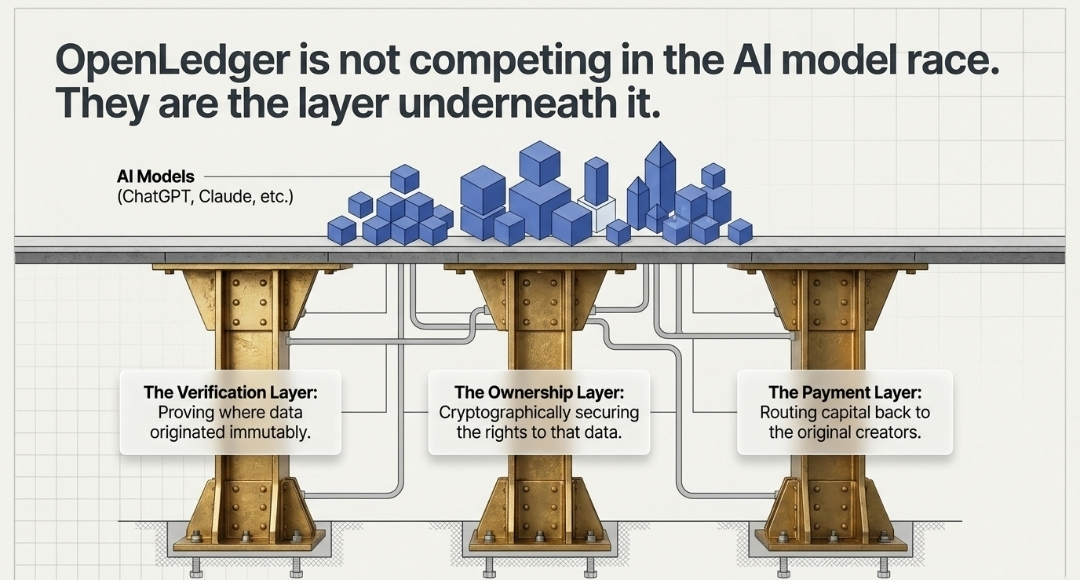
Pentru că nu urmăresc cursa strălucitoare a modelului AI. Merg un strat mai profund. Construiesc infrastructura care decide cine primește credit, cine este plătit și cine este ignorat atunci când inteligența artificială generează valoare.
Lasă-mă să o descompun în felul meu...
Prima este Problema Proprietății Datelor.
Cheltuielile globale în AI depășesc deja 375 miliarde de dolari și continuă să crească. Dar persoanele ale căror date, creativitate și cunoștințe au antrenat de fapt acele sisteme? Ele nu văd aproape nimic din asta. Conducta care transformă contribuția umană în capacitate AI nu are nicio cale de plată atașată. OpenLedger spune practic... că această conductă trebuie reconstruită de la zero.
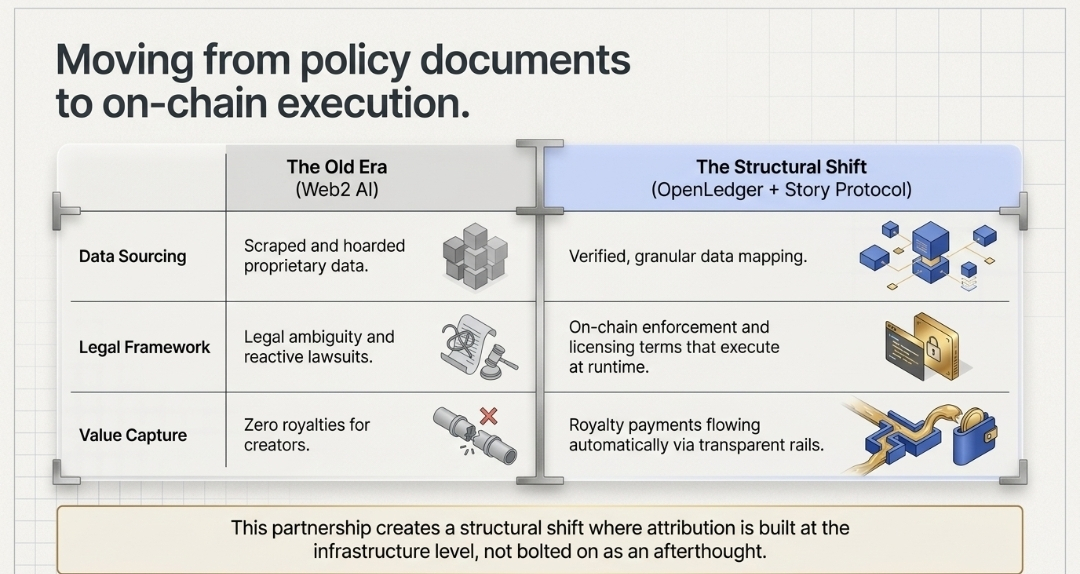
A doua este sfârșitul erei "Antrenează acum, dă în judecată mai târziu."
