
上个月,一个做独立游戏的朋友在电话那头几乎要揪头发了。他正试着把自己那款小众解谜游戏本地化成七八种语言,预算薄得跟纸一样,根本不敢去碰商业翻译API的报价单,只好自己扒来几个开源模型硬着头皮上。他原本以为这事儿挺简单:模型下载下来,部署上去,前端调一下API就齐活了。结果一脚踩进去才发现,每部署一个语言模型,GPU显存就被恶狠狠地啃掉一大块,七八个模型根本没办法同时在一台机器上喘气。最后他只能手动来回切,每次要用哪个语言就临时加载哪个,慢到连他自己都不想用自家产品。
“我就纳了闷了,”他嗓子眼儿里压着一股气,“这些模型加起来一天也就被调个几十次,犯得着给每个都单独配一台服务器吗?为什么不能像拼车一样,大家屁股挨屁股共用一辆?”

撂下电话,我转身就把@OpenLedger 白皮书里专门掰扯OpenLoRA的那些段落重新翻了出来——第3.2节,以及第2.3.4节一路到第2.3.9节。说实话,这片区域在整份白皮书里算是最偏工程实现的,读着有点像一本压紧了的技术手册,公式也密密麻麻地蹲在那儿,非技术背景的人很容易就一眼扫过去了。可你要是肯耐着性子一点一点啃下来,会发现它翻来覆去在讲的,恰恰就是把我朋友那颗牙给硌疼了的那粒沙子——怎么让一千个、几百个、哪怕只是几十个小模型,在同一张GPU上同时活着,而且要做到随叫随到,像训练有素的侍者,不是堵在走廊里推推搡搡的旅客。
白皮书第2.3.4节给OpenLoRA焊下了一块清晰的定义:它是OpenLedger生态里一个多租户的LoRA模型服务框架,专门让一茬一茬的专用模型能在上面同时撒开腿跑,互不绊脚,调用的时候响应还特别利索。
关键词就藏在那三个字里:多租户。这词在云计算那摊子里早就被翻烂了,意思是多个用户共享同一套物理资源,但每个人都被一层看不见的膜轻轻隔开,觉得自己独享着一整台轰鸣的服务器。OpenLoRA把这个念头一把拽到了AI模型服务上:一个预训练的“底座模型”先稳稳当当地加载好,把那块GPU的主力显存给占了,然后几百个微调出来的LoRA适配器——你权且可以把它们想象成一个个轻飘飘的、拆装自如的“技能包”——动态加载,谁来叫谁,用完就轻手轻脚地放掉,不占着茅坑。

第2.3.5节亮出了他们攥在手里的一件叫“分段收集矩阵向量乘法”的技术,缩写叫SGMV。你不用费神去记这个名字有多拗口,你只需要攥住一件事就够了:它让好几个完全不同的LoRA模型可以搅在一口锅里同时处理请求,而不是举着号码牌排成一条长队,一个干完了才轮到下一个。这在操作上到底意味着什么?它意味着一个正埋头审查葡萄牙语合同的模型,和一个正绷着神经分析稀土价格趋势的模型,可以在完全同一刹那被人叫醒,底层趴在完全同一块GPU上跑,却谁也不会拖着谁的脚后跟。
接着第2.3.7节把动态加载的帘子撩开了。白皮书里的描摹是,OpenLoRA不会蠢到把几百个模型全须全尾地预先塞满显存,真要那么干,显存早就被撑得连一声惨叫都发不出来。它走的是“即时加载”的路子——有人推门叫了,系统才把那个模型的适配器从存储里头轻手轻脚捞出来,搁到GPU上,跑完推理,然后一秒钟都不多留,立刻释放。冷启动那一丁点儿时间,被压缩到了人几乎察觉不到的缝隙里。
再往后,第2.3.8节和第2.3.9节,调度和负载均衡这两个干脏活的齿轮才露了面。白皮书摆出来一个分配公式,大概的意思是,每一个新请求扑进来,系统都会自己抬头扫一圈,判断哪块GPU肚里还有足够的内存和喘气的算力,然后才把请求稳稳塞过去。要是某块GPU的内存眼看就要顶到天花板了,系统还会把那些暂时不赶趟的请求悄悄挪到别处去,同时死命保住那些已经算到半截的中间状态,让整个过程不会像被拔了电源一样戛然中断。
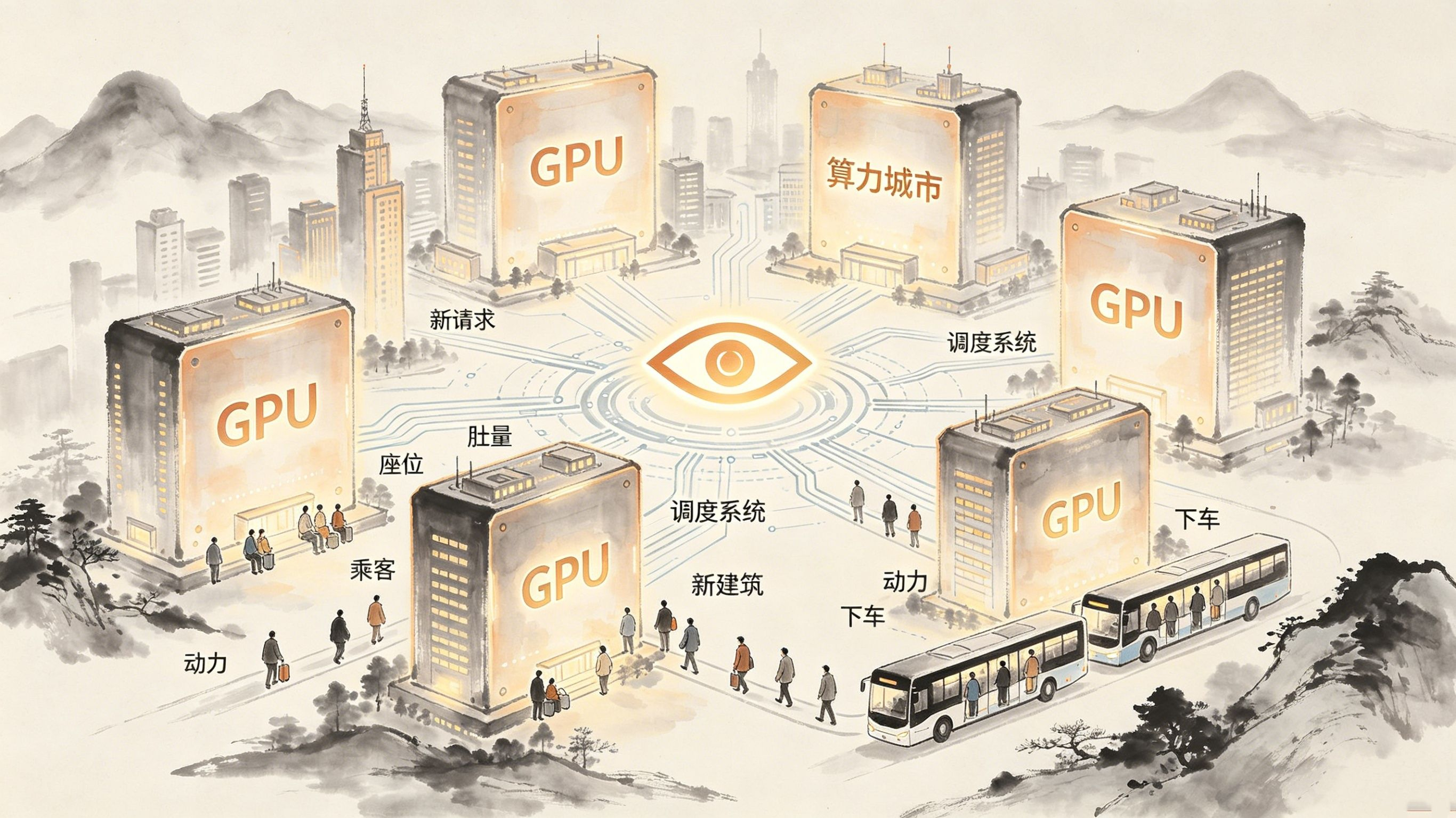
这些技术细节零零碎碎地拼到一块儿,拼出来的图景,跟我朋友那个吭哧吭哧手动切模型的狼狈夜晚,完全是两个世界:几百个专用模型,像晚高峰拼车的乘客一样肩并肩共享着同一台滚烫的发动机,随时悄没声地上车,又悄没声地下车,彼此连衣角都不擦一下,每个人只付自己那一段路的票钱。
这个“拼车”的比喻,恰好就是代币机制嵌得最深的那个榫卯。