Asta m-a lovit puternic. Companiile AI au operat ani de zile pe date extrase și ambiguitate legală. Procesele legate de datele de antrenament AI au explodat până în 2025. Instanțele, reglatorii, Actul AI al UE... toată lumea a început să pună aceeași întrebare odată. De unde a învățat acest model? OpenLedger a făcut echipă cu Story Protocol pentru a răspunde acestei întrebări la nivel de infrastructură. Nu cu un document de politici, ci cu aplicare pe blockchain. Termeni de licențiere care se execută în timpul rulării. Plăți de redevențe care curg automat când munca ta contribuie la un output AI. Asta nu este o caracteristică... este o schimbare structurală.
A treia este Sistemul de Atribuire Infini gram.
Aici devine tehnic interesant. Cele mai multe instrumente de atribuire sunt aproximări grosiere. Dar sistemul Infini gram al OpenLedger urmărește influența datelor la un nivel granular. Fiecare contribuție este urmărită, fiecare output este mapat înapoi la originile sale. Asta este o problemă reală de știință a calculatoarelor... și rezolvarea ei pe blockchain o face și mai greu. Dacă reușesc să facă asta curat, implicațiile depășesc cu mult crypto.
A patra este Datanets ca Inteligență Comunitară.
Ideea aici este silențioasă, dar puternică. În loc ca o companie să acumuleze date de antrenament proprietare, comunitățile construiesc împreună seturi de date specifice domeniului. Contribuitorii din domeniul sănătății construiesc rețele de date de sănătate. Contribuitorii legali construiesc rețele de date legale. Fiecare este deținut de cei care l-au construit, nu de platforma de deasupra. Aceasta nu este o idee mică. Aceasta este o provocare directă la modul în care funcționează în prezent întreaga economie de date AI.
Cea de-a cincea este Direcția OpenFin.
În martie 2026, OpenLedger a dat de înțeles ceva numit OpenFin... descris ca aducând DeFAI mai aproape. Detaliile sunt încă rare, dar semnalul este interesant. Dacă reușesc să fuzioneze infrastructura de finanțare descentralizată cu stratul lor existent de atribuire AI, imaginea utilității token-ului se schimbă dramatic. Nu mai este doar o poveste de infrastructură de date, ci devine o poveste de execuție și flux de capital.
Acum să ajung la ce se întâmplă cu adevărat în capul meu...
OpenLedger nu concurează cu ChatGPT sau orice model AI. Ei construiesc stratul de dedesubt. Strat de verificare. Strat de plată. Strat de proprietate.
Și, sincer? Această încadrare este fie incredibil de timpurie... fie incredibil de importantă. Poate ambele.
Pentru că întrebarea despre cine deține ce învață AI nu dispare. Regulatorii o învăluie. Creatorii sunt frustrați de ea. Investitorii încep să o prețuiască. Iar gap-ul de 500 miliarde de dolari în infrastructura de date la care analiștii continuă să se uite... nu se umple singur cu hype. Se umple cu infrastructura reală.
Există ceva ce tot observ la cum OpenLedger își framează povestea.
Ei nu spun "AI te va îmbogăți." Ei spun "AI ar trebui să te compenseze." Și oamenii se conectează cu această încadrare foarte diferit. Pentru că nu este o promisiune de câștiguri noi... este o cerință pentru creditul existent.
În final, sentimentul mixt este încă acolo...
Problema este reală. Abordarea infrastructurii este serioasă. Parteneriatele sunt concrete.
Dar gap-ul dintre "asta e important" și "asta se execută perfect" este încă deschis.
Și acest gap este exact locul unde fiecare proiect semnificativ devine fie o fundație, fie o notă de subsol.
Observ cu atenție. Nu sunt complet convins. Nici nu merită să fie ignorat.
Pentru că cea mai subestimată problemă în AI în acest moment nu este puterea de calcul sau mărimea modelului.
Este întrebarea despre cine este plătit atunci când inteligența devine infrastructură economică.