第5.2.4节有一句我们已经快背下来的话:“每次AI模型被用于推理,其计算都通过 $OPEN 代币来支付。”如果每个模型都得独占一整张显卡,那这笔支付在商业上根本就跑不通,因为单次调用的那点碎银子,可能连GPU在那儿空转着耗掉的电费都兜不住。可一旦套进OpenLoRA这套共享架构里,推理调用的颗粒度就被碾到了极致——一个模型一天被调十次,另一个三次,还有一个只在凌晨被不知道哪儿飘来的请求轻轻啄了那么两下。每一次调用,都是一笔细如发丝的微支付,自动在链上清掉,不需任何一双人手去拨算盘。共享的技术架构,把单次服务的成本踩到地板;代币的微支付机制,又让这些碎片到不成样子的调用,在商业上能颤颤巍巍地站住脚。这两只手,是互相撑着才握紧的。
OpenLedger白皮书第2.2.4节躺着的那个推理费计算公式,在这一刻忽然显得格外沉甸甸。它把费用拆得明明白白——输入token费、输出token费、平台费,精确到每一千个token为一口。为什么非得算这么细?因为在共享GPU的场子里,调用之间的差异能拉得比峡谷还宽:有的模型每次只嚼几十个token的短查询,像抿了一口水;有的模型一张嘴就吞进去几千个token的长文本,像灌了一整锅汤。要是不按真实的消耗去打算盘,共享立刻就会变味,变成一种不公平的补贴,勤快的人替懒人摊了本钱。代币结算那细到骨子里的粒度,正是共享架构在经济上能不散架的绝对前提。
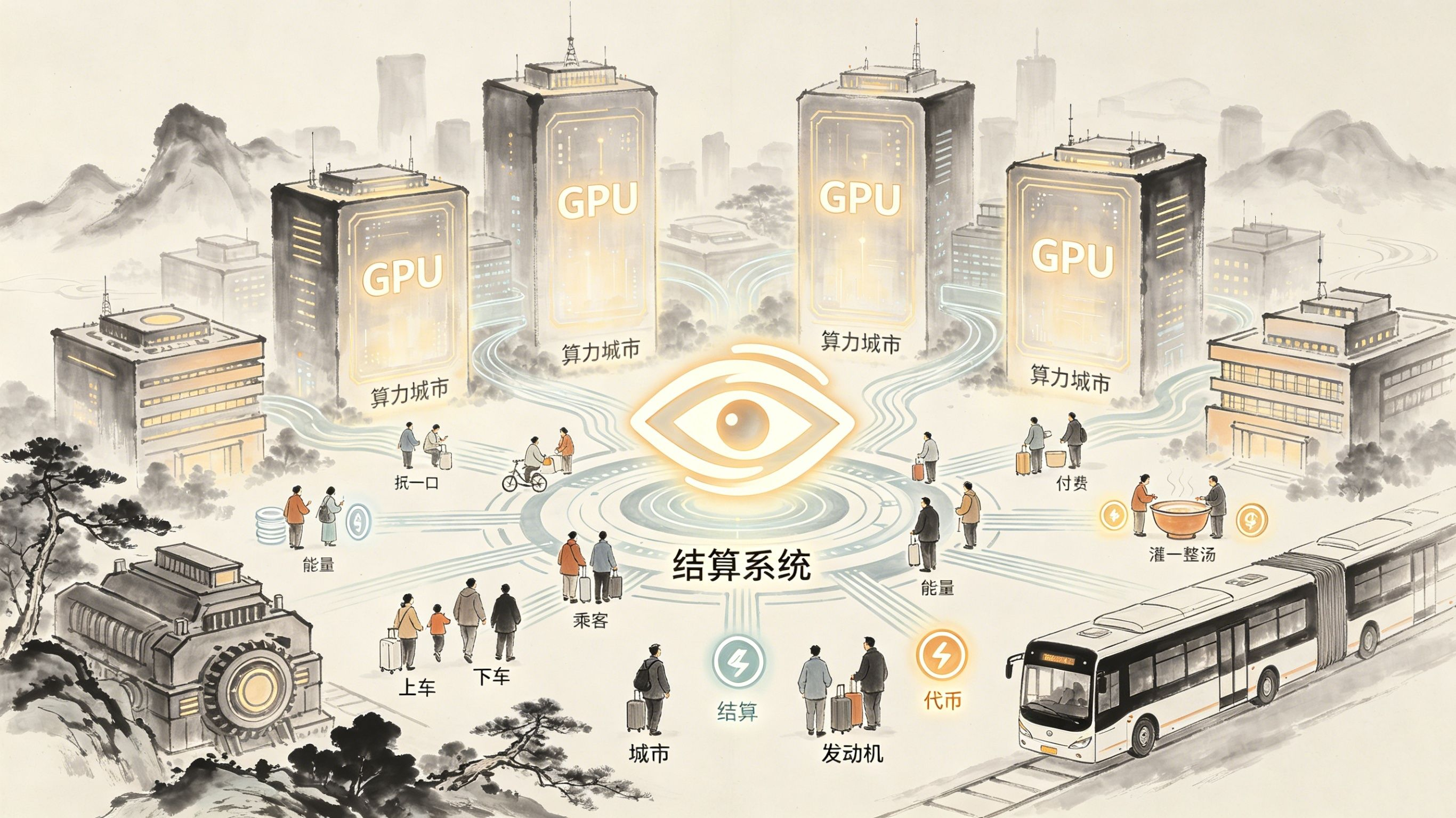
这个角度,让我忍不住把 #OpenLedger 整个项目的价值锚点又从头掂了一遍。之前我花了大量笔墨去拆它的归因机制、掰它的治理设计、追它的飞轮模型,那些切入的口子,多是绕着“公平”“透明”“激励”这些偏理念层的东西在打转。可OpenLoRA这一整套东西,它只讲一件事,讲“效率”,讲那种最质朴的经济学意义上的效率——用更瘦的资源,喂饱更多的人。
这让我对那个在之前几篇文章里反复浮出来透气的问题——“专用模型到底能不能持续活下去”——忽然摸到了一块新的拼图。专用模型能不能在商业上站住脚,不光看它需求够不够肥、数据够不够硬,还得看它那身运营的骨头,能不能被削到足够轻。如果一个专用模型必须像一座孤独的灯塔一样独占一整块GPU,那它活下来的门槛就高得硌脚——你必须每天都有足够密集的调用量,才能勉力盖过成本。可一旦专用模型可以挨挨挤挤地共享同一口锅里的火,活下来的门槛就断崖一样塌下去了。一个一天只被叫醒十来次的模型,只要它交出去的那份推理费,能把被它嚼掉的计算资源盖住,它就能喘着气,活下去。
OpenLoRA递过来的,正是那道断崖式的塌落。它让“小众但有用”从一句黏在墙上的情怀口号,塌缩成了一道可以拿笔来算的商业公式。
当然,脑袋该冷的地方还是得冷。共享架构的效率能飙到多高,很大程度上得看调度那颗大脑够不够聪明。要是调度算法不够鸡贼,把一筐子都张着血盆大口要显存的请求,一股脑儿全塞到同一块GPU上,那共享立马就淤成了一锅谁也动不了的泥粥。白皮书第2.3.8节点到了调度策略,可具体的调度算法,和那些能拿数字甩在桌上的性能数据,还没展开。这是一个得靠真实环境下跑出来的数据去硬碰硬验证的点,不是白皮书里写得干净利落,就一定能不折不扣做到的。
另外,共享架构虽然把单次调用的成本压得极低,可它也偷偷伸出一只手,向整个系统索要足够高的总调用量,才能把GPU的利用率喂饱。要是链上生态还是一片没醒透的冻土,调用量本来就稀稀拉拉,那再聪明的调度,也填不满一块GPU当中那些空荡荡的闲暇。这皮球又滚回了我们之前掰扯过好几次的冷启动老问题。

不过,这一回把OpenLoRA的章节重新逐字逐句啃过一遍,我最大的感觉反而不是技术层面的,而是一种在设计哲学上被轻轻戳了一下的触动。这个行业里,有太多项目把嗓子吊高了去唱那些宏大叙事,在画飞轮,在烙大饼,可OpenLoRA蹲在角落里,只是在绞尽脑汁去解一个非常具体、非常沾地气的小题:怎么让一千个小模型,挤在同一张卡上却不彼此拳打脚踢,而且每一个都傻傻地觉得自己住的是单间。
这让我又想起那个做独立游戏的朋友。他的翻译服务器最后是怎么从泥淖里爬出来的?他在网上刨了很久,翻出来一个开源的多模型服务框架,做了好一通适配,总算把七八个语言模型安安稳稳地撂在了同一台机器上。他后来在电话里乐呵呵地跟我说,弄完那天他掐指一算,省下来的服务器租金,比他给这款游戏画的所有预期收入还多。我笑了笑,没接茬,也没告诉他,他那天满头大汗捅破窗户纸才摸到的那条路,跟那份被我翻来覆去圈圈点点、画满笔记的白皮书里某几个章节,其实讲的是完全同一件事。